摘要:多Agent协作是AI工程师面试的高频考点,也是实际工程中的难点。
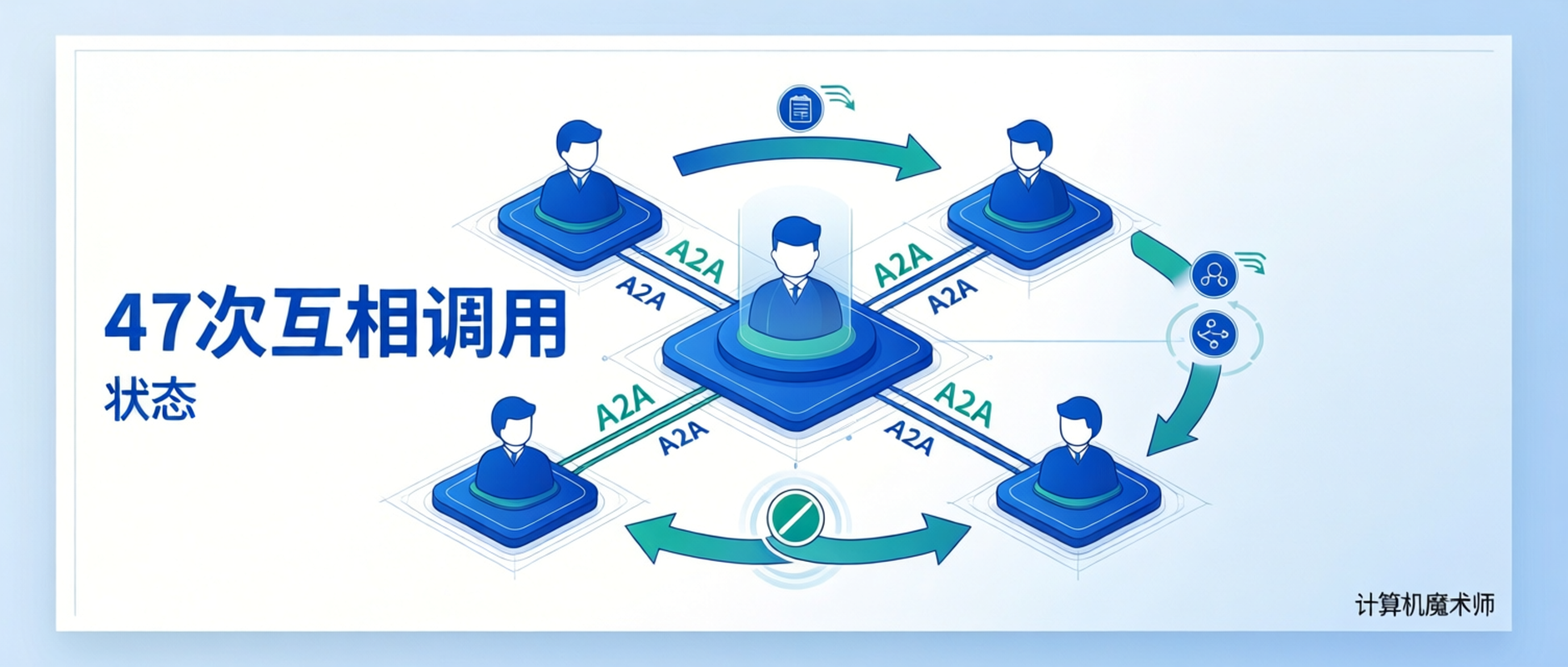
测试环境里跑得好好的多Agent系统,一上预发就开始疯狂打日志。SRE群里弹出告警:「服务A和服务B在10分钟内互相调用了47次,CPU打满」。
复盘的时候才发现,一个任务拆分之后没有做循环检测,Worker B完成任务后又把结果抛给了自己,又触发了一次新的任务分发——死循环了,只不过不是代码while(true),而是Agent之间的调用图闭环。
47次告警,群里沉默了30秒才有人说话
这是真实发生过的翻车现场,也是AI工程师面试里多Agent协作相关题目的原始素材。
面试官之所以爱问这个方向,不是在考你知道多少框架名字,而是看你对「多个LLM实例在一起工作时会发生什么」有没有真实的工程认知。
从注册发现、任务分发、A2A协议到状态共享和循环检测,这套体系里的每一个环节都有面试官可以追问的深度。
什么是Agent注册发现机制:为什么Orchestrator能找到对的Worker
多Agent系统的第一个工程问题不是「怎么协作」,而是「怎么互相找到」。
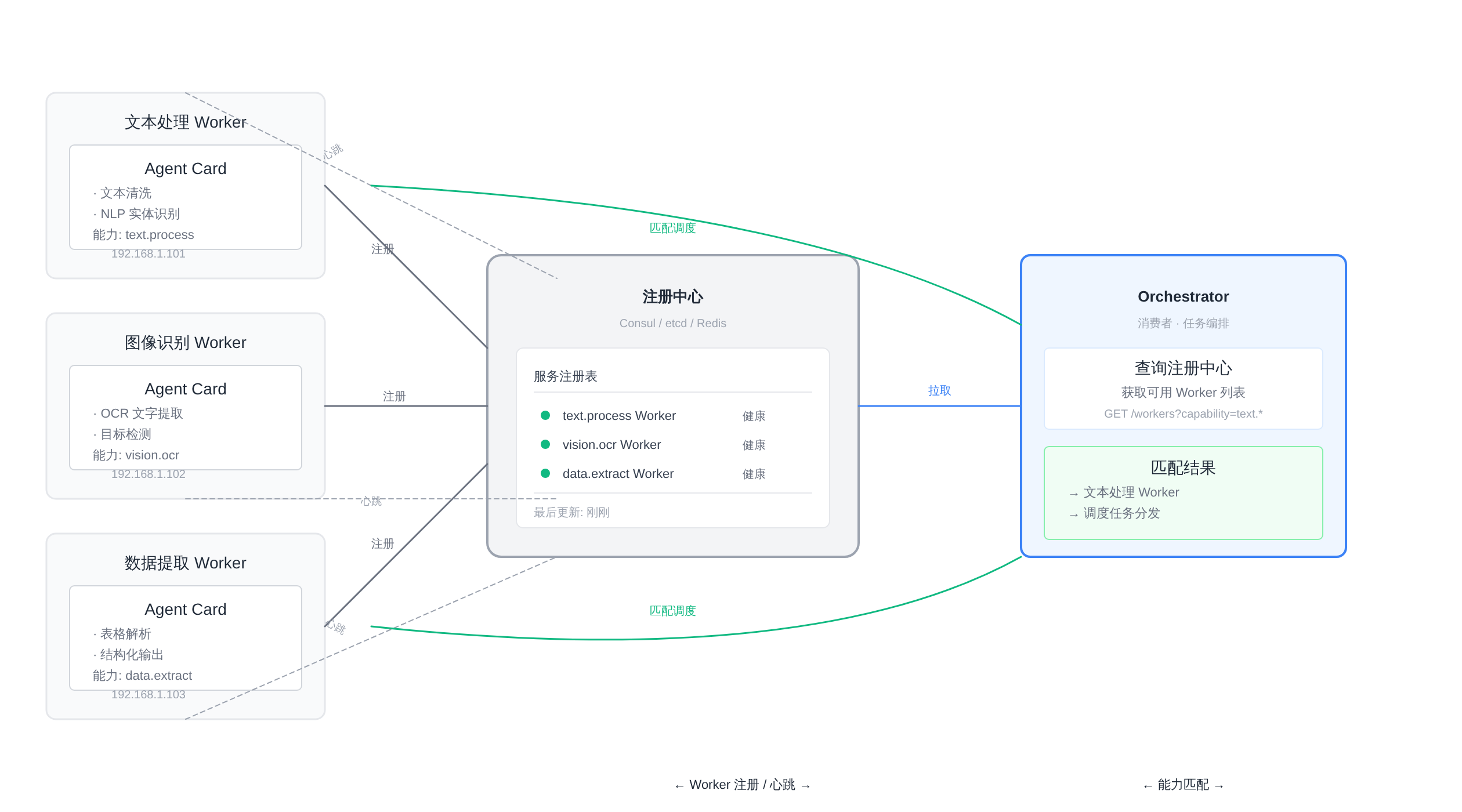
Orchestrator在拆解完任务之后,得先知道有哪些Worker在场、每个Worker能干什么、它们的地址和状态是什么——这套机制就是Agent注册发现。
注册发现的三层架构
工业级的注册发现通常拆成三层:
第一层是注册中心 ,扮演服务目录的角色。Worker启动时把自己的能力描述、API端点和认证信息写进去;
Orchestrator启动时从注册中心拉取完整的可用Worker列表。常见的实现有Consul、etcd,或者直接用Redis的有序集合加上TTL。
第二层是能力描述层 。Worker不能只注册「我在」,还要注册「我能干什么」。
这通常通过Agent Card实现——一个结构化的JSON文档,包含这个Agent擅长的任务类型、模型配置、调用约束和认证要求。
Agent Card是A2A协议里的核心元数据单位,也是后面会详细讲的A2A协议的消息头来源。
第三层是健康检查层 。注册不是一次性动作,Worker需要定期上报心跳,注册中心负责清理超时未响应的实例。
如果Worker是长时任务执行者,还需要支持部分状态上报(比如「正在执行任务T,进度60%」),让Orchestrator在分发时能避开已经满载的节点。
正文图解 1
生命周期状态上报与健康检查
Worker的生命周期通常分成五个状态:注册态 (刚上线,还没完成初始化)、就绪态 (已完成初始化,可以接收任务)、忙碌态 (正在执行任务)、降级态 (过载或部分能力不可用)和注销态 (主动下线或被动超时移除)。
状态上报有两种常见模式。一种是拉模式 :注册中心定期轮询Worker的健康检查接口,Worker只需要暴露一个/health端点即可。
这种模式实现简单,但对短时Worker不友好。另一种是推模式 :Worker主动上报心跳到注册中心,注册中心维护一个本地租约(lease),过期即剔除。
对于需要上报中间执行状态的长任务,推模式更合适。
面试时经常被追问的一个细节是:如果注册中心本身挂了怎么办?标准答案是本地缓存 + 降级策略 。
Orchestrator在本地缓存一份最近一次拉取的Worker列表,注册中心不可用时继续使用缓存,同时降低任务分发的并发度,避免把任务发到已经不在线的Worker上。
