数据库结构设计核心要点:从概念到物理实现全解析
数据库结构设计是系统开发的关键环节,涵盖概念、逻辑与物理三个层次。本文提炼核心知识点与常见题型,帮助你快速掌握设计流程与优化技巧,无论备考还是实战都能事半功倍。
️ 概念设计:构建独立于DBMS的抽象模型
概念设计是数据库设计的核心环节,它通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型。这一阶段的目标是定义数据范围、获取信息模型、描述属性特征与数据间关系,并明确数据约束与安全性要求。
✅ 依据与结果:概念设计以需求分析结果(如需求说明书、DFD图)为依据,最终输出概念模型(ER图)与概念设计说明书。
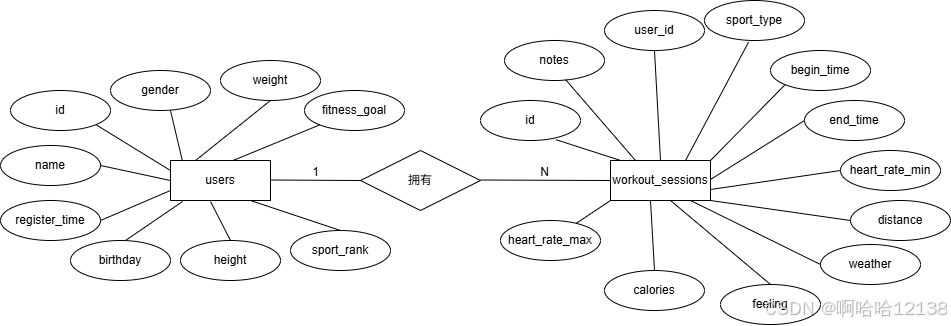
✅ 核心方法:实体-联系模型(ER模型)认为世界由实体和联系构成。实体是基本对象,实体集是同型实体的集合,属性描述实体特征(域为取值范围),码(主码)唯一标识实体。联系分为1:1、1:n和m:n三种类型。
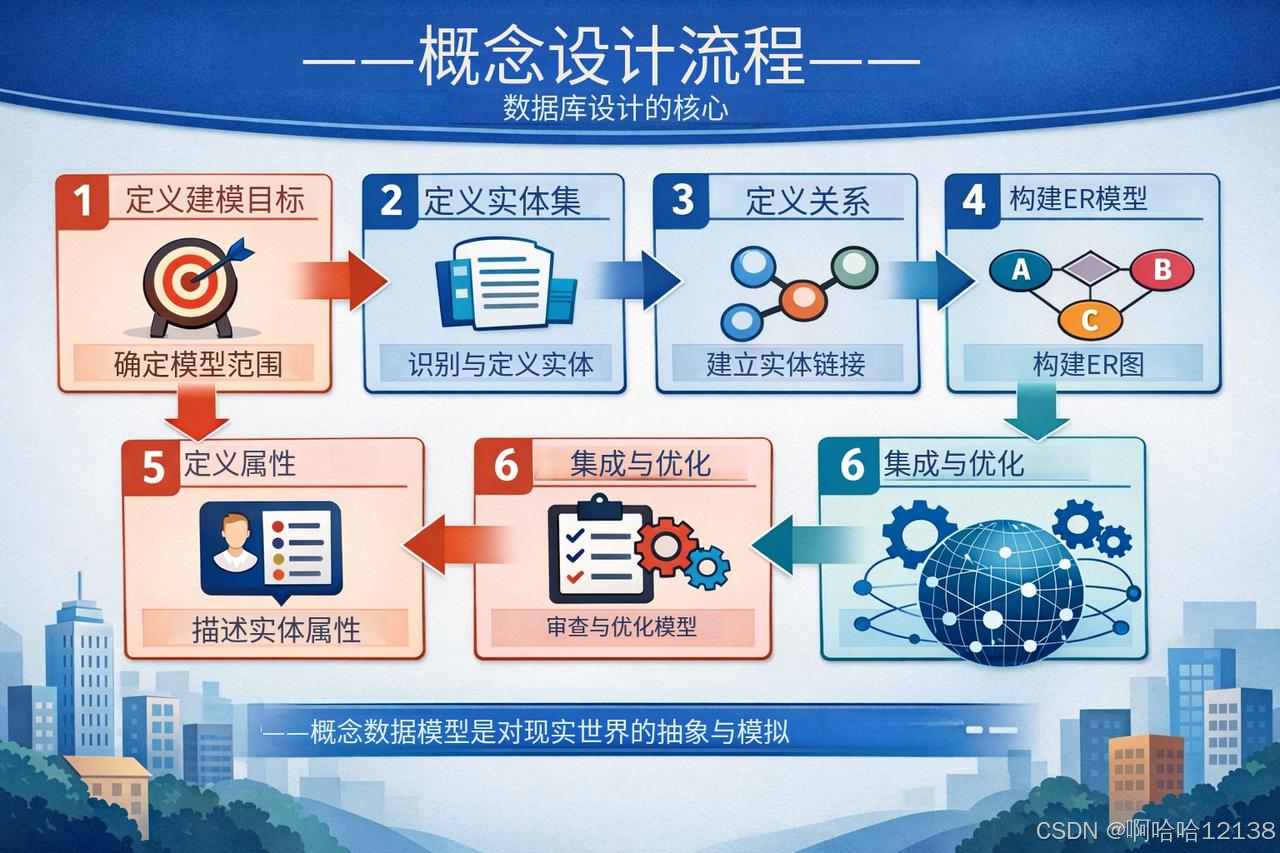
逻辑设计:将ER模型转化为关系模型
逻辑设计的任务是将概念模型(ER图)转化为DBMS支持的数据模型(如关系模型)。关系模型使用二维表格结构表示实体及联系,由五元组R(U, D, DOM, F)构成,可简化为R<U, F>。
关键概念:
- 数据依赖:属性间约束关系,如函数依赖(X→Y)和多值依赖。
- 函数依赖(FD):X确定后Y唯一确定。非平凡依赖指Y不属于X;完全函数依赖需两个或多个属性决定一个属性;传递函数依赖如学号→系名→系主任。
- 码与规范化:候选码、主码、外码。规范化工具包括1NF(属性不可再分)、2NF(非主属性完全依赖主码)、3NF(非主属性不传递依赖主码),以及BCNF、4NF。
