本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
本文 的 原文 地址
尼恩说在前面
在45岁老架构师尼恩的读者交流群(50+人)里,最近不少小伙伴拿到了阿里、滴滴、极兔、有赞、希音、百度、字节、网易、美团这些一线大厂的面试入场券,恭喜各位!
前两天就有个小伙伴面腾讯, 问到 “ 听说过Harness Agent 吗?你们怎么实现 Harness Agent 的? ”的场景题 ,小伙伴没有一点概念,导致面试挂了。
小伙伴 没有看过系统化的 答案,回答也不全面 ,so, 面试官不满意 , 面试挂了。
小伙伴找尼恩复盘, 求助尼恩。
通过这个 文章, 这里 尼恩给大家做一下 系统化、体系化的梳理,写一个系列的文章组成 尼恩编著 《Harness 架构与源码 学习圣经》 深入剖析 Harness AI 平台级 架构的 架构思维与 核心源码,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
同时,也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典PDF》V176版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
尼恩编著 《Harness 架构与源码 学习圣经》
第一章: 什么是 Harness架构?2026年AI核心范式解析 : Harness架构与Agent工程化
具体文章: 54k+Star 爆火!AI 框架 新王者 Harness Agent 来了!尼恩 来一次Harness穿透式解读
第二章: Harness架构 与 LangChain、LangGraph 三者联动 的底层逻辑
具体文章: Harness架构 与 LangChain、LangGraph 三者联动 的底层逻辑
第三章: DeerFlow 源码 14层Middleware 源码解析 ,又一个 “洋葱责任链模式” 架构思维 的 经典案例
具体文章: DeerFlow 源码 14层Middleware 源码解析 ,又一个 “洋葱责任链模式” 架构思维 的 经典案例
第四章: LangChain 超底层 四大设计模式 Design Patterns ,架构师 的 必备 内功,毒打面试官
具体文章: LangChain 超底层 四大设计模式 Design Patterns ,架构师 的 必备 内功,毒打面试官
第五章:Harness宏观架构:基于 PPAF 思维 & REPL 思维,完成 Lead-Agent和Sub-Agent深度拆解
具体文章: 第五章:Harness宏观架构:基于 PPAF 思维 & REPL 思维,完成 Lead-Agent和Sub-Agent深度拆解
第六章:Harness宏观架构:DeerFlow 2.0 断点续跑机制 架构设计与实现
具体文章: Harness宏观架构:DeerFlow 2.0 断点续跑机制 架构设计与实现
第七章: Harness 平台实战: 用 DeerFlow 构建 一个企业自己的 Manus 平台( 企业长任务智能体平台)
具体文章: Harness 平台实战: 用 DeerFlow 构建 一个企业自己的 Manus 平台( 企业长任务智能体平台)
第八章: Harness 超牛逼的 三级记忆架构 上下文+历史分层+事实列表 ! 落地价值 逆天!!
具体文章: Harness 超牛逼的 三级记忆架构 上下文+历史分层+事实列表 ! 落地价值 逆天!!
第九章: Harness 顶级架构:DeerFlow 2.0 沙盒 Sandbox 架构设计、Sandbox 源码深度解析(史上最深 、价值 逆天)
具体文章: Harness 顶级架构:DeerFlow 2.0 沙盒 Sandbox 架构设计、Sandbox 源码深度解析(史上最深 、价值 逆天)
第10章: 顶奢RAG架构之, 必不可少的 RAG评估体系:7大核心指标落地优化,让RAG从Demo走向生产
【RAG评估、RAG度量指标】顶奢RAG架构之, 必不可少的 RAG评估体系:7大核心指标落地优化,让RAG从Demo走向生产 full - 技术自由圈
第11章:Harness架构 : DeerFlow 2.0 的 lead_agent 任务总调度 架构设计与实现解析
本文
第13章: 深度解析字节跳动DeerFlow 2.0:基于LangGraph的生产级Super Agent驾驭层实现
具体文章: 尼恩还在写, 本周发布
第14章: 基于 PPAF 思维,完成 与 Harness 工程化的 Lead-Agent 和 Sub-Agent 深度拆解.
具体文章: 尼恩还在写, 本周发布
第15章:Harness架构 核心一:断点续跑机制 的 架构设计 与底层源码分析 .
具体文章: 尼恩还在写, 本周发布
第16章:Harness架构 核心二: XXX
具体文章: 尼恩还在写,后续发布
估计有 10章以上,具体请关注技术自由圈。

DeerFlow 2.0 的 lead_agent 任务总调度 架构设计与实现解析
最近字节开源的 DeerFlow 2.0 火得有点离谱。很多人跑通 Demo、换个 Prompt 就急着往业务里塞。
只有 真正看懂 lead_agent 模块的狠劲。自己搭的 Agent 系统,迟早会退化成一堆 if-else 的面条代码。。。
说实话,如果你没扒过它的底层调度逻辑,做不好 任务总调度。
它根本不是什么“聊天入口”。
它是一套极其克制的任务总调度中枢。
今天不聊虚的,我们直接切进核心代码。
看看它是怎么把责任链模式、配置驱动思维和任务编排哲学,严丝合缝地揉进 LangGraph 骨架里的。顺便对标一下微软 AutoGen AG2 最新的架构演进,你会发现,行业对 Agent 运行时(Agent Runtime)的解法,正在收敛。
一、lead_agent “入口” 足够薄
先放个结论。
DeerFlow 2.0 的整体分层,跟 AG2 近期主推的 Agent Router -> Middleware Pipeline -> Sandboxed Executors 思路高度同频。
AG2 强调“智能体编排与工具沙箱的物理隔离”,DeerFlow 则把 lead_agent 抽成唯一流量入口。
lead_agent 模块就是这条流水线的总闸, 是入口。
它不干具体的活儿: 不写具体代码,也不负责查资料,它只管接活、派活、盯进度、收结果。
lead_agent 主要的职责是:接收请求 -> 解析配置 -> 挂载中间件 -> 组装策略 -> 调度子智能体。
就这几步。干净得让人意外。 lead_agent “入口” 足够薄 。
为什么这么设计?