面试现场怎么解释「注册发现」
面试官问注册发现,本质上是在试探你对分布式系统基础的理解是否扎实。
30秒开口版的逻辑是:先给一句话定义「注册发现解决的是Orchestrator怎么找到合适的Worker」,再给一个类比「就像微服务里的服务发现」,最后补一个关键细节「关键是Agent Card里的能力描述,这是A2A协议的基础」。
如果面试官追问得更深,比如「注册中心和Agent Card具体怎么实现」,你可以从Redis sorted set存能力标签、Consul的service mesh集成、或者直接用PostgreSQL的JSONB字段存Agent Card这三个方向里选一个展开,取决于你实际项目里用过哪个。
不要贪多选三个都说,会显得你没有主次。

面试官:那你实际项目里用的是什么注册中心?
Orchestrator-Worker模式:任务分发、结果聚合与两种Reduce策略
注册发现解决的是「能找到谁」的问题,接下来要解决的是「怎么把活分下去」和「结果怎么收回来」。
Orchestrator-Worker模式是当前最主流的多Agent协作架构,核心思想是一个Orchestrator负责任务拆分和结果聚合,多个Worker各自执行子任务并返回结果 。
任务拆分的粒度控制:为什么不能拆太细
任务拆分的粒度是整个Orchestrator-Worker模式里最考验设计能力的环节。拆得太粗,每个Worker还是得处理复杂任务,协作优势消失;
拆得太细,Orchestrator的调度开销和结果聚合成本会变成新的瓶颈。
一个经验性的判断标准是子任务的执行时间应该在30秒到5分钟之间 。如果一个子任务预计只需要几秒就跑完,说明粒度拆得太细,Orchestrator调度开销占比过高;
如果预计需要超过10分钟,说明粒度太粗,应该考虑能否把数据依赖解耦后再拆分。
另一个维度是数据依赖关系 。任务图里如果有强依赖的两个节点(比如B必须等A的输出),强行并行只会增加复杂度。
正确的做法是先用拓扑排序把任务图理清,把可并行的节点分组,再交给Orchestrator分发。
Worker执行模型与超时策略
Worker的执行模型通常有三种:同步阻塞 (Orchestrator等待单个Worker返回再继续)、异步非阻塞 (Orchestrator同时向多个Worker发任务,通过回调或轮询收集结果)和流式返回 (Worker边执行边yield中间结果)。
大多数实际场景用的是异步非阻塞,兼顾吞吐和可操作性。
超时策略是工程里最容易出问题的环节。常见的三层超时设置是:
单任务超时 :单个Worker执行子任务的最大允许时间,通常根据任务预估时间乘以1.5到2倍的系数。
如果超时,Orchestrator认为该Worker失效,触发重试或降级逻辑。聚合窗口超时 :Orchestrator等待所有子任务返回的最大时间。
如果超时,按已完成的结果进行聚合,未完成的任务标记为失败。这个超时通常设为单任务超时的1.5倍。
整体任务超时 :整个Orchestrator任务的deadline,通常由上游业务调用方传入。
如果整体超时,Orchestrator需要立即返回当前最优结果或错误信息,而不是继续等待。
⚠️ 踩坑提醒 :很多新手会忽略「部分超时」的场景。如果5个子任务里有2个超时了,Orchestrator应该怎么处理?继续等待还是按3个结果聚合?