✅ 转换规则:一个实体转为一个关系;1:1联系可独立或融入任一端;1:n联系可独立或与n端融合;m:n联系必转为一个独立关系;多元联系也独立转换。
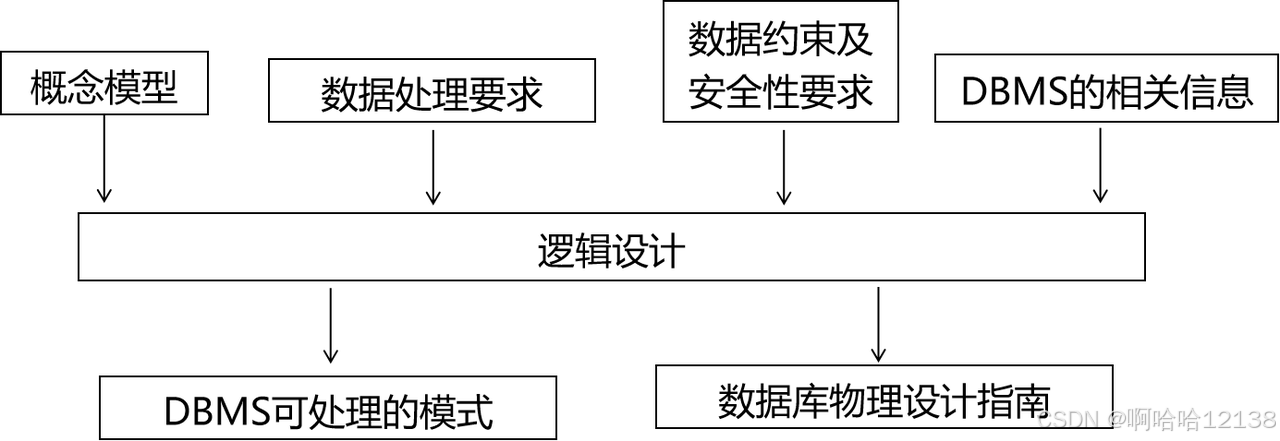
⚙️ 物理设计:优化存储结构与存取效率
物理设计关注数据库的存储结构和物理实现方法,涉及文件组织、文件结构、文件存取和索引技术。索引是快速数据访问的关键,分为有序索引(聚集/非聚集、稠密/稀疏、主/辅索引)和散列索引(基于哈希)。
物理设计环节:
- 逻辑模式描述:将关系模式转换为基本表和视图,利用完整性机制(如触发器)设计业务规则。SQL Server采用T-SQL语言。
- 文件组织与存取:使用事务-基本表交叉引用矩阵分析访问特性,选择堆文件、顺序文件、聚集文件、索引文件或散列文件。
- 数据分布设计:将应用数据、索引、日志、备份等合理分布在不同介质中。
- 系统配置:调整用户数、缓冲区长度、锁数目等参数。
- 物理模式评估:从存取时间、存储空间、维护代价评估,必要时返回逻辑设计阶段修改。
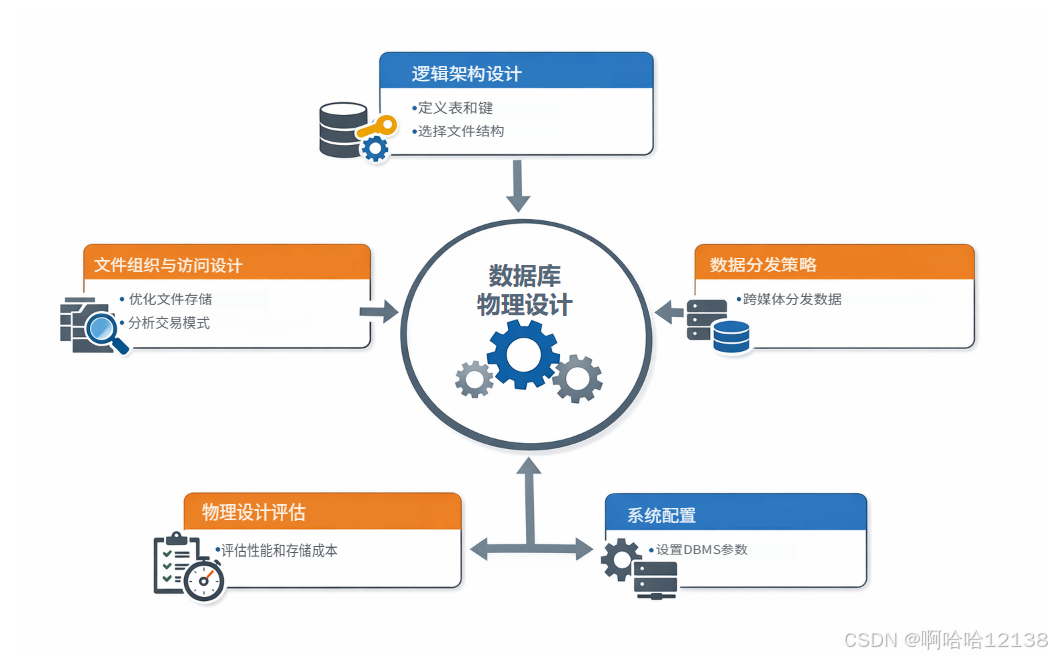
索引与文件结构优化策略
建立索引的原则:常用在操作条件、连接条件或聚集函数中的属性应建索引。聚集索引适合排序、分组、大量数据检索或重复值较大的列。
✅ 文件结构选择:数据量小、频繁更新、整表扫描为主的小表适合堆文件;散列文件适合关键字随机存取,但不支持顺序存取。
提高事务吞吐率:
- 尽量使用行级锁(粒度小,减少冲突)。
- 降低事务隔离性级别(增强并发)。
- 使用RAID1或RAID10(条带+镜像)提升磁盘性能。