因为复杂智能体系统最怕的就是“横切关注点污染”。
你加个缓存、改个限流、接个审计日志,结果主流程代码肿得没法看。
改一处,牵动全身。
DeerFlow 的解法很古典,也很有效:模块化拆分 + 责任链拦截。
听着像教科书套话?我当初也觉得是。但当我看到 _build_middlewares 里那 12 个中间件按严格业务优先级排队时,我懂了。
这就是架构师的“洁癖”。
字节跳动把 DeerFlow 2.0 开源出来,底层用 LangGraph 搭了一套模块化多智能体系统,核心目标就一个: 把语言模型和网页搜索、代码执行、数据爬取这些硬工具揉在一起,跑出一条自动化研究流水线。
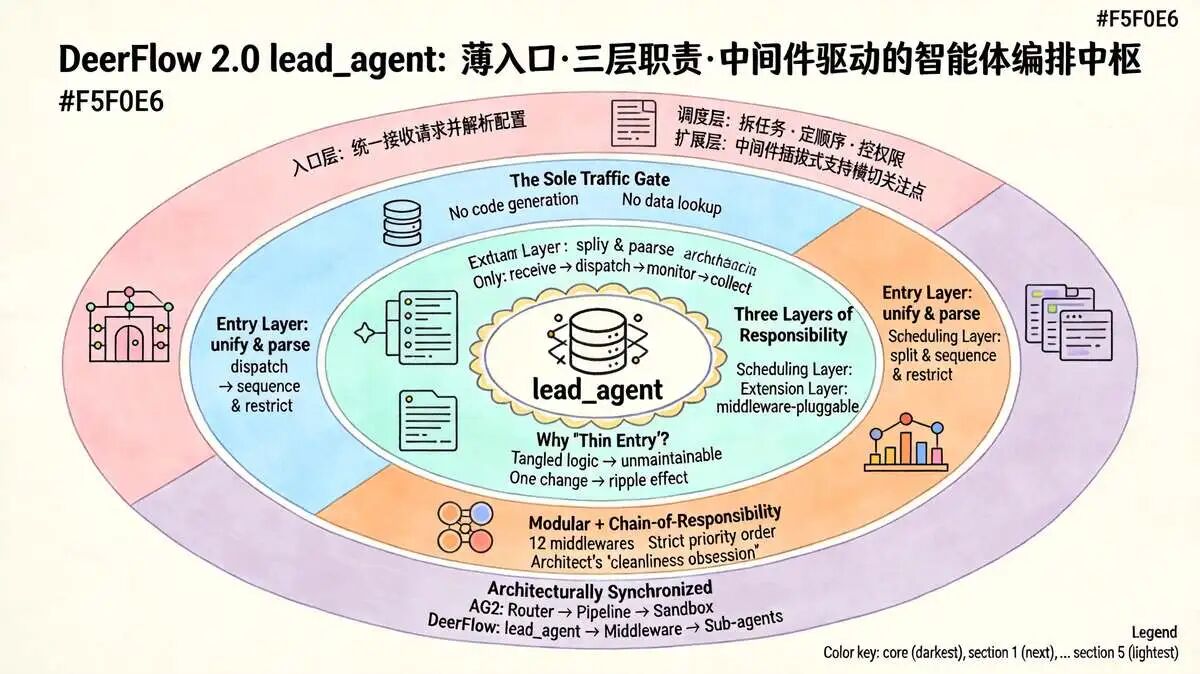
二、lead_agent模块架构设计核心定位
lead_agent 的核心定位很明确,就是任务总调度器加智能体统一入口。
它不负责干脏活累活,它只负责把用户扔过来的需求拆明白,把子智能体和工具排好队,再用中间件把缓存、日志、权限这些杂活管起来。
很多框架一上来就搞大模型直出,结果请求稍微复杂点,上下文就炸了,token 直接烧穿预算。
DeerFlow 2.0 没走那条路,它选了模块化、可扩展、可配置这条慢功夫路线。
架构依赖 LangGraph 的状态机,把请求到结果做成闭环。大家要是自己搭过 Agent,就知道状态管理有多折磨人,这框架直接把脏活包了。
lead_agent 的作用其实在三个层面,大家一眼就能看明白:
- 入口层,统一接 控制台、Web UI 或 API 过来的请求,顺手把运行时配置抠出来,比如模型选谁、要不要开计划模式、子智能体并发上限卡到几;
- 调度层,拿着请求和配置开始拆任务,把能并行干的活分给子智能体, 谁先谁后它说了算;
- 扩展层,中间件机制是它的底牌,缓存怎么打、日志怎么记、权限怎么控、任务怎么跟踪,全插在这个缝隙里,场景变了,插件直接换,不用动主逻辑。
入口层负责统一收口。控制台、Web UI、API 打过来的流量,全被 RunnableConfig 接住。运行时参数像模型选型、计划模式开关、并发上限,全在这一层洗过一遍。
调度层负责拆活儿。拿到干净的参数后,lead_agent 会把重任务切开,按依赖关系或者资源水位把子智能体推出去并行跑。工具权限也在这一步卡死,越界调用直接拦下。
扩展层靠中间件撑着。缓存打进去、日志打进去、权限校验打进去,甚至自定义的业务钩子也能插进去。不同场景直接换插件,不动核心逻辑。
这玩意跑起来靠四根柱子撑着:
- 配置解析组件把参数喂进去。
- 模型管理组件把 LLM 实例化。
- 中间件组件把流程管死。
- 任务调度组件把活派出去。
四块咬合,状态机一转,整个系统就活了。
这四块组件咬合在一起,才是它跑稳的底气。配置解析负责喂参数,模型管理负责选大脑,中间件负责控流程,任务调度负责落执行。少一环,链条就得断。
尼恩总结 这里的架构哲学: 把确定性的事写死,把不确定性的事交给插件。大家写系统的时候,记住这条,能省掉一半的重构时间。
三、lead_agent 核心组件架构与实现细节
lead_agent 的源码其实不厚,核心就瘫在两个文件上,lead_agent.py 负责硬核逻辑,prompt.py 负责系统提示词拼装。
两个文件一静一动,把初始化、配置、调度、交互全串起来了。
但往下挖才发现,里面藏着的容错和状态同步逻辑,都是实打实的线上经验换来的。
3.1 DeerFlow 配置解析组件:统一配置管理,支持动态调整
配置解析这块,说白了就是把所有运行时参数收口,别让业务代码去猜配置在哪。
大家 做内部系统,最头疼的就是配置散落在 .env、yaml、数据库里,改一个参数得重启三个服务。
DeerFlow 2.0 直接把配置加载逻辑,抽成独立管道,全走 deerflow.config 包。大家看代码会发现,它不硬编码任何默认值,全靠函数动态拉取。
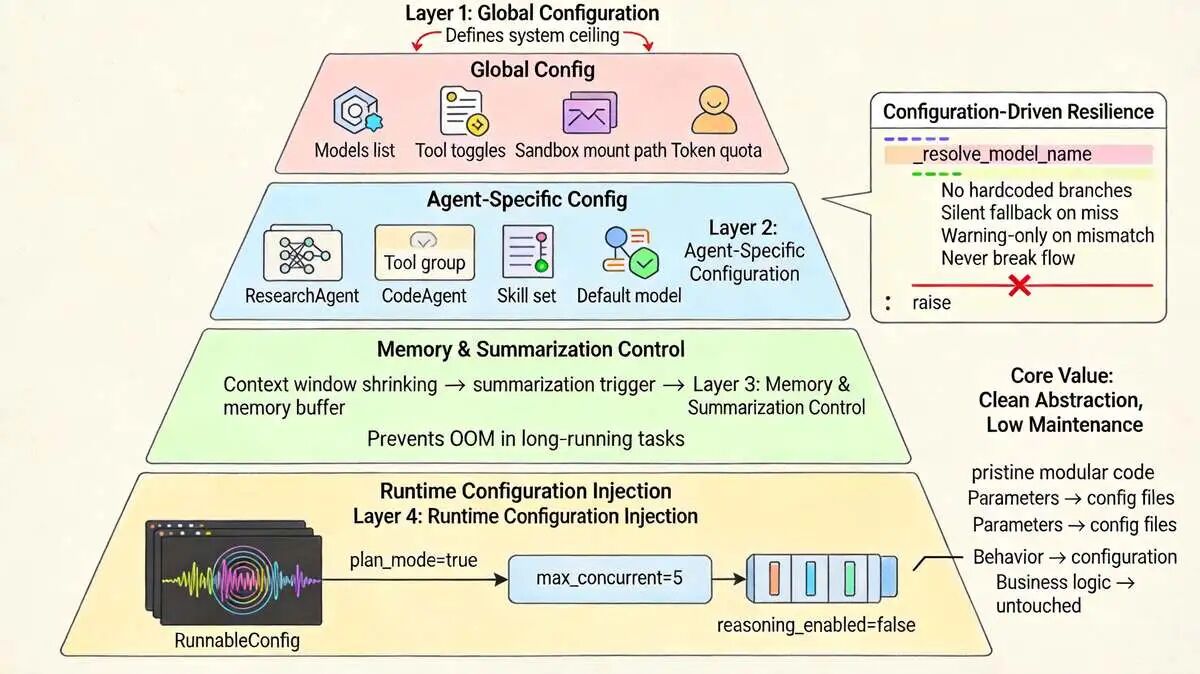
核心实现逻辑其实就这四步,尼恩给大家列清楚:
-
全局配置加载,调
get_app_config()把框架底层的模型列表、工具开关、沙箱挂载路径、Token 限额全拉进来,这步定死了系统的天花板; -
智能体配置加载,调
load_agent_config(agent_name)按名拉取,每个 Agent 的工具组、技能集、默认模型都不一样,差异化配置全靠它撑着; -
内存与摘要配置,调
get_memory_config()和get_summarization_config(),控制上下文怎么存、摘要什么时候触发,这直接决定了长任务会不会爆内存; -
运行时配置解析,从