这里的决策直接影响用户体验和系统行为,必须在设计阶段明确,而不是留到线上踩坑。
LLM Reduce vs 规则合并:什么时候用什么
当多个Worker返回了各自的子任务结果,Orchestrator需要把它们聚合成一个最终答案。这个聚合过程有两种主流策略:
LLM Reduce 指的是把子任务结果拼成一个prompt,喂给一个专门的Reducer LLM,让它理解、消化、然后输出整合后的结论。
这种方式的最大优势是语义理解能力强 ,适合结果本身有语义关联、不能简单拼接的场景。
比如三个Worker分别搜索了竞品A、竞品B、竞品C的功能对比,Reducer LLM可以理解「这三家都在强调易用性,但角度不同」,从而给出一个结构化的对比分析而不是三段独立文字。
规则合并 指的是用确定性规则把结果按某种结构拼接起来。
常见的规则包括:取并集(三个列表合并去重)、取交集(只保留三个Worker都认同的结论)、加权排序(根据Worker的置信度打分综合排名)和结构对齐(把结果映射到统一的数据schema)。
规则合并的优势是可预测性强、延迟低、不依赖额外的LLM调用成本 ,但语义理解能力为零。
实际工程里,大多数场景先用规则合并做快速聚合,再用LLM Reduce做语义升华 。
具体来说:先用规则合并生成一个中间结构(比如排序后的结果列表),如果结果数量在可接受范围内,再调用一次LLM做最终综合。这样既控制了LLM的token消耗,又保留了语义整合能力。
典型追问:聚合失败怎么处理
面试官在聚合策略上最爱追问的场景是「部分Worker失败了怎么聚合」。这个问题没有标准答案,考的是你对系统边界条件的思考。
常见的处理思路有三种。第一种是悲观策略 :任何一个Worker失败就整体失败,适用于强一致性要求的场景,比如金融交易编排。第二种是阈值策略 :设置一个容忍失败的比例,比如30%,只要失败数不超过阈值就按比例聚合结果。第三种是降级策略 :主聚合失败时,降级到一个预设的兜底结果,比如返回「部分任务执行失败,以下为可用结果」。
面试时选哪种策略不重要,重要的是你能说出「我选这个策略的原因是什么」。如果你做过实际的系统,描述你当时的决策过程;如果没做过,描述你见过的实际案例是怎么处理的。面试官要听的不是结论,是你思考的过程。

面试官:等等,你刚才说LLM Reduce会消耗额外token,那成本怎么控制?
下一部分会继续展开A2A协议规范、跨Agent状态共享的三种架构模式和循环检测的工程实现。这些内容构成多Agent协作的完整知识体系,掌握之后面对面试追问就能游刃有余。
A2A协议规范:Agent之间怎么「说话」
Orchestrator-Worker模式解决的是「一个主导者怎么把任务分配给多个执行者」的问题。

看到这里,人先沉默了
但在真实系统里,Worker之间经常需要直接通信——A需要通知B任务完成了,B需要问C要一个中间结果。
这种Worker对Worker的通信需求催生了A2A(Agent-to-Agent)协议。
A2A协议的核心设计目标是让不同框架、不同服务商、不同实现语言构建的Agent能够互相通信 ,而不用依赖一个中心化的Orchestrator来中转。
A2A协议的消息头三层结构
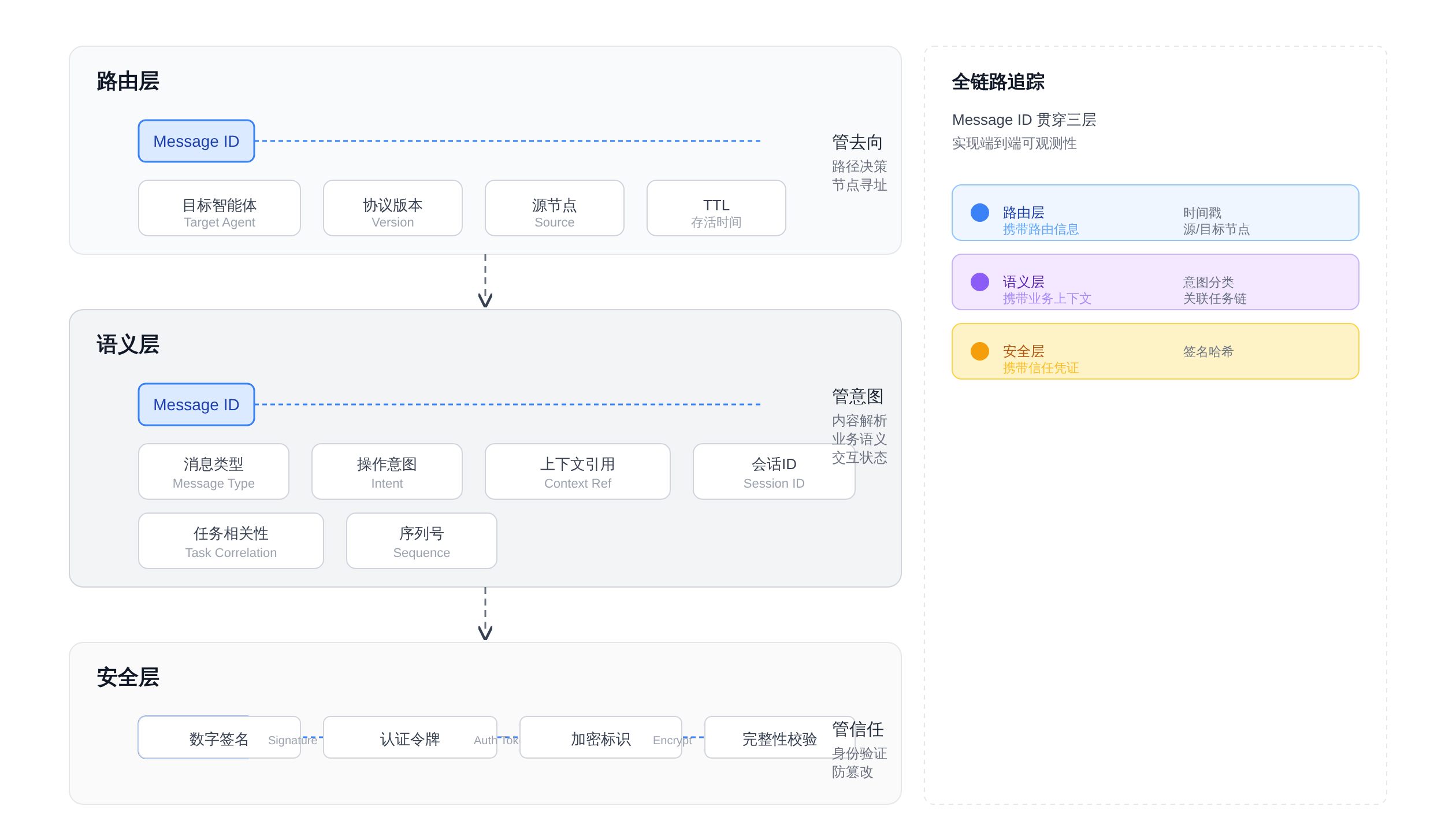
一个标准的A2A消息头包含三层结构,自上而下是路由层、语义层和安全层 。路由层 负责最基本的「消息去哪」。
这一层包含目标Agent的标识符(通常是一个Agent Card ID或URN)、源Agent的返回地址、以及一个全局唯一的Message ID用于幂等去重。
路由层的设计哲学是「尽力而为」:如果目标Agent不存在,路由层负责返回NACK(negative acknowledgement),而不是让消息石沉大海。
语义层 负责「这个消息想干什么」。
这一层定义了消息的类型(Task Dispatch、Result Return、Status Update、Error Report、Heartbeat等)和消息体内携带的业务上下文。
语义层的关键设计决策是:业务上下文应该用结构化JSON还是用自然语言描述?
