一直以来,你都能盯着 loss 曲线看;TraceML 让你看见训练循环内部的效率。
在每个训练步骤内部,时间究竟是如何在数据加载、前向、反向和优化器之间分配的,你其实并不清楚。在查看训练运行时,工程师常用的工具链大致是这样:
nvidia-smi和集群仪表盘,用于查看 GPU 利用率- W&B、MLflow 或 TensorBoard,用于查看 loss 曲线和运行历史
- PyTorch Profiler 或 Nsight Systems,用于需要深入检查的场景
这些工具都有用,但在"任务正在运行"和"打开一个重量级 profiler"之间还缺了一层:正常训练期间、step 粒度的轻量级可见性,并且只需要极少的配置。
系统监控看到的是机器;实验追踪器看到的是结果;深度 profiler 看到的是 kernel 和 timeline,前提是你已经怀疑了某个具体问题,并且愿意承担相应的开销。
但如果只是想知道,在任意一次运行中,时间是如何在训练 step 内部分配的,又该怎么办?
这正是 TraceML 提供的能力。
TraceML 集成只需少量代码改动。把训练 step 标记一次:
import tracemltraceml.init(mode="auto")for batch in dataloader:with traceml.trace_step(model):optimizer.zero_grad(set_to_none=True)outputs = model(batch["x"])loss = criterion(outputs, batch["y"])loss.backward()optimizer.step()
然后运行:
traceml run train.py
把训练 step 标记一次,TraceML 把这个边界变成结构化的诊断信息:TraceML 利用 step 边界,把时序、内存、rank、进程和系统信号组织起来,整合成一份关于"运行把时间浪费在了哪里"的诊断。
任务运行时,TraceML 会在日志旁边打开一个实时终端视图。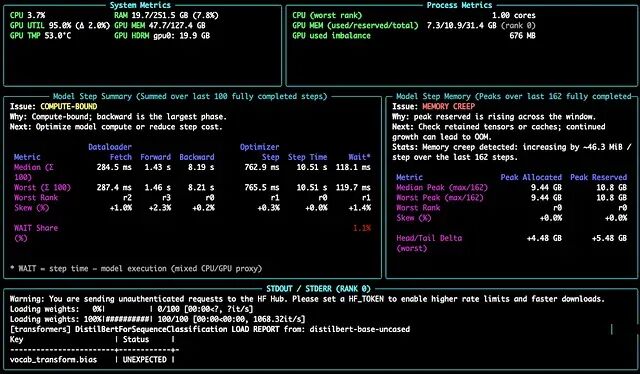
在一次 PyTorch 训练运行上的实时仪表盘。这次运行被判定为 compute-bound(计算受限),反向传播占据了 step 时间的主要部分,内存面板则提示在观察窗口内 reserved memory 持续增长。
https://avoid.overfit.cn/post/a05ff94b3d7c4dab83f0197d801b3917