RunnableConfig里抠出动态参数,计划模式开没开、子智能体并发数多少、思考模式要不要启,全在这一步动态注入,不用重启服务。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
配置驱动思维 :不把“选择困难症” 留给代码
很多开源框架的模型切换是写死的。DeerFlow 不是。
它把运行时参数全抽离到 config.yaml 和 RunnableConfig 里,典型的配置驱动思维。
看这段模型解析逻辑:
def _resolve_model_name(requested_model_name: str | None = None) -> str:app_config = get_app_config()default = app_config.models[0].name if app_config.models else Noneif not default: raise ValueError("No chat models configured.")# 优先使用请求模型,无效则静默降级,绝不中断流程if requested_model_name and app_config.get_model_config(requested_model_name):return requested_model_nameif requested_model_name and requested_model_name != default:logger.warning(f"Model '{requested_model_name}' not found; fallback to default.")return default没有硬编码分支,没有异常阻断。查不到?降级。打条 Warning 继续跑。
这不就是我们在高可用微服务里常做的容错降级策略吗?
3.2 DeerFlow 模型管理组件:多模型适配,支持动态切换
模型管理组件干的是脏活。现在的模型市场迭代太快,今天用 Qwen,明天可能要换 Deepseek 的某个新系列,统一接口把复杂度压到了最低。
得把各种厂商的 LLM 揉进同一个接口里,还得照顾模型的能力差异。
尼恩自己对接过一堆模型,有的支持视觉,有的能开思考模式,有的上下文窗口特别窄。硬适配只会让代码变成意大利面条。
DeerFlow 2.0 选了统一封装的路子,核心靠 deerflow.models.create_chat_model 兜底。
核心功能 实现:
- 模型解析与创建,根据解析后的模型名称,调用
create_chat_model创建模型实例,支持配置思考模式(thinking_enabled)、推理力度(reasoning_effort)等参数; - 模型能力适配,检查模型是否支持思考模式、视觉能力,若不支持则自动回退(如思考模式启用但模型不支持时,自动关闭思考模式);
- 模型容错处理,当请求模型不存在或配置无效时,自动回退到全局默认模型,并记录警告日志,确保智能体正常运行。
模型管理组件的设计贴合DeerFlow 2.0的多模型适配需求,支持通过配置文件扩展模型类型(如Qwen、OpenAI系列模型),同时通过统一的接口封装,降低了模型集成的复杂度,为后续模型替换与扩展提供了便利。
def create_chat_model(name: str | None = None, thinking_enabled: bool = False, **kwargs) -> BaseChatModel:"""Create a chat model instance from the config.Args:name: The name of the model to create. If None, the first model in the config will be used.Returns:A chat model instance."""config = get_app_config()if name is None:name = config.models[0].namemodel_config = config.get_model_config(name)if model_config is None:raise ValueError(f"Model {name} not found in config") from Nonemodel_class = resolve_class(model_config.use, BaseChatModel)model_settings_from_config = model_config.model_dump(exclude_none=True,exclude={"use","name","display_name","description","supports_thinking","supports_reasoning_effort","when_thinking_enabled","when_thinking_disabled","thinking","supports_vision",},).....