Google的A2A协议(是的,Google也有一个A2A提案)偏向结构化JSON,而Anthropic和OpenAI的内部实现更偏向自然语言形式的Task Description。
两种选择各有利弊:结构化JSON可解析但需要预定义schema,自然语言灵活但依赖LLM做理解。
安全层 负责「这条消息可不可信」。这一层包含源Agent的签名、目标Agent要求的认证令牌、以及消息体加密标识。
安全层在A2A协议里容易被忽视,但在企业级部署里是不可跳过的合规要求——如果两个Agent分属不同安全域,A2A消息需要携带跨越域边界的身份委托凭证。
正文图解 2
Agent Card元数据:Capabilities、Endpoint与Auth
Agent Card是A2A协议的元数据基础,每个Agent在注册到发现系统时同时发布自己的Agent Card。
Agent Card本质上是一个结构化文档,描述了这个Agent的「我是谁、我能做什么、怎么找到我、信任我需要什么」这四个问题。
一个完整的Agent Card通常包含以下字段:
-
capabilities :这个Agent能处理的任务类型列表,比如
["code-review", "test-generation", "security-scan"]。这是Orchestrator做匹配决策的核心依据。 -
endpoint :Agent的通信地址,支持HTTP、WebSocket或gRPC。如果Agent支持流式返回,endpoint需要标注
streaming: true。 -
auth :访问这个Agent需要的认证方式,常见选项包括
Bearer Token、mTLS、OAuth2 Client Credentials等。 -
model_config :Agent使用的模型配置,包括模型名称、上下文窗口大小、最大输出token数。这个字段帮助Orchestrator在做任务拆分时预估执行时间。
-
rate_limits :这个Agent的调用频率限制,比如
requests_per_minute: 30。Orchestrator在并发分发任务时需要尊重这个限制,避免触发限流。
Agent Card的存储位置取决于注册中心的选择。如果用Consul,可以用K-V存储;如果用etcd,可以存在对应key下;
如果用Redis,Agent Card通常序列化为JSON存在Hash结构里。
Orchestrator-Worker vs A2A:什么时候选哪种协作模式
这是面试里出现频率最高的A2A追问:「Orchestrator-Worker和A2A有什么区别,什么时候选哪个?」
本质上,Orchestrator-Worker是星型拓扑 ,有一个中心节点负责调度;A2A是网状拓扑 ,Agent之间可以直接通信。选哪个取决于场景复杂度。Orchestrator-Worker适合 的场景:任务拆分的拓扑是树形的(比如MapReduce风格)、Orchestrator需要统一聚合结果、容错策略由中心统一控制。
典型场景包括批量文档处理、多阶段数据分析流水线、以及「一个主任务拆成若干子任务执行」的固定范式。
A2A适合 的场景:任务拓扑是动态的(不是预先定义好的树,而是运行时才知道谁需要和谁通信)、Agent之间的交互是双向的(不只是Orchestrator→Worker,还包括Worker→Worker的通知和回传)、需要支持Agent之间的自然语言对话(比如研究Agent向工具Agent描述任务细节)。
典型场景包括多Agent辩论系统、动态工具编排和实时状态同步。
实际系统里,Orchestrator-Worker和A2A不是互斥的,是嵌套的 。
通常的设计是:Orchestrator负责任务分发,用的是Orchestrator-Worker模式;Worker之间在执行过程中用A2A做状态同步和信息交换。
这样既保留了中心调度的可控性,又释放了Agent之间的灵活性。

面试官:那我能不能把所有Agent都设计成纯A2A,不需要Orchestrator?