- 避免合并小事务,否则增加单个事务执行时间。
⚠️ 避免死锁:按同一顺序访问资源、采用小事务模式、使用行级锁而非表级锁。
[AFFILIATE_SLOT_1]️ 题型总结与高频考点
以下是常见填空题与选择题的核心知识点:
- 聚集索引:数据记录与索引项排列顺序一致,一个数据文件只能建一个。
- 索引分类:SQL Server中有序索引和哈希索引两大类。
- IDEF1X建模:独立实体集用矩形框,从属实体集用圆角矩形框。
- 逻辑设计:将ER模型转换为DBMS支持的数据模型。
- 稠密索引:每个查找码值对应一个索引记录。
- 实体完整性:主码不能为空。
- 视图:提供逻辑数据独立性。
- 非聚集索引结构:由索引列的值和对应指针构成。
- 堆文件:适合数据量小、频繁更新、整表扫描的场景。
- 吞吐量:单位时间内完成的数据库事务数量。
- 1NF:关系模式至少要满足第一范式。
- 规范化程度:如W(C,P,S,G,T,R)函数依赖集F={C→G, (S,C)→G, (T,R)→C, (T,P)→R, (T,S)→R},W最高达1NF;分解后W1可达4NF,W2为1NF,W3为3NF。
函数依赖集 :
C→G
(S,C)→G
(T,R)→C
(T,P)→R
(T,S)→R
候选键 :(T,S)
(T,S) ──→ R ──→ C ──→ G
│
└──→ (T,P) ──→ R
C→G 是部分函数依赖(C 是候选键 (T,S) 的一部分),违反 2NF。
因此,W 最高为 1NF。
W2不存在部分函数依赖,传递依赖,多值依赖达到最高4NF。
W3不存在部分函数依赖和传递依赖,但是存在多值函数依赖,达到3NF。复习题目与解析
一、填空题
- 在衡量数据库应用系统的性能指标中,吞吐量(Throughput)指的是系统在单位时间内可以完成的数据库事务数量。