省略model_instance = model_class(**{**model_settings_from_config, **kwargs})callbacks = build_tracing_callbacks()if callbacks:existing_callbacks = model_instance.callbacks or []model_instance.callbacks = [*existing_callbacks, *callbacks]logger.debug(f"Tracing attached to model '{name}' with providers={len(callbacks)}")return model_instance模型创建层 也是 策略模式落地。
create_chat_model 统一封装实例化,运行时动态检查:支持 Thinking Mode?支持 Vision?不支持就自动剥离参数。
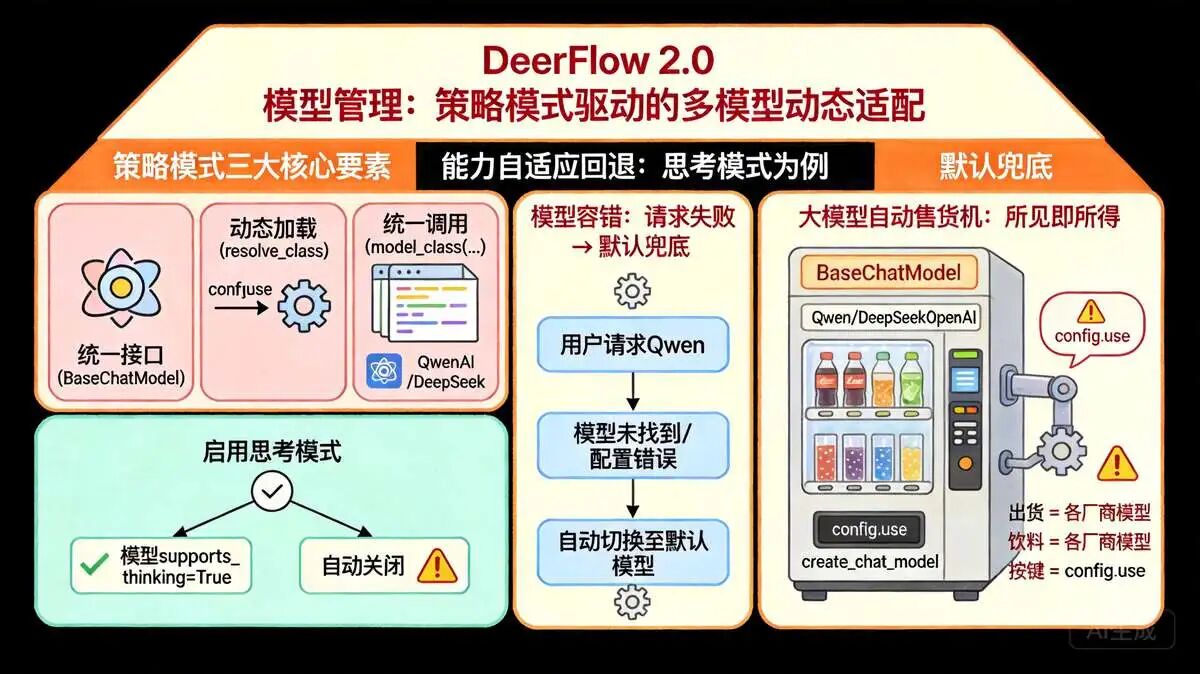
DeerFlow 2.0 模型管理组件的核心设计,是用策略模式。
策略模式的核心逻辑是“统一接口、多实现、动态选择”, 实现 “统一封装、降低复杂度”的设计初衷。
策略模式的三大核心要素:
-
首先是统一接口(策略抽象),即
BaseChatModel基类,所有模型(Qwen、OpenAI、DeepSeek等)必须继承这个基类,保证接口完全一致,这正是策略模式中的抽象策略,为所有厂商模型提供了统一的行为标准,规范了聊天、能力适配等核心操作。 -
其次是动态加载不同策略,这是整个模式的核心所在,对应官方代码中
model_class = resolve_class(model_config.use, BaseChatModel)这一行。这行代码堪称策略模式的灵魂:model_config.use是配置文件中定义的模型路径,比如use: deerflow.models.qwen.QwenChatModel或use: deerflow.models.openai.OpenAIChatModel,而resolve_class(...)方法, 会动态将这个字符串解析为对应的模型类,本质就是根据配置自动选择不同的模型策略,实现运行时动态切换模型实现,无需修改核心代码。 -
最后是所有策略统一调用,这也是策略模式的核心目的,对应代码中
model_instance = model_class(**{**model_settings_from_config, **kwargs})。无论底层是Qwen、OpenAI、DeepSeek,还是Claude、通义、文心、智谱,都能通过这一行代码创建实例,上层调用完全不用关心底层模型的具体实现,真正实现了“接口统一,实现可拔插,调用方零感知”。
用最简单的类比来说,这段代码就像一个“大模型自动售货机”:
BaseChatModel是售货机的出货口(统一接口),Qwen、OpenAI等各类模型是不同饮料(不同策略),config.use是按下的选择按钮(选择策略),而create_chat_model就是售货机内部的机械结构,根据按钮指令送出对应“饮料”(模型实例)。- 使用者无需关心模型的底层实现,只需传入模型名,就能获得符合统一接口的模型实例。
极简总结来看,DeerFlow 2.0 策略模式落地就是:抽象为BaseChatModel(统一接口),策略为各个厂商的模型实现,调度由create_chat_model动态加载策略,使用时上层调用完全一致。
这种设计看似复杂,实则最稳定,完美契合DeerFlow 2.0多模型适配、易扩展的核心需求。
策略模式在这里不是炫技,而是为了应对“大模型能力碎片化”的现实。
不需要为 Qwen 写一套适配,为 OpenAI 再写一套。框架自己算。
说实话,这种设计刚看觉得“绕”,但是, 大家后续想加新模型,只要实现标准协议,直接注册进去就行,调度层完全无感。
这种设计,看着笨,其实最稳。
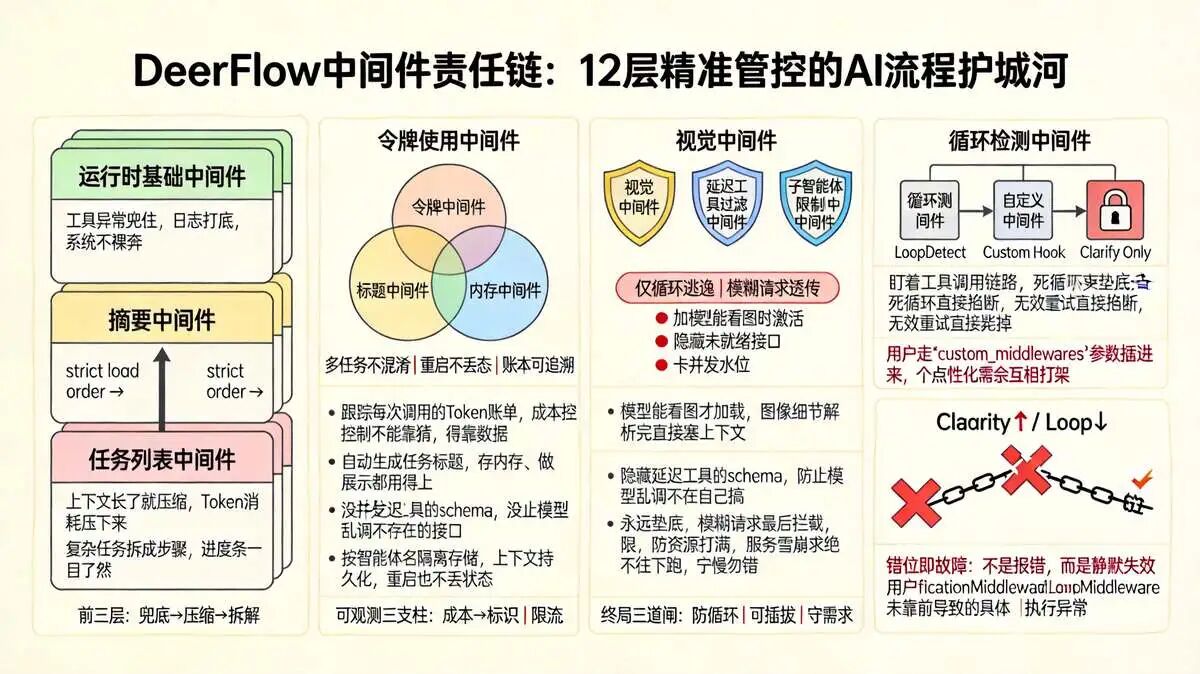
3.3 DeerFlow 中间件组件:可扩展的流程管控机制