技术上可以,但你会失去两个关键能力:一是全局调度视图——Orchestrator能看清楚全局任务图,决定哪些子任务可以并行、哪些需要等待依赖;
纯A2A系统里每个Agent只知道自己和谁通信,没有全局视野。
二是统一的超时和容错控制——Orchestrator可以对所有Worker设置相同的超时策略、失败重试和熔断规则,纯A2A系统里这些逻辑会散落在每个Agent的实现里,难以保证一致性。
典型追问:A2A协议与MCP协议的区别是什么
这个问题在2026年的面试里出现频率急剧上升,因为Anthropic的MCP(Model Context Protocol)和Google/OpenAI的A2A提案正在同时推进,面试官想看你对这两个协议体系的理解深度。
MCP(Model Context Protocol) 解决的是「模型和应用工具之间的通信规范」——它定义了LLM怎么调用工具、工具怎么返回结果、上下文怎么维护。
MCP的核心场景是单Agent模式下的工具调用,协议设计是请求-响应式的,适合有明确调用者和被调用者身份的场景。
A2A(Agent-to-Agent Protocol) 解决的是「Agent和Agent之间的通信规范」——它定义的是对等实体之间怎么发现彼此、交换任务、通知状态变化。
A2A的核心场景是多Agent协作,协议设计支持双向通信、异步通知和流式返回。两者的核心差异 可以归纳为两点:第一,MCP是「主从模式」,调用方和被调用方身份固定;
A2A是「对等模式」,两个Agent可以互为调用方和被调用方。第二,MCP设计时没有考虑多Agent协作里的循环检测、状态共享和动态发现,A2A是为这些场景设计的。
在工程实现里,MCP和A2A是互补的 。
一个设计良好的多Agent系统通常这样分层:用A2A做Agent之间的任务分发和状态同步,用MCP做每个Agent内部调用具体工具和外部服务。两者各司其职,不是非此即彼的关系。
跨Agent上下文传递:状态共享的三种架构模式
多Agent协作里最容易被忽视的工程问题,是上下文传递的代价 。
当Worker A执行到一半,需要把自己的中间状态传给Worker B继续处理,这个「传什么、怎么传、传多快」的问题,直接决定系统的吞吐和延迟上限。
当前主流的三种状态共享架构,分别对应不同的延迟代价和一致性边界。
共享内存模型:Redis与分布式缓存
共享内存模型是最直接的状态共享方案。Orchestrator或Worker把执行过程中的关键状态写入一个共享的内存存储(通常是Redis),其他Agent需要时从这个存储里读取。
延迟表现 :本地Redis通常是亚毫秒级(0.2-1ms),跨机房Redis通常在5-15ms。
这个延迟对大多数AI任务来说是可以接受的,因为LLM本身的推理延迟通常在秒级,远高于状态共享的开销。一致性模型 :Redis提供最终一致性,写入后立即可读。
对于需要强一致性的场景(比如金融交易编排),可以在写入后同步等待一个确认消息(WAIT命令),但这会显著增加延迟。
适用场景 :子任务的中间结果需要被其他Worker快速读取、状态更新频率高但一致性要求不是绝对严格、Agent运行在同一个机房或可用区内的场景。
一个常见的工程坑是:过度依赖Redis做状态共享导致Redis成为单点瓶颈 。
如果每个Worker都高频读写Redis,在大规模并发下Redis的QPS会先于LLM推理成为系统瓶颈。
解决方案是分层缓存:本地内存缓存热点数据,只把需要跨节点共享的状态写到Redis。
消息队列模型:Kafka与事件溯源
消息队列模型的核心思想是把状态变化变成一系列事件,而不是直接读写共享存储。每个Worker在执行过程中发布事件,其他Agent订阅自己需要的事件。
延迟表现 :Kafka的端到端延迟通常在10-50ms,相比Redis慢了1-2个数量级。
但Kafka的优势是可以做事件回溯——如果Worker B想重新执行某个历史步骤,可以从Kafka里重新消费之前的事件流,而Redis里的状态是覆盖式的,历史数据丢失。
一致性模型 :Kafka提供的是「至少一次」语义(at-least-once delivery)。如果需要精确一次(exactly-once)语义,需要在消费端做幂等处理。
这个权衡在大多数AI任务场景里是可以接受的,但在需要强一致性的场景里需要注意。
适用场景 :需要完整执行日志用于回放和审计、执行流程需要支持「重试历史步骤」的场景、状态变化需要被多个下游Agent订阅的场景。
事件溯源(Event Sourcing)模式和多Agent编排的结合是当前的一个工程热点方向。
向量存储模型:Embedding共享与语义检索
向量存储模型解决的不是「状态共享」而是「上下文共享」——当Worker A生成了一段文本结果,Worker B需要从这段文本里找到和自己任务相关的部分,而不是把整段结果都传过去。
延迟表现 :向量检索的延迟通常在20-100ms(包括Embedding生成和向量搜索),比Redis慢但比Kafka快。
延迟的主要来源是Embedding模型的推理时间,而不是向量检索本身——大多数向量数据库的检索延迟都在毫秒级。一致性模型 :向量存储通常不做实时一致性同步,更新有延迟。
对于需要强一致性的语义检索场景,需要在写入向量存储后等待索引刷新完成才能被检索到,这个延迟可能是几秒到几十秒不等。
适用场景 :当子任务的结果是大量非结构化文本、后续Worker需要从历史结果中检索相关内容、上下文窗口不够需要做选择性读取的场景。
向量存储模型在RAG(Retrieval-Augmented Generation)场景里用得最多,和多Agent协作的交叉点在于:当Worker B需要参考Worker A的历史输出时,不是简单传递原文,而是通过向量检索找到最相关的片段。
三种模式的延迟代价与一致性边界对比
| 架构模式 | 端到端延迟 | 一致性模型 | 最大并发瓶颈 | 适用场景 |
|---|---|---|---|---|
| Redis共享内存 | 0.2-15ms | 最终一致(可同步确认) | Redis QPS | 高频状态读写、同机房 |
| Kafka消息队列 | 10-50ms | At-least-once | Kafka Broker吞吐 | 事件回溯、审计、多订阅 |
| 向量存储检索 | 20-100ms | 弱一致(有索引延迟) | Embedding模型吞吐 | 非结构化上下文、选择性读取 |
这个对比表在面试现场说出来,比背概念有说服力得多。面试官问你「Redis和Kafka的区别」,你把延迟数字和一致性模型摆出来,对方就知道你不只是看过文档,而是做过实际取舍。
典型追问:如果Worker B需要Worker A的中间结果,怎么设计降级方案
这是一个典型的工程边界条件追问。Worker A执行到一半,Worker B需要接入继续处理,但Worker A的状态还没完全落库或者还没发布完整事件——这个时候怎么处理?
方案一是流式传递(Streaming Intermediates) :Worker A在执行过程中通过A2A协议实时把中间结果推送给Worker B,不需要等A完全执行完。
这个方案需要A2A协议支持流式消息,Orchestrator在分发任务时需要告知B「A会向你推送中间结果」。实现复杂度高,但延迟最低。
方案二是检查点回放(Checkpoint Replay) :Worker A在执行过程中定期把检查点写入Redis或发布到Kafka,Worker B可以从最近的检查点继续。
这种方案牺牲了一点实时性,但实现简单,且支持故障恢复——如果A崩溃了,B可以从检查点恢复而不需要从头开始。
方案三是降级等待(Fallback Wait) :如果中间结果传递不可用,让B等待A完成后通过Orchestrator聚合结果。
这是最保守的方案,但保证了正确性——如果实时传递不可靠,等待完整结果总比拿到不完整的中间状态然后处理出错了重来要好。
工程里通常的做法是先尝试流式传递,传递失败时降级到检查点回放,再降级到等待完整结果 。三个层次的降级策略,保证系统在各种边界条件下都能有合理的行为。

面试官:流式传递听起来很好,但你怎么保证Worker B收到中间结果时A还没崩溃?
