QOJ#8673【PKUSC 2024 Day2】最短路径
基于 官方题解 补充一些自己的理解。
双向 dijkstra(折半搜索)
好在,我们简单分析一下,我们可以发现两边相遇过后,最多有一条不在最短路上的边。因此,我们可以枚举一侧的点,枚举它的出边,找到所有可能的路径。
证明:
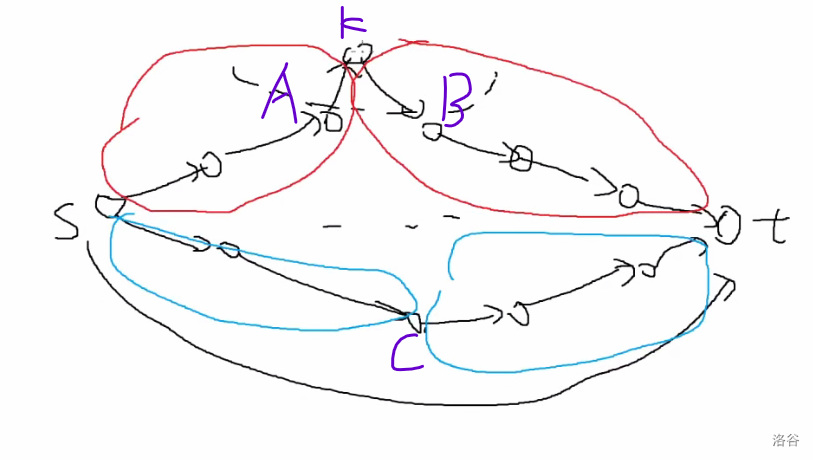
(偷的图)
反证法:下面那条是已经折半搜到的最短路,上面是假设的实际最短路。红蓝都已经搜过了。如果真的存在两条边在最短路上且没有搜过,则正着有 \(dis_C < dis_K\),倒着有 \(dis_C < dis_K\)。加起来得下面那条一定更优。
有序单边加入堆
如果你做过 k 短路,或者类似的题,它们都有用到这个技巧:我们注意到由一个点出发的边,肯定是边权小的会先出堆,因此,如果我们预先将每个点的出边按照边权排序,我们可以只往堆中塞入第一条边,当第一条边出堆时候,再把第二条边塞入堆中。如此操作,堆中的边数就线性于出堆次数了,我们也就解决了这个艰难的问题。
ai回答
这个技巧本质上是一种 **“按需取用,懒加载边”** 的思想。它专门解决 Dijkstra 算法在遇到**度数极高**的节点时,堆中塞入过多边导致性能爆炸的问题。为了讲清楚,我们先看常规 Dijkstra 在稠密图里的痛点,再解释这个技巧是如何四两拨千斤的。
常规 Dijkstra 的痛点:把一堆石子一次性全扔进水里
想象你要从起点往一个大水池里扔石子,每颗石子代表一条边。Dijkstra 算法每确定一个点的最短距离,就要把从这个点出发的所有边(石子)都扔进优先队列(水池)里,然后每次从水池里捞出距离最小的那颗石子来处理。
- 如果一个点有 10 万条出边(即度数 10 万),那么它被确定距离的那一瞬间,10 万条边会同时进入优先队列。
- 优先队列(堆)维护 10 万元素的成本是很高的,内存也受不了。
- 更要命的是,这 10 万条边里可能只有排在前面的几条是有用的,排在后面的边(权值很大)可能要等很久才会被捞起来,甚至根本轮不到它(因为已经找到更短路了),白白占着队列的位置浪费算力。
技巧的核心:每次只扔一颗石子,听个响再扔下一颗
这个优化技巧的思路非常朴素:
- 先把石子按大小排好队(把每个点的出边按边权从小到大排序)。
- 手里只拿第一颗石子(一开始只把权值最小的那条边塞进堆里)。
- 等这颗石子从水里捞出来了(从堆顶弹出),我再把下一颗石子扔进去。
也就是说,堆里永远只保留每个节点当前最小且未被处理的那条边。堆的大小从“所有已发现但未处理的边”降级为“每个节点的一条候选边”,堆的元素数量被死死压在了 O(节点数) 的级别。
通俗正确性证明:为什么这样做不丢最优解?
这里的关键逻辑是:边是按权值从小到大排序的,且 Dijkstra 是按距离从小到大处理的。
- 当你从堆顶弹出一条边
u -> v时,说明u的当前距离已经是最短的了(因为是堆顶最小元素)。 - 此时你用这条边去更新
v的距离,做完这件事之后,u的这条边就没用了。 - 紧接着,你应该尝试
u的下一条边。 为什么?因为u的剩下出边里,下一条边权是最小的,它最有可能在不久的将来再次更新别的点。
如果某条边在堆里待了很久才被弹出来,它后面的边(权值更大)更没有提前入堆的必要——因为 Dijkstra 处理的是单调递增的距离,权值大的边天然要往后排,早进堆也是睡大觉。
为什么能大幅加速?