中间件是 lead_agent 的护城河。它基于 LangChain 的 AgentMiddleware 机制,把一堆拦截器串成链条。
尼恩之讲做Netty 网关、Go框架 gin 、SpringSecurity 、Mybatis,对责任链模式太熟了,但用在 AI 调度上,感觉完全不一样。
AI 的执行流 ,中间件得在状态机的每个节点上精准切入。加载顺序要是乱一点,逻辑就会互相打架。
3.3.1 中间件加载顺序与核心作用
看源码里的 _build_middlewares 函数,加载顺序是严格卡死的。
尼恩把这块逻辑给大家拆成列表,大家对照着看,顺序就是业务优先级:
-
运行时基础中间件,
build_lead_runtime_middlewares先上,把工具调用异常兜住,日志打底,系统不裸奔; -
摘要中间件,
DeerFlowSummarizationMiddleware紧跟着上,上下文长了就压缩,Token 消耗压下来,触发条件和保留内容全按配置走; -
任务列表中间件,
TodoMiddleware只在计划模式开的时候加载,复杂任务拆成步骤,待处理、进行中、已完成状态实时更新,进度条一目了然; -
令牌使用中间件,
TokenUsageMiddleware跟踪每次调用的 Token 账单,成本控制不能靠猜,得靠数据; -
标题中间件,
TitleMiddleware自动生成任务标题,存内存、做展示都用得上,多任务跑的时候不至于眼花; -
内存中间件,
MemoryMiddleware管会话记忆,按智能体名隔离存储,上下文持久化,重启也不丢状态; -
视觉中间件,
ViewImageMiddleware模型能看图才加载,图像细节解析完直接塞上下文,多模态任务能跑; -
延迟工具过滤中间件,
DeferredToolFilterMiddleware搜索开启时隐藏延迟工具的 schema,防止模型乱调不存在的接口,这步防呆设计太聪明了; -
子智能体限制中间件,
SubagentLimitMiddleware卡并发上限,防资源打满,服务雪崩的根因往往在这; -
循环检测中间件,
LoopDetectionMiddleware盯着工具调用链路,死循环直接掐断,无效重试直接毙掉; -
自定义中间件,用户走
custom_middlewares参数插进来,个性化需求自己搞,不污染主分支; -
澄清中间件,
ClarificationMiddleware永远垫底,模糊请求最后拦截,没搞清需求绝不往下跑,宁慢勿错。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
3.4 DeerFlow 任务调度组件:核心逻辑入口,实现任务分解与执行
任务调度组件是 lead_agent 的心脏。 make_lead_agent 函数就是点火开关。
它靠 LangChain 的 create_agent 做底层组装,但 DeerFlow 2.0 没照搬,它塞进了自己的配置和状态机。
核心智能体创建代码片段:
# 任务调度核心入口
def run_lead_agent(user_query: str, config: RunnableConfig):# ==========================================# 这里才是 is_bootstrap 模式判断真正出现的地方!# ==========================================is_bootstrap = config.get("metadata", {}).get("is_bootstrap", False)if is_bootstrap:# ======================# 引导模式:极简初始化# ======================agent = make_lead_agent(config,minimal_system_prompt=True, # 极简提示词only_setup_tools=True # 只加载初始化工具)else:# ======================# 默认模式:全量能力# ======================agent = make_lead_agent(config,minimal_system_prompt=False,only_setup_tools=False)# 执行任务return agent.invoke(user_query, config=config)分两条路走。引导模式 is_bootstrap 为真时,走极简路线。提示词砍到最少,只挂 setup_agent 基础工具,快速把自定义智能体初始化出来。默认模式走全量路线: 工具组、技能集、中间件链、完整提示词全部加载,复杂任务直接下场跑。