关键在于幂等设计 :Worker B在处理中间结果时,需要假设A可能会崩溃重试,因此每个中间结果都要有版本号或序列号,B需要能判断「这个中间结果我是否已经处理过了」。
这个机制类似于Kafka Consumer Group的offset管理,只是你要管理的不是消息偏移量,而是执行序列号。
下一部分会继续展开循环检测的DFS实现与面试口语化表达模板,并给出完整的参考文献与复习路径。
循环检测:调用图DFS防止Agent A→B→A死循环
为什么是调用图DFS而不是计时器
「测试环境里47次互相调用」是怎么发生的?
正常情况下,Orchestrator分发给Worker A,Worker A调用Worker B,Worker B返回结果。链路清晰,树形拓扑,没有循环。
但当A2A协议引入Agent之间的直接通信时,链路就可能变成环:Worker A调用Worker B,Worker B在处理过程中发现需要某个工具,调用工具Agent C,C在特定条件下回调A——如果缺乏检测机制,这条链路会在LLM的非确定性决策下反复触发,直到超出资源限制。
计时器为什么不够用?因为计时器只能检测「这次调用是否超时」,无法判断「这条调用链是否正在形成循环」。一个合理的调用可能需要30秒,一个形成死循环的调用链也恰好需要30秒——从耗时上看完全无法区分。
调用图DFS(深度优先搜索)才是正确的工具。它的核心思路是:在每次Agent间调用发生前,检查当前调用链里是否已经出现过目标Agent。如果出现过,说明正在形成循环,拒绝本次调用。
class CycleDetector:def __init__(self, max_depth: int = 10):self.max_depth = max_depthself.call_chain: list[str] = [] # 当前调用链def before_invoke(self, caller: str, callee: str) -> bool:"""返回True表示允许调用,False表示拒绝(检测到循环)"""# 如果callee已经在当前调用链里,说明会形成循环if callee in self.call_chain:return False# 将callee加入调用链self.call_chain.append(callee)return Truedef after_invoke(self, callee: str):"""调用完成后,从调用链移除这个Agent"""if self.call_chain and self.call_chain[-1] == callee:self.call_chain.pop()def check_depth(self) -> bool:"""检查调用深度是否超出限制"""return len(self.call_chain) <= self.max_depth
这个实现有几个关键细节:
调用链栈化 :每次调用前把callee入栈,调用完成后出栈。
这样 call_chain 始终反映当前活跃的调用路径,不包括已经返回的路径——只有活跃路径上的循环才是真正的循环。
深度限制 :即使没有形成严格意义上的环(比如A→B→C→D→B,严格来说只有B重复),过长的调用链本身也说明任务拆分粒度失控。max_depth 就是这道闸门。非递归实现 :上面这个实现是伪递归的,看起来像栈操作,但在并发场景下需要加锁。
更工程化的做法是每个请求维护独立的调用链上下文,用 contextvars 或请求级别的字典存储,避免全局状态的竞争问题。
检测阈值设置:最大调用深度与时间窗口
max_depth = 10 是LangChain Multi-Agent框架里的默认值,但这个数字不是银弹。
设置 max_depth 的依据是任务的合理拆分层数 。一个需要分5层的任务,max_depth 设为10就足够了;
一个理论上可以无限递归的任务(比如「研究A,A又引用B,B又引用A的相关内容」),需要根据业务容忍度设上限,通常在8-12之间。
超过这个阈值的常见原因:
任务拆分粒度失控 :Orchestrator把一个本该在一个Worker里完成的任务拆成了十几个子任务,每个子任务之间又有依赖关系,最终调用链超出预期。LLM生成了非预期的工具调用 :最典型的场景是RAG任务里,检索Agent发现检索结果不够,返回了一个「需要进一步检索」的信号,如果Orchestrator把这个信号当成新任务分发给另一个检索Agent,而这个Agent恰好又调用了原来的检索Agent——循环就这样形成了。
时间窗口 是另一个辅助检测维度。如果同一个调用对在短时间内(比如30秒内)被调用了N次(比如3次),即使没有形成完整的环,也说明系统处于异常状态。
这个指标通常叫 调用频率热图 ,可以用滑动窗口算法维护:
from collections import defaultdict
from datetime import datetime, timedeltaclass FrequencyTracker:def __init__(self, window_seconds: int = 30, max_calls: int = 3):self.window = timedelta(seconds=window_seconds)self.max_calls = max_callsself.calls: dict[tuple[str, str], list[datetime]] = defaultdict(list)def record(self, caller: str, callee: str) -> bool:"""记录一次调用,返回True表示正常,False表示频率异常"""key = (caller, callee)now = datetime.now()# 清理过期记录self.calls[key] = [t for t in self.calls[key]if now - t < self.window]self.calls[key].append(now)return len(self.calls[key]) <= self.max_calls
