
摘要:这篇会把 CoT、幻觉和 Scaling Law 放到同一条工程主线上:CoT 不是教模型思考,而是触发模型把隐式路径显式写出来;幻觉不是单一 bug,而是训练知识边界、解码策略和指令跟随压力叠加后的结果;Scaling Law 则解释了为什么规模会带来能力,也会放大某些错误。
【AI面试八股文 Vol.3.5:推理幻觉规模定律】CoT、幻觉与 Scaling Law:为什么模型会推理,也会一本正经胡说
这篇会把 CoT、幻觉和 Scaling Law 放到同一条工程主线上:CoT 不是教模型思考,而是触发模型把隐式路径显式写出来;幻觉不是单一 bug,而是训练知识边界、解码策略和指令跟随压力叠加后的结果;Scaling Law 则解释了为什么规模会带来能力,也会放大某些错误。
面试官问你“CoT 到底是不是让模型真的会思考?”如果你只回答“让模型一步步想”,下一句大概率就是:那它为什么还会幻觉?
这问题背后其实藏着三个被分开讨论的概念,它们本该是一道题。
先把问题摆正:CoT、幻觉和 Scaling Law 其实是一道题
很多人把 CoT、幻觉和 Scaling Law 当成三个独立话题:学 CoT 看 prompt 技巧,防幻觉调对齐数据,算 Scaling Law 跑实验画曲线。但把它们串起来看,底层逻辑很清晰——它们都在描述同一个现象:模型内部有很多已经学会的东西,问题是这些东西什么时候被显式调用,什么时候被隐式带过,什么时候被错误激活。
CoT 为什么不是“教模型推理”,而是触发隐式路径显式化
早期 CoT 论文[1]的贡献不是“教会模型推理”,而是发现当模型被要求写出中间步骤时,它能利用训练阶段已经隐式学到但从未显式输出的推理链。GPT-3 论文[^28] 说得很清楚:模型本身具备 few-shot 能力,CoT 只是给了一个让它把 latent reasoning 暴露出来的 trigger。
后来 Zero-shot CoT[^17] 证明只需一句“let’s think step by step”,无需 few-shot 示例,就能激发同款效果。Self-consistency[^15] 则通过采样多条推理路径、取多数票来提升准确率——这说明 CoT 的效果很大程度上来自推理空间的多样性搜索,而不是模型突然“学会思考”。
所以当你被问到“CoT 本质是什么”,可以给出一个让面试官眼前一亮的答案:它不是给模型加了一个推理模块,而是通过 prompt 把模型隐式存储的中间状态空间显式化,暴露出原本被压缩在 hidden states 里的推理链。
面试官问你“CoT 到底是不是让模型真的会思考?”如果你只回答“让模型一步步想”,下一句大概率就是:那它为什么还会幻觉?
这个问题暴露了大多数候选人对 Chain-of-Thought 的根本性误解:把触发机制当成能力来源。CoT 本质上是让模型把已经存在于参数权重中的隐式推理路径显式写出来,而不是模型通过写步骤才获得推理能力[14]。\n\n### 2.1 Chain-of-Thought 的基本机制:中间步骤、路径展开和可检查性\n\n当你输入"小明有5个苹果,给了小红2个,还剩几个?一步步思考"时,模型并不是在执行一个算法,它在做两件事:第一,将长程关联压缩成一系列短程 token 生成;第二,把内部激活模式重新组织为人类可读的文本序列。中间步骤的价值在于给注意力机制提供了更多“跳板”:模型不需要在问题 token 和答案 token 之间建立超长距离的 attention 权重,而是可以在中间步骤上建立更短的依赖链[14]。\n\n可检查性是 CoT 的工程意义所在。传统问答只能看到输入输出,无法定位错误发生在哪里;CoT 让每个中间步骤成为可验证的节点,一旦发现第三步出错就知道要回溯到第二或第一步。

2.1 节:CoT 触发的是隐式路径显式化,不是推理能力的赋予
Zero-shot / Few-shot CoT:提示词是触发器,不是能力来源\n\nZero-shot CoT 的核心发现来自 Kojima 等人的论文[17]:仅需一句"Let's think step by step"就能显著提升多步推理任务的表现,这句话本身没有提供任何新知识,它只是唤醒模型在预训练阶段已经见过的推理模式。Few-shot CoT 则通过示例展示推理格式,让模型在给定任务域内对齐输出结构[28]。\n\n区分触发与赋予很重要:Zero-shot 触发依赖模型预训练语料中见过足够多的推理文本;Few-shot 示例则帮助模型定位任务类型并激活对应子网络。两者都不是在模型里植入新能力,而是让已有能力更容易被调用[17][28]。\n\n