尼恩觉得,好的调度器不是写得越复杂越好,而是把边界划清楚,让每个环节知道该干什么,不该碰什么。大家写并发逻辑的时候,记住这条,能避开无数死锁和状态污染的坑。
核心流程就两条线,大家看明白就通透了:
- 引导模式分支,
is_bootstrap=True的时候走这条,初始化自定义 Agent,提示词压到最小,只加载setup_agent基础工具,秒级启动,不拖泥带水; - 默认模式分支,常规任务全走这,把指定 Agent 的工具组、技能集、中间件链、系统提示词全拉满,复杂任务拆解、调度、汇总一条龙。
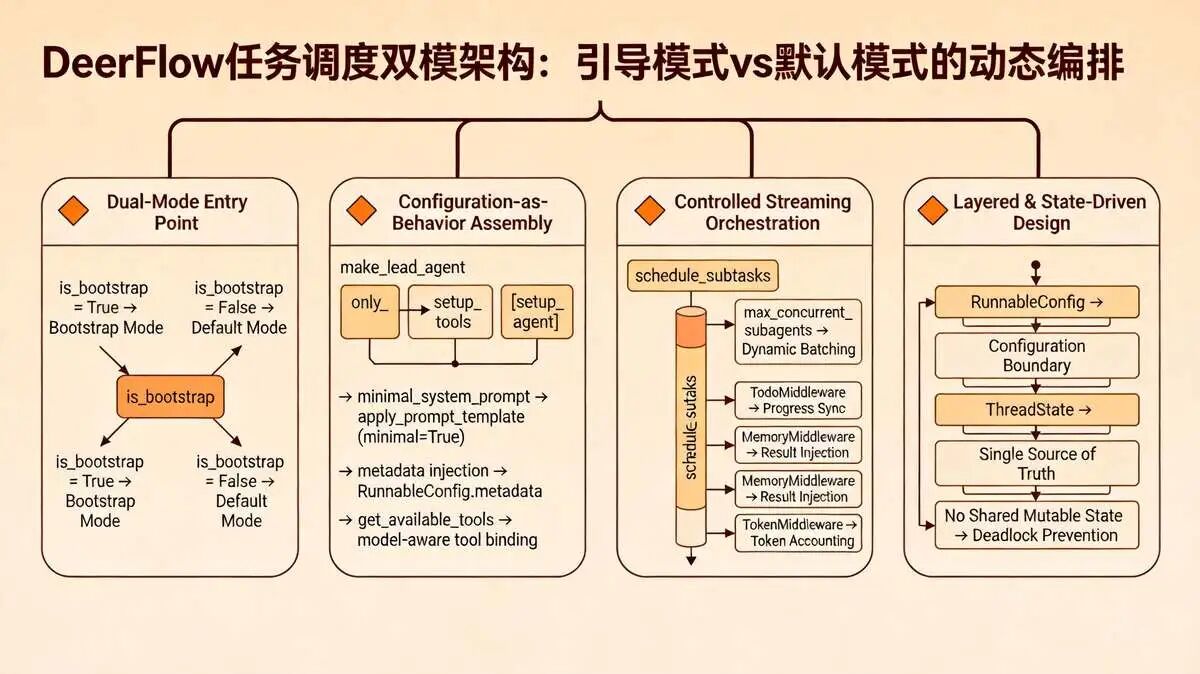
然后 make_lead_agent 接收参数,动态构建 Agent:
def make_lead_agent(config: RunnableConfig,minimal_system_prompt: bool = False,only_setup_tools: bool = False
):model_name = _resolve_model_name(config.get("model_name"))model = create_chat_model(name=model_name, thinking_enabled=True)middlewares = _build_middlewares(config, model_name)# ==========================================# 工具加载:引导模式只给 setup_agent# ==========================================if only_setup_tools:tools = [setup_agent] # 极简工具else:tools = get_available_tools(model_name=model_name) # 全量工具# ==========================================# 提示词:引导模式用极简版# ==========================================system_prompt = apply_prompt_template(minimal=minimal_system_prompt)# 最终组装Agentreturn create_agent(model=model,tools=tools,middleware=middlewares,system_prompt=system_prompt,state_schema=ThreadState)调度这块的架构思维其实很清晰,分层解耦,状态驱动。
make_lead_agent 是整个模块的启动按钮。接住 RunnableConfig,把前面说的配置、模型、中间件全揉在一起,最后喂给 LangChain 的 create_agent。
关键实现细节其实就压在这四块:
- 智能体初始化,模型、工具、中间件、提示词、
ThreadState状态 schema 全喂给create_agent,实例化一步到位; - 系统提示词构建,
apply_prompt_template动态注入 Agent 名、技能、内存上下文、子 Agent 配置,提示词跟着场景变; - 元数据注入,Agent 名、模型名、运行时参数全打进
RunnableConfig的 metadata,LangSmith 追踪直接点亮,调试不靠盲猜; - 工具加载,
get_available_tools按模型能力动态拉,子 Agent 配置一匹配,工具权限实时对齐,不多给也不少给。
从架构师视角来分析, lead_agent 的核心职责是 Orchestration。
复杂任务进来,怎么拆?怎么防并发爆炸?
它引入了任务编排模式。
make_lead_agent 初始化时,直接绑定 LangGraph 的 ThreadState。
任务判定为复杂后,立刻走子智能体分支。调度不是无脑并发,而是基于 max_concurrent_subagents 做动态分批(Batching)。