DFS检测循环,频率追踪检测「准循环」——两者组合才能覆盖真实的异常调用模式。
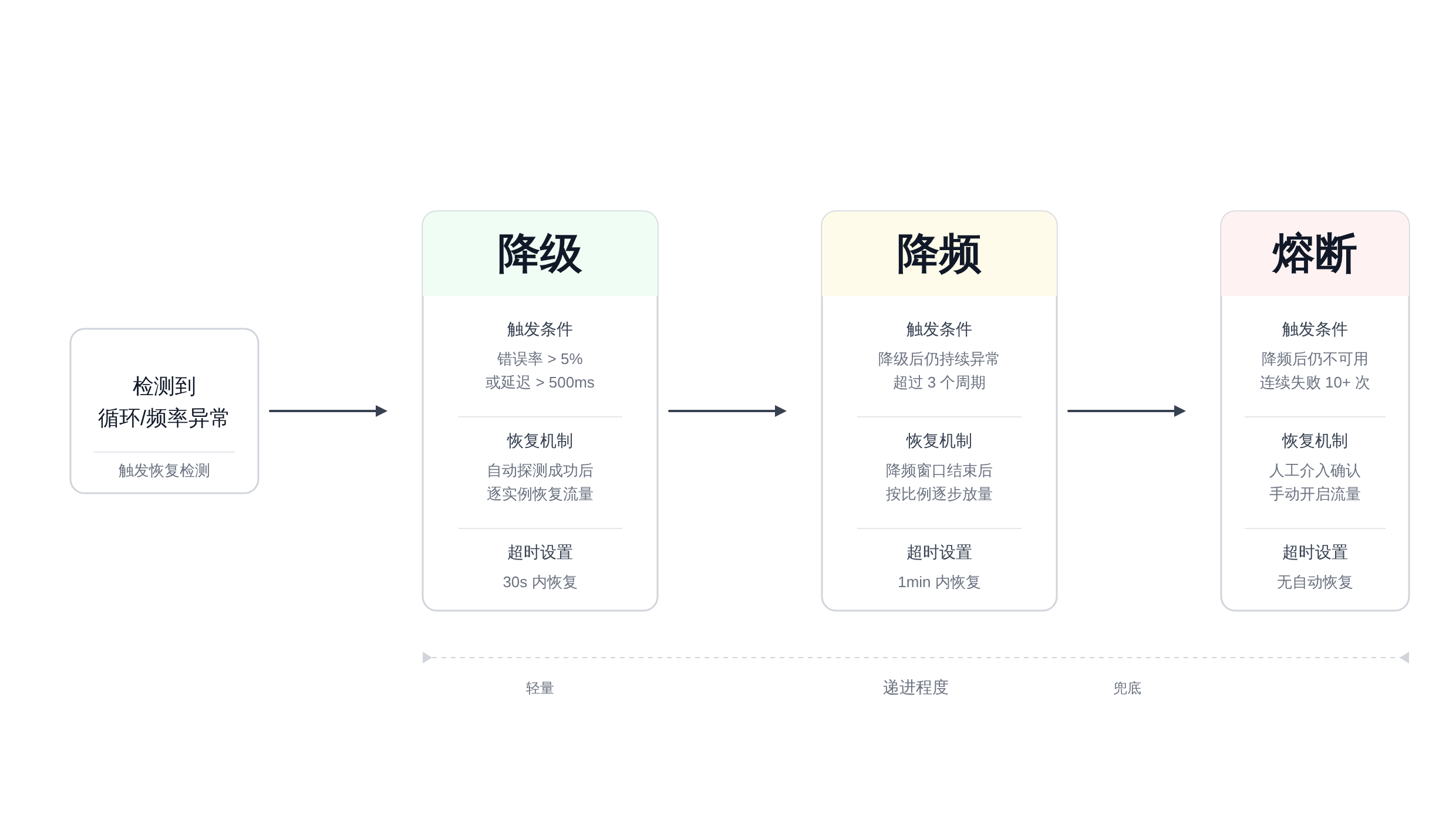
恢复策略:降级、降频与熔断
检测到循环或异常频率之后,系统不能只是「拒绝调用然后报错」。
对于多Agent系统,一个子任务的失败如果处理不当,会导致整个任务链回滚——这才是测试环境里「47次调用」真正可怕的地方:每次重试都重新触发调用链,又被DFS拒绝,又重试,直到资源耗尽。
降级(Degrade) :当检测到循环时,不拒绝调用,而是让当前Agent返回一个「已知结论」而不是继续调用下游。
最典型的场景是搜索任务形成循环:Agent B发现自己在调用A,而A的结果已经在上下文中存在,直接返回上下文里的结果,而不是继续调用。
降级的代价是可能拿到过期数据,但至少系统不会死锁。
降频(Rate Limit) :当检测到频率异常时,不完全拒绝调用,而是降低调用速率。
比如从「立即调用」降级为「等待500ms后重试」,并且在等待期间把请求放入队列,防止并发风暴。降频比降级温和,适用于「调用本身是合理的,只是频率超出了系统承载」的场景。
熔断(Circuit Breaker) :当降级和降频都无法阻止异常时,彻底熔断这条调用链。
熔断后,Orchestrator会标记这个子任务为「不可用」,在后续的聚合阶段跳过它,或者用预设的兜底结果替代。
熔断的关键参数是「恢复窗口」——熔断多久后允许一次试探性调用,试探成功则关闭熔断,试探失败则延长熔断时间。
正文图解 3
这三级的设计原则是:先止血,再观察,后熔断 。降级让系统在循环里快速退出,不消耗额外资源;降频让系统在恢复过程中控制节奏;熔断是在所有努力都失效后保护系统不被拖垮的最后防线。

面试官:如果每次降级都返回旧数据,系统最后会不会收敛到一个完全错误的结论?
会的。这正是多Agent系统的「静默失败」问题:降级策略让系统看起来在正常运行,实际上结果已经被污染了。
工程上通常的做法是降级后标记数据来源 :每个降级结果打上「降级数据」标签,最终聚合时Orchestrator可以看到每个子结果是否经过降级,如果是关键路径上的降级数据,可以在聚合报告中标注「置信度下降」,让业务层决定是否接受这个结果。
面试口语化解释模板(30秒开口版)
面试里被问到「循环检测怎么实现」,不需要现场画架构图,核心是说清楚两件事:检测逻辑是什么,发现之后怎么处理。
参考回答(30秒版):
「循环检测用调用图DFS实现。每次Agent间调用发生前,我会在当前请求的调用链里检查目标Agent是否已经存在——如果存在就拒绝这次调用,防止形成A→B→A的环。同时我会维护一个调用深度限制,比如最多10层,超过这个深度就认为任务拆分出了问题,同样拒绝。检测到循环之后有三层处理:先降级,返回已有的缓存结果;如果降级不可行就降频,控制调用节奏;最后才是熔断,跳过这个子任务。这样既防止了死循环,又保证了系统在异常状态下还能继续运行。」
这个回答覆盖了:检测手段(DFS + 深度限制)、恢复策略(三级递进)和设计原则(防止死锁但不阻断正常流程)。30秒内能说完,面试官追问「DFS怎么实现」「降级和降频的区别」都有展开空间。
面试官追问:调用链怎么保证线程安全?如果两个并发请求同时在改调用链怎么办?
工程实现里,每个请求(或者每个Orchestrator实例)维护独立的调用链上下文。
Python可以用 contextvars ,Go可以用请求级别的Context,Java可以用 ThreadLocal ——核心思路是一样的:调用链不放在全局变量里,而是绑定在请求生命周期上。
这样两个并发请求各有各的调用链,互不干扰。
面试应答与项目落地:从「背概念」到「能开口讲清楚」
30秒快速应答结构:先结论,后机制
面试多Agent协作类题目,最常见的失败模式不是「不知道」,而是「说得太散」。
候选人的典型回答:
「嗯这个多Agent协作,首先得有注册发现机制,然后Orchestrator负责任务分发,Worker负责执行,过程中需要状态共享,可以用Redis或者Kafka,然后如果有循环的话需要检测……」
这个回答把六个关键词都提到了,但面试官听完会问:「所以你的核心观点是什么?」
正确的结构是先结论,后机制 。三句话之内让面试官知道你的判断是什么,然后再展开为什么。
参考结构(30秒快答版):
「多Agent协作的核心挑战是可控性 ——让多个LLM驱动的Agent在没有人盯着的情况下正确分工、不死循环、有合理的容错。我的设计是:以Orchestrator-Worker为主模式做任务分发,用A2A协议处理Agent之间的状态同步,用Redis或Kafka做状态共享,用DFS做循环检测,配合三级降级策略。选Redis还是Kafka取决于一致性要求——高并发读选Redis,需要事件回溯选Kafka。」
这30秒里说了:核心判断(可控性)、主模式(Orchestrator-Worker)、辅助协议(A2A)、状态共享方案(三选一)、循环检测和恢复策略。没有一个词是废话。
三个典型追问防御:聚合策略、A2A vs Orchestrator、循环检测
面试官追问多Agent协作,通常集中在三个方向,每个方向都有固定的防御路径:
追问一:LLM Reduce和规则合并的区别,什么时候选哪个?