- 堆的规模骤降:堆里元素从
O(边数)变成O(节点数)。单次堆插入/弹出的代价从log(10万)降到log(1000),常数优化巨大。 - 减少无效入堆:很多权值极大的边,因为算法已经提前找到了更优路径,可能永远都没有机会被塞进堆里,直接节省了入堆操作的时间。
- 内存友好:不需要把海量边同时加载到堆的内存结构中,缓存命中率更高。
结合博客里说的“子任务 2 只要跑单向 Dijkstra 就可以了”
在题目 QOJ#8673 中,图是随机生成的。虽然度数大,但期望上每次查询到达的点是均匀随机的。用了这个技巧后,单向 Dijkstra 的堆操作次数期望只有 O(n) 次,而不是 O(m) 次。因为大部分边的入堆操作被延迟甚至免除了,最终复杂度降为 O(q n log n + m log m)(前面的 m log m 是排序出边的一次性开销)。
总结成一句话就是:把“一口气喂给算法”改成“挤牙膏式供给”,让算法只处理真正有必要计算的那部分数据。
这种方法在稠密图、多查询(预处理也占据复杂度,多查询可以均摊掉)较适用。
最终解法的剪枝
复杂度不会证。
为什么选择折半搜索
ai
skip2004 的这段话,核心是揭示了一个反直觉的洞察:**在一个边权随机的图中,最短路树的规模与节点度数并非单调关系。** 恰恰是在度数较小的图中,最短路树才呈现出指数级爆炸的特征。1. 为什么最短路树会“指数级展开”?
首先,“最短路树”不是真的树,而是一个不断膨胀的节点集合。它在单源最短路径算法中,随着路径的延伸,新纳入的节点数量会急剧增长。
之所以会指数级爆炸,根源在于边权的随机性与平均化。
- 普遍的低权值链路:在 \(m \le 2.5n\) 的稀疏图中,节点的平均度数很低,但这恰恰是问题所在。由于边权是随机的,算法很容易找到许多条边权非常接近甚至相同的路径。
- 众多“同级别”最短路径:假设从起点 \(s\) 出发,通过不同边都能以相同或相近的代价到达多个不同的新节点,那么在下一轮,这些新节点又会各自向外扩展,探索出更多代价相近的路径。
- 搜索前沿的指数级膨胀:想象一棵树,根节点长出许多分支,每个分支在下一层又长出同样多的分支。在算法运行到一半时,探索的“前沿”(即算法正在处理的节点集合)会变得非常巨大,节点数量呈指数级增长。由于图是稀疏的,这些路径很难“相交”或“相遇”,导致爆炸效应更持久。
这正是 skip2004 所说的“由一个点 s 为根最短路树,几乎是以指数级展开的”。
2. 为什么要用“折半搜索”?
折半搜索(双向 Dijkstra)正是对抗指数级爆炸的最有效武器。
我们可以将指数级爆炸量化为 \(O(b^d)\),其中 \(b\) 是“分支因子”(每层平均探索的新节点数),\(d\) 是搜索深度。问题的可怕之处在于,深度 \(d\) 的微小增加,都会导致搜索节点数急剧上升。
折半搜索如何化解?
- 双向出发:同时从起点 \(s\) 和终点 \(t\) 开始搜索。
- 折半相遇:让两个搜索过程都运行到深度 \(d/2\) 时,在中间的某个节点“相遇”。
- 复杂度开根号:搜索的总复杂度从 \(O(b^d)\) 变为 \(O(2 \cdot b^{d/2}) = O(b^{d/2})\)。这意味着,搜索量不再是原来的量级,而是它的平方根。这是一个从“不可能”到“瞬间”的巨大跨越。
因此,虽然双向搜索是普及组算法,但它在这里是完美应对指数爆炸的最佳策略。
3. 为什么出度变大后,依然要“折半搜索”?
这就触及了问题的更深层次洞察。当图变得稠密(\(m\) 远大于 \(n\))时,情况发生了根本性变化,但双向搜索依然有效,甚至更高效,不过原因变了。
- “生日悖论”效应:在稠密图中,边非常多,从 \(s\) 和 \(t\) 出发的路径很快就能到达很多相同的节点。这就好比一个房间里有 23 个人,两个人同一天生日的概率就超过 50%。在这个图里,两个搜索过程的“生日”(相遇的节点)会非常早地到来。
- 搜索深度极浅:正因为相遇极快,搜索的深度 \(d\) 变得非常小。因此,即使每个节点的分支因子 \(b\)(出度)变大了,但由于指数(深度 \(d\))极小,整体的搜索节点数 \(S\) 并不会爆炸。skip2004 的博客中也提到,此时两个搜索集合的大小只需达到 \(O(\sqrt{n})\) 级别就可以高概率相遇。
总结
skip2004 这段论述的精妙之处在于:
- 在稀疏图中,用双向搜索来对抗指数级爆炸;
- 在稠密图中,则利用“生日悖论”确保双向搜索天然会在很浅的深度相遇,从而自动控制复杂度。
这是一种对算法和数据特性深度结合的透彻理解,双向 Dijkstra 在这里不是生搬硬套的模板,而是因“图”制宜的“最优解”。