# 伪代码示意:分批调度与状态同步
def schedule_subtasks(subtasks, max_concurrent):batches = [subtasks[i:i+max_concurrent] for i in range(0, len(subtasks), max_concurrent)]for batch in batches:asyncio.gather(*[task(sub) for sub in batch])# 中间件在后台同步:TodoMiddleware更新进度,MemoryMiddleware注入结果,TokenMiddleware记账return aggregate_results()分批调度听着简单,配合 LangGraph 的状态机,就变成了“可控流式执行”。
一批跑完,结果写回共享 Memory,SummarizationMiddleware 压缩上下文,再放下一批。
整个生命周期,像一条精密的流水线。没有状态溢出,没有 Token 炸裂。
3.5 DeerFlow 系统提示词组件:智能体行为约束与引导
提示词组件 prompt.py 看着像辅助,其实是隐形的缰绳。大模型再聪明,没有边界也会跑偏。
SYSTEM_PROMPT_TEMPLATE 把角色、思考方式、任务流、工具规范全框死了。
尼恩自己调过无数 Prompt,最后发现,约束比引导管用,规则越清晰,输出越稳定。
核心提示词模块拆开看,其实就这九块:
- 角色定义,
<role>标死身份,开源超级智能体,定位不飘; - 智能体个性,
<soul>加载SOUL.md,交互语气差异化,不冷冰冰; - 思考方式,
<thinking_style>规定逻辑链,先澄清、再拆解、绝不抢跑出最终结论; - 澄清系统,
<clarification_system>定死规则,缺信息直接问用户,宁停等不瞎编; - 技能系统,
<skill_system>注入可用技能,复杂任务优先走技能流,渐进式加载,不堆砌; - 子智能体系统,
<subagent_system>子 Agent 开的时候塞配置,并发限制、类型列表全亮明,调度有依据; - 工作目录,
<working_directory>规范沙箱路径,文件读写有根有据,不乱写磁盘; - 引用规范,
<citations>卡死研究类输出格式,内联引用加来源列表,可追溯是底线; - 关键提醒,
<critical_reminders>汇总铁律,澄清优先、并发限制、输出路径,反复敲打,防遗忘。
四、lead_agent模块关键工作流程解析
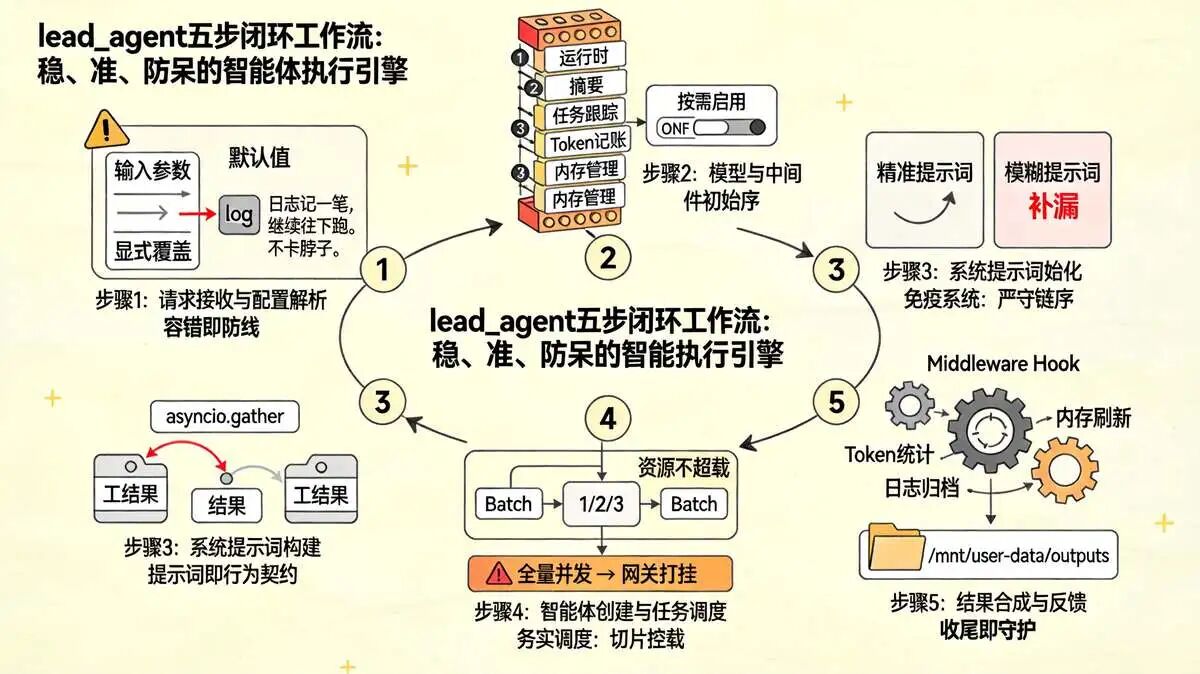
源码跑起来,lead_agent 的工作流其实就五步闭环。
尼恩给大家按执行顺序捋一遍,每一步都藏着防呆设计。大家要是自己跟一遍源码,会发现它的节奏感控制得很好,不贪快,只求稳。
步骤1:请求接收与配置解析
请求从控制台、Web UI 或 API 进来,任务描述和运行时配置混在一起扔给 make_lead_agent。
RunnableConfig 接住参数,解析模块启动。全局配置、Agent 专属配置、内存配置全拉进来。运行模式、参数边界在这一步就画死。
尼恩觉得这步最考验的是容错,参数缺失怎么处理,配置冲突谁覆盖谁,全得提前想好。这框架的做法是,缺的走默认,冲突的走显式覆盖,日志记一笔,继续往下跑。不卡脖子。
步骤2:模型与中间件初始化
配置解析完,模型选型走 _resolve_model_name。
名字定下来,create_chat_model 实例化。能力探测紧跟,不支持的开关自动回退。
中间件链通过 _build_middlewares 组装 ,按顺序把运行时、摘要、任务跟踪、Token 记账、内存管理全挂上。按需启用的插件,在这一步决定是进链还是跳过。
尼恩自己看这段逻辑的时候,觉得太实在了。
这步是框架的免疫系统。插件挂错顺序,后面执行流会乱序。严格卡位,是 LangGraph 能稳跑的前提。
步骤3:系统提示词构建
模型和中间件就位后,提示词进场。
apply_prompt_template 把当前上下文缝进模板。
Agent 名称、可用技能、内存上下文、子 Agent 配置全拼进去。系统提示词成型。行为约束规则同步下发。澄清逻辑、调度规则、工具权限全刻进初始指令。
大家跑复杂研究任务的时候,这步决定了 Agent 的决策天花板。
坦率的讲,提示词不是魔法,是约束条件:
-
给得越准,模型越不容易跑偏,执行流自然顺滑。
-
提示词给得模糊,后面全在补漏。
步骤4:智能体创建与任务调度
create_agent 拿到模型、工具、中间件、提示词、ThreadState,实例直接生成。
Agent 开始干活。任务分解逻辑按复杂度分流:
- 简单任务,直接调工具,不拆不绕,一步到位;
- 复杂任务,子 Agent 启动,任务切片,按
max_concurrent_subagents分批派发,并行跑完再汇总,吞吐量拉满; - 模糊任务,澄清中间件拦截,抛问题给业务侧,拿回明确指令再往下走,绝不脑补。