核心判断是「是否需要LLM做语义理解」。规则合并适合结果结构化、格式统一、可以写确定性的合并逻辑;
LLM Reduce适合结果是非结构化文本、需要语义去重或优先级排序、规则无法穷举所有合并情况的场景。
工程里通常是先用规则合并快速处理结构化部分,把需要语义理解的模糊部分交给LLM Reduce——分层处理,而不是非此即彼。
追问二:什么时候用Orchestrator-Worker,什么时候用纯A2A?
核心判断是「任务拓扑是否在编译期已知」。任务拓扑固定、可以画成树的,选Orchestrator-Worker;任务拓扑运行时动态变化、Agent之间需要双向通信的,选A2A。
工程里两者通常嵌套使用:Orchestrator分发任务用Orchestrator-Worker,Worker之间同步状态用A2A。
追问三:循环检测具体怎么实现,检测到之后怎么办?
参考前文的30秒快答模板。DFS + 深度限制做检测,三级降级(降级→降频→熔断)做恢复。追问如果深入到「线程安全」「如何避免误杀合理的长调用链」,顺着前文的实现细节展开。
项目表达模板:如何在简历和面试里描述多Agent项目
简历上写「参与过多Agent系统开发」是无效的——这句话没有传递任何有价值的信息。
有效的项目描述需要包含:场景、挑战、方案、结果 四个要素。参考模板:
项目名称 :多Agent客服系统(2025.06-2025.10)
场景 :日均处理10万次用户咨询,需要同时调用商品检索、订单查询、物流跟踪和退换货四个后端服务。
挑战 :初期采用纯A2A架构,Agent之间平均调用深度达到6.8层,有12%的请求触发死循环检测后直接失败,平均响应时间超过15秒。
方案 :重构为Orchestrator-Worker主模式 + A2A辅助同步,新增DFS循环检测(深度限制8层,频率窗口30秒内最多3次),三级降级策略。
结果 :死循环触发率从12%降至0.3%,平均响应时间降至3.2秒,p99从28秒降至7秒。
这个描述里,每一个数字都是可以追问的入口:「为什么选8层不选10层」「降级策略具体怎么实现的」「0.3%的死循环剩下的0.3%怎么处理」——面试官顺着数字问,候选人顺着数字答,比背概念有说服力得多。
易错边界清单:这些坑面试官最爱问
易错点一:混淆Orchestrator-Worker和A2A的定位
Orchestrator-Worker是任务分发模式,A2A是通信协议,两者不在同一抽象层次,不应该被对立比较。
正确的问题是:「我的任务分发用Orchestrator-Worker,Agent之间状态同步用A2A,这样可以吗?」而不是「我应该用Orchestrator还是A2A?」
易错点二:把状态共享和上下文传递混为一谈
状态共享解决的是「多个Agent共享同一个变量的值」,上下文传递解决的是「把一个Agent的输出作为另一个Agent的输入」。
Redis/Kafka解决的是状态共享,向量存储解决的是上下文传递(选择性传递)。混用会导致设计决策失误。
易错点三:循环检测只看深度,不看频率
只检查调用深度的系统,会漏掉「A→B→C→B」这种不完全相同的调用对重复出现的异常。只检查频率的系统,会漏掉「深度突然从3跳到20」这种拓扑失控。两者必须同时存在。
易错点四:降级策略不考虑数据污染
降级返回旧数据,如果不在结果里标注「降级数据」,最终聚合时可能会把过期的旧结论当成新鲜结论提交给用户。生产环境里,降级标签是必须有的。

这些坑我在上一个项目里踩过,所以面试时特别愿意讲——讲踩坑比讲成功更能体现判断力
参考文献与复习路径
1: LangChain Multi-Agent Documentation: Orchestrator-Worker Pattern — https://python.langchain.com/docs/how-to/multi-agent-orchestrator/
2: AI Engineering Field Guide: AI System Design — https://github.com/alexeygrigorev/ai-engineering-field-guide/blob/main/interview/questions/04-ai-system-design.md
3: Anthropic MCP (Model Context Protocol) Official Documentation — https://modelcontextprotocol.io/
4: BAND Startup: Universal Orchestrator for Agent-to-Agent Communication (VentureBeat, 2026-04-23) — https://venturebeat.com/orchestration/talking-to-ai-agents-is-one-thing-what-about-when-they-talk-to-each-other-new-startup-band-debuts-universal-orchestrator
5: Multi-Agent System Security: Prompt Injection and Agent-on-Agent Commerce (TechCrunch, Anthropic Project Deal) — https://techcrunch.com/2026/04/25/anthropic-created-a-test-marketplace-for-agent-on-agent-commerce/
复习路径建议 :
-
入门 :先把Orchestrator-Worker的执行链路在白纸上画一遍,确保能讲清楚任务是怎么分、结果是怎么合的。
-
进阶 :把A2A协议和MCP协议的适用场景做对比表格,能在面试里快速说出区别和联系。
-
工程 :找一个具体的多Agent开源项目(如LangChain的multi-agent-examples),跑通循环检测的测试用例,理解DFS检测的边界条件。
-
面试冲刺 :把本文的「30秒快答模板」和「项目表达模板」各练习三遍,确保能在3分钟内把多Agent协作的核心要素全部覆盖,且没有遗漏关键追问的展开空间。
参考文献
-
Multi-agent- Docs by LangChain
-
AI 工程师 Field Guide:AI system design(面试准备) - system design for AI applications
-
New Research Shows AI Agents Are Running Wild Online, With Few Guardrails in Place
-
Talking to AI agents is one thing — what about when they talk to each other? New startu...
-
Anthropic created a test marketplace for agent-on-agent commerce
延伸入口
- 原文归档:https://tobemagic.github.io/ai-magician-blog/posts/2026/05/11/ai面试八股文-vol16-agent多agent协作模式orchestratorworkera2a状态共享和循环检测一篇讲透/
- 公众号:计算机魔术师