- 如果数据文件中数据记录排列顺序与索引文件中索引项的排列顺序一致,则此种索引被称为聚集(或聚簇)索引。
- 关系数据库中要求关系的主码不能为空,这属于数据完整性约束中的实体完整性约束。
二、单选题
- 下列关于数据库索引的说法,错误的是( C )
解析:非聚集索引的索引项排列顺序与数据文件记录排列顺序不一致,聚集索引才一致。 - 下列措施中,不能提高数据库事务吞吐率的是( D )
解析:合并小事务会增加单个事务执行时间,反而降低吞吐率。 - 下列关于RAID10的说法,正确的是( B )
解析:RAID10是RAID0(条带)和RAID1(镜像)的组合。 - 下列SQL约束中,应用于列级约束的是( B )
解析:NOT NULL应用于列级;UNIQUE、FOREIGN KEY、PRIMARY KEY应用于关系级别;CHECK应用于元组级别。 - 如果一个基本表的数据量很小,查询以整表扫描为主,且频繁执行更新操作,其最佳文件组织方式是( B )
解析:堆文件无需建立索引,维护代价低,适合频繁更新、整表扫描的小表。
三、判断题
- 散列文件的优点是可以进行顺序存取,且插入、删除操作方便,节省存储空间。( 错误 )
解析:散列文件不能进行顺序存取,只能按关键字随机存取。 - 为避免死锁,应尽量使用表级别的锁,少用记录级别的锁(行锁),缩短事务占有锁的时间。( 错误 )
解析:应尽量使用行级锁,少用表级锁,表级锁粒度大,易产生锁冲突。
总结
数据库结构设计从概念模型出发,经过逻辑转换到物理实现,每个阶段都需权衡时间效率与空间利用率。掌握ER建模、规范化理论、索引优化和文件组织策略,是高效备考与实战的关键。希望本文的系统梳理能助你轻松应对考试与项目挑战!