任务调度核心代码片段(子智能体分批调度):
def schedule_subtasks(subtasks, max_concurrent):batches = [subtasks[i:i+max_concurrent] for i in range(0, len(subtasks), max_concurrent)]for batch in batches:# 并行执行当前批次子任务asyncio.gather(*[task(sub) for sub in batch])return汇总所有批次结果尼恩觉得这段调度逻辑最实在。
没搞虚的分布式共识,就老老实实按并发上限切批次。
asyncio.gather 扛住并行,资源不超载。
全量并发容易把网关打挂,单线程又太慢。
切片跑,
大家写多任务流的时候,别一上来就搞全并发,分批切片、控上限、留余量,才是线上能跑稳的法子。
步骤5:结果合成与反馈
子任务跑完,结果往回流。 研究报告、文件输出按规范生成。
lead_agent 按提示词规范做拼装,输出研究报告或者结构化文件。
-
文件落到 /mnt/user-data/outputs,路径写死,防越权。
-
中间件同步收尾,内存刷新、Token 统计、日志归档,一条龙走完。
-
结果推给前端或者 API,控制台、Web UI、API 拿结果反馈。
全流程闭环。
尼恩自己的感受是,收尾往往比开头重要。状态不清理,内存泄漏迟早找上门。这框架把收尾塞进中间件钩子,自动化处理,不用人工擦屁股。省心。
五、架构设计亮点与技术优势
聊完细节,尼恩得退一步看整体。
lead_agent 的设计不是拼凑出来的,是踩过坑、烧过 Token、调过无数次状态机之后沉淀出来的架构选择。大家看这四块优势,其实都指向一个核心,把复杂性关在笼子里。
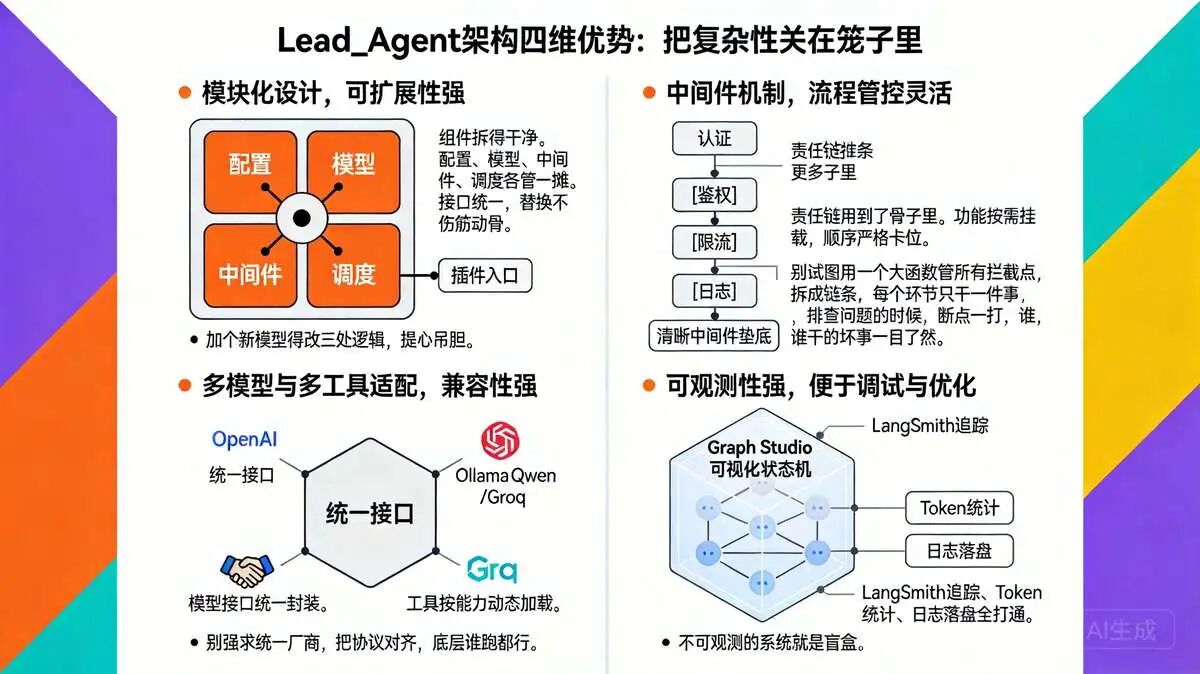
5.1 模块化设计,可扩展性强
组件拆得干净。配置、模型、中间件、调度各管一摊。接口统一,替换不伤筋动骨。尼恩之前维护过一套耦合严重的 Agent 系统,加个新模型得改三处逻辑,提心吊胆。
这框架直接把扩展点外露。大家想加日志插件、改权限逻辑、换底层模型,走配置和插件就行。主代码不动。架构哲学就一条,变的部分做成可插拔,不变的部分写死。扩展性不是吹出来的,是拆出来的。
5.2 中间件机制,流程管控灵活
责任链用到了骨子里。功能按需挂载,顺序严格卡位。尼恩觉得这设计最聪明的是把兜底逻辑放最后。澄清中间件垫底,确保前面跑偏的需求能拉回来。
大家做流程管控的时候,别试图用一个大函数管所有拦截点,拆成链条,每个环节只干一件事,排查问题的时候,断点一打,谁干的坏事一目了然。灵活和可控,本来就可以兼得。
5.3 多模型与多工具适配,兼容性强
模型接口统一封装。工具按能力动态加载。
尼恩自己的体验是,现在大模型生态碎片化严重,这框架不挑嘴,能适配就适配,适配不了就回退。子 Agent 调度、RAGFlow 知识库集成全留了口子。兼容性不是妥协,是底线。大家对接业务的时候,别强求统一厂商,把协议对齐,底层谁跑都行。实用主义永远比技术洁癖走得远。
5.4 可观测性强,便于调试与优化
LangSmith 追踪、Token 统计、日志落盘全打通。尼恩有时候觉得,不可观测的系统就是盲盒。这框架把执行流摊开给大家看。
Graph Studio 可视化状态机,中间件拦截点一目了然。成本优化靠数据说话,性能瓶颈靠日志定位。大家跑生产环境的时候,可观测性不是锦上添花,是保命符。没数据支撑的调优,都是瞎猜。
六、 为什么Deerflow 这套设计值得抄作业?
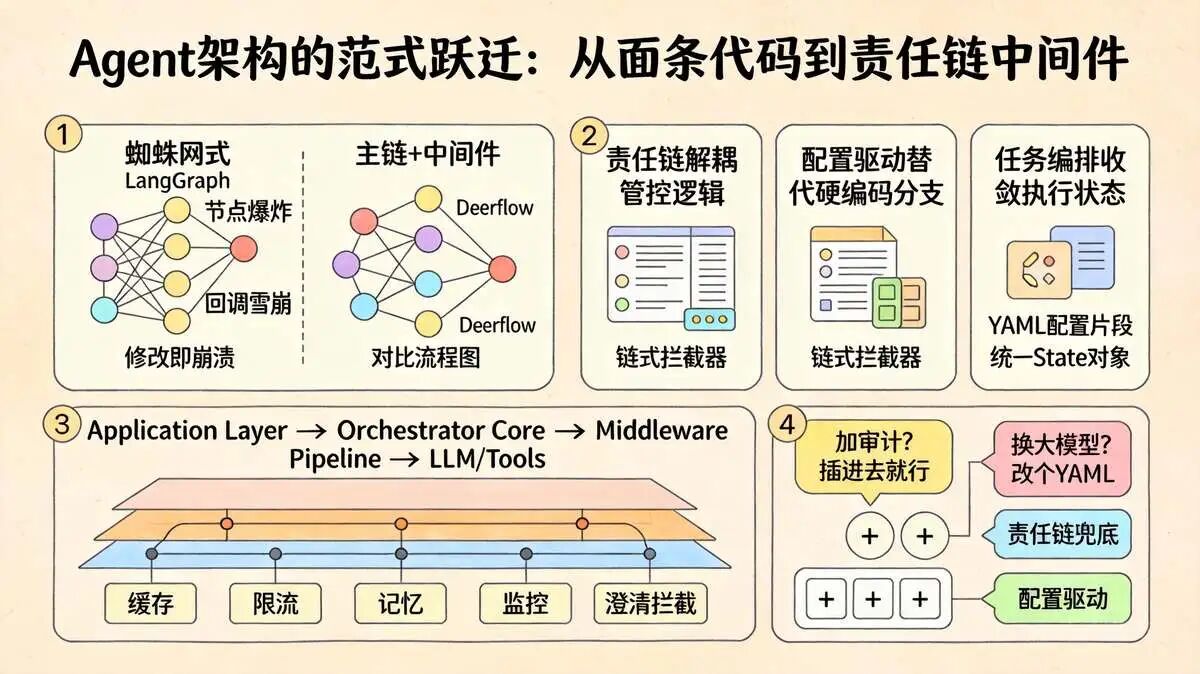
很多人做 Agent,一上来就堆 LangGraph 节点,边连边调,最后成了蜘蛛网。动一个工具,三个回调报错。lead_agent 反其道而行。
它用责任链解耦了管控逻辑,用配置驱动替代了硬编码分支,用任务编排收敛了执行状态。
我写这篇解析,真不是让你照搬代码。而是想传递一个视角:
好的 Agent 框架,拼的不是 System Prompt 写得有多长,而是底层的状态流转和横切面治理有多干净。
微软 AG2 最近也在推类似的 Agent Runtime + Middleware Pipeline 架构。
行业共识已经很明显:把核心业务留在主链,把缓存、限流、记忆、监控、澄清拦截全部抽成中间件。以后你要加审计?插进去就行。要换大模型?改个 YAML。
(回到开头那句)别再把 Agent 写成面条代码了。把关注点分离,让责任链去兜底,让配置去驱动。你会发现,维护一个能扛高并发、跑深度研究的系统,其实没那么玄乎。
架构不是炫技。是留后路。