前言
本文介绍了Focused Linear Attention技术及其在YOLOv11中的集成。该技术旨在解决传统自注意力机制计算复杂的问题,通过引入映射函数提高焦点能力,利用秩恢复模块保持特征多样性,且具有线性复杂度。我们将Focused Linear Attention模块引入YOLOv11,在检测头部分的不同尺度特征图上应用该模块。通过实验训练改进后的模型,有望提升YOLOv11在目标检测任务中的性能。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
@
- 前言
- 介绍
- 摘要
- 文章链接
- 基本原理
- 核心代码
- 实验
- 脚本
- null
- 结果
介绍
摘要
自注意力的二次计算复杂性在将Transformer模型应用于视觉任务时一直是一个持久的挑战。相比之下,线性注意力通过精心设计的映射函数来近似Softmax操作,提供了更高效的替代方案,其计算复杂性为线性。然而,目前的线性注意力方法要么遭受显著的性能下降,要么因映射函数引入了额外的计算开销。在本文中,我们提出了一种新颖的聚焦线性注意力模块,以实现高效率和高表现力。具体来说,我们首先从聚焦能力和特征多样性两个角度分析了线性注意力性能下降的因素。为克服这些限制,我们引入了一个简单但有效的映射函数和一个高效的秩恢复模块,以增强自注意力的表现力,同时保持低计算复杂性。大量实验表明,我们的线性注意力模块适用于各种先进的视觉Transformer,并在多个基准测试上实现了一致的性能提升。代码可在 https://github.com/LeapLabTHU/FLatten-Transformer 获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
Focused Linear Attention技术是一种用于改进自注意力机制的方法 。
-
焦点能力(Focus Ability):传统的自注意力机制(如Softmax注意力)在计算注意力权重时通常会产生相对平滑的分布,导致模型难以集中关注到最重要的特征。Focused Linear Attention通过引入专门设计的映射函数,调整查询和键的特征方向,使得注意力权重更易区分。这样可以使模型更加集中地关注到重要的特征,提高了焦点能力。
-
特征多样性(Feature Diversity):另一个问题是线性注意力可能会降低特征的多样性,因为注意力矩阵的秩可能会减小。为了解决这一问题,Focused Linear Attention引入了秩恢复模块,通过应用额外的深度卷积来恢复注意力矩阵的秩,从而保持不同位置的输出特征多样化。
-
线性复杂度(Linear Complexity):与Softmax注意力相比,Focused Linear Attention具有线性复杂度,使得可以更高效地处理大规模数据,扩展感受野到更大的区域,同时保持相同的计算量。这使得模型能够更好地捕捉长距离的依赖关系,同时在各种视觉任务中表现出色。
核心代码
class FocusedLinearAttention(nn.Module):def __init__(self, dim, num_patches, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1,focusing_factor=3, kernel_size=5):super().__init__()assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."# 初始化参数self.dim = dimself.num_heads = num_headshead_dim = dim // num_heads# 定义查询q的线性层self.q = nn.Linear(dim, dim, bias=qkv_bias)# 定义键k和值v的线性层,输出维度是2倍的dimself.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)# 定义注意力的dropout层self.attn_drop = nn.Dropout(attn_drop)# 定义输出投影的线性层self.proj = nn.Linear(dim, dim)# 定义输出投影的dropout层self.proj_drop = nn.Dropout(proj_drop)# 缩小比例参数self.sr_ratio = sr_ratioif sr_ratio > 1:# 定义卷积层用于缩小特征图的大小self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)# 定义层归一化层self.norm = nn.LayerNorm(dim)# 聚焦因子self.focusing_factor = focusing_factor# 定义深度可分离卷积层self.dwc = nn.Conv2d(in_channels=head_dim, out_channels=head_dim, kernel_size=kernel_size,groups=head_dim, padding=kernel_size // 2)# 定义缩放参数self.scale = nn.Parameter(torch.zeros(size=(1, 1, dim)))# 定义位置编码参数self.positional_encoding = nn.Parameter(torch.zeros(size=(1, num_patches // (sr_ratio * sr_ratio), dim)))print('Linear Attention sr_ratio{} f{} kernel{}'.format(sr_ratio, focusing_factor, kernel_size))def forward(self, x, H, W):B, N, C = x.shape# 计算查询qq = self.q(x)# 如果缩小比例大于1,进行特征图的缩小操作if self.sr_ratio > 1:x_ = x.permute(0, 2, 1).reshape(B, C, H, W)x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)x_ = self.norm(x_)kv = self.kv(x_).reshape(B, -1, 2, C).permute(2, 0, 1, 3)else:kv = self.kv(x).reshape(B, -1, 2, C).permute(2, 0, 1, 3)k, v = kv[0], kv[1]# 加入位置编码到键kk = k + self.positional_encodingfocusing_factor = self.focusing_factorkernel_function = nn.ReLU()scale = nn.Softplus()(self.scale)q = kernel_function(q) + 1e-6k = kernel_function(k) + 1e-6q = q / scalek = k / scaleq_norm = q.norm(dim=-1, keepdim=True)k_norm = k.norm(dim=-1, keepdim=True)q = q ** focusing_factork = k ** focusing_factorq = (q / q.norm(dim=-1, keepdim=True)) * q_normk = (k / k.norm(dim=-1, keepdim=True)) * k_norm# 重新排列q、k、v的形状以匹配多头注意力机制q = q.reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)k = k.reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)v = v.reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)# 计算注意力得分z = 1 / (q @ k.mean(dim=-2, keepdim=True).transpose(-2, -1) + 1e-6)kv = (k.transpose(-2, -1) * (N ** -0.5)) @ (v * (N ** -0.5))x = q @ kv * z# 如果缩小比例大于1,对值v进行插值操作if self.sr_ratio > 1:v = nn.functional.interpolate(v.permute(0, 2, 1), size=x.shape[1], mode='linear').permute(0, 2, 1)H = W = int(N ** 0.5)x = x.transpose(1, 2).reshape(B, N, C)v = v.reshape(B * self.num_heads, H, W, -1).permute(0, 3, 1, 2)x = x + self.dwc(v).reshape(B, C, N).permute(0, 2, 1)# 通过输出投影层和dropout层x = self.proj(x)x = self.proj_drop(x)return x
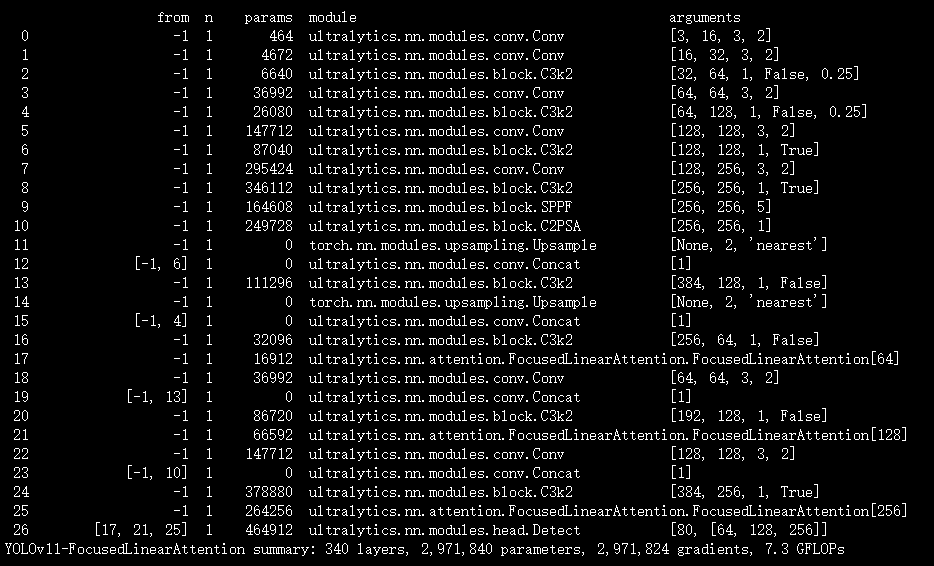
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-FocusedLinearAttention.yaml')
# 修改为自己的数据集地址model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='SGD',amp=True,project='runs/train',name='FocusedLinearAttention',)结果