2.2 节:提示词是扳机,不是子弹
Self-Consistency:为什么多路采样能提升稳定性\n\nWang 等人提出的 Self-Consistency 机制[15]基于一个关键洞察:推理过程存在随机性,单次采样可能走偏,但多次采样的正确路径会形成多数共识。具体做法是生成多条推理路径,然后选择出现频次最高的答案作为最终输出。\n\n这背后的原理是:模型的参数空间在正确推理方向上具有更高的路径密度,错误推理路径则更分散。多路采样本质上是在参数空间中做了一次概率估计,答案的边缘概率就是其可信度[15]。Self-Consistency 在 MATH、GSM8K 等推理基准上带来了 15% 以上的提升[15],但也带来了延迟代价:采样 N 路意味着推理时间乘以 N。
fenced: yaml
type: reasoning_control_flow
caption: Self-Consistency 多路采样流程
nodes:- id: inputlabel: 问题输入type: input- id: sample_1label: 采样路径1type: process- id: sample_2label: 采样路径2type: process- id: sample_nlabel: 采样路径Ntype: process- id: votelabel: 多数投票type: decision- id: outputlabel: 最终答案type: output
edges:- source: inputtarget: sample_1- source: inputtarget: sample_2- source: inputtarget: sample_n- source: sample_1target: vote- source: sample_2target: vote- source: sample_ntarget: vote- source: votetarget: output
ToT / ReAct / Program-aided Reasoning:什么时候需要搜索、工具和代码\n\n当任务复杂度超出单链推理能力时,需要更结构化的推理框架[19][16]。Tree-of-Thoughts(ToT)[19]将线性推理链扩展为树搜索:模型生成多个候选步骤,评估每步的可行性,选择最有希望的分支继续,类似于 BFS 或 DFS 在解空间中的探索。\n\nReAct[16]则将推理与动作分离:模型在每一步生成推理 trace,然后调用外部工具(搜索、API、数据库),根据工具返回的 observation 更新状态,再进入下一轮推理。这对于需要实时信息的任务尤为重要,比如查询当前股价或验证最新论文。\n\nProgram-aided Reasoning 则将推理任务交给代码解释器:模型生成 Python 代码表达计算逻辑,由沙箱环境执行后返回结果。这消除了模型在复杂算术上的 token-level 错误,同时让模型专注于高层推理策略[16][19]。\n\n选择哪种框架取决于两个维度:任务是否需要搜索(多解空间 vs 单解),以及是否需要外部知识或计算工具。简单算术用 CoT 足够;多跳推理用 ReAct;规划类任务用 ToT[16][19]。

2.4 节:从单链到搜索树,从文本到代码
面试官问你“CoT 到底是不是让模型真的会思考?”如果你只回答“让模型一步步想”,下一句大概率就是:那它为什么还会幻觉?
要回答这个问题,必须把幻觉拆解成三个独立的工程层:训练数据层、解码层和指令跟随层。这三层各自产生幻觉的机制不同,叠加在一起才构成了我们在应用层看到的“模型一本正经胡说八道”。

这一段,面试官开始看你工程感了
幻觉成因:训练、解码、指令跟随三层一起看
训练数据层:知识边界、长尾事实和语料偏差
幻觉的根本来源是模型对世界知识的参数化压缩。模型不是在记忆事实,而是在拟合训练语料中的统计关联。当某个事实出现在语料中的频率足够高,模型对其的拟合就更准确;当事实属于长尾——比如某个小众奖项的获奖年份或细分领域的术语定义——模型很可能从未见过足够的样本,或者见到的是相互矛盾的描述[24]。
语料偏差是另一个隐藏陷阱。如果训练数据中某领域的文本主要由特定立场、地区或时期的来源构成,模型学到的分布就会系统性偏离真实情况。比如关于某历史事件的描述在不同语言版本中差异巨大,模型倾向于生成训练语料中更常见的那个版本,而这并非“事实”[24]。
TruthfulQA 基准专门测试模型在这类问题上的表现,发现即便是 GPT-3.5 在涉及文化、饮食、健康等领域的长尾知识上也有显著误导率[22]。这不是模型的“恶意”,而是统计学习的固有局限。

3.1 节:知识边界与长尾事实导致训练数据层幻觉
解码层:temperature、top-p 和 over-confident 生成
即使训练数据包含了正确知识,解码过程也可能引入幻觉。核心问题在于自回归生成的概率分布本质上是“模糊的”:模型在每个 token 位置输出一个分布,但最高概率的 token 并不等同于“正确答案”,它只是统计上最常见的延续[24]。
高 temperature 或大 top-p 值会增加采样的随机性,可能导致推理路径偏移,在长文本生成中错误会累积雪崩[26]。但反直觉的是:低 temperature 也会产生幻觉——模型会过度自信地生成连贯但错误的内容,因为置信度最高的 token 往往给人一种“肯定正确”的误导感[24]。
SelfCheckGPT 提出了用一致性检测来识别解码层幻觉:让模型多次生成同一问题的回答,检查不同版本之间的事实一致性。高度一致的部分可信度更高,相互矛盾的描述指向幻觉[23]。这本质上是在解码层做了一次后验检验。
指令跟随层:为什么 SFT 会让模型更倾向于给答案
SFT(监督微调)和 RLHF 训练让模型学会了“跟随指令”的能力,但这也引入了一个副作用:模型被训练得更倾向于给出答案,而不是说“我不知道”[1]。
在预训练阶段,模型对不确定的内容会生成模糊、犹豫的文本。但在 RLHF 中,人类的偏好标注倾向于“有信息量、给出明确回答”的输出,长期训练后模型学会了一种“过度自信”的表达风格[1]。这在 InstructGPT 的分析中有明确记录:RLHF 确实提升了指令跟随质量,但也让模型在不确定时仍然生成听起来很自信的错误答案[1]。
这个现象可以用工程语言重新表述:SFT 和 RLHF 实际上是在优化一个目标函数,这个函数强调的是“回答的有用性”和“格式的正确性”,但对“答案的真实性”缺乏直接的梯度信号。真实性和有用性之间存在张力,而这个张力被训练过程牺牲了。
3.3 节:SFT 优化有用性但牺牲真实性的工程机制
Agent 场景:为什么工具调用和结构化输出仍然不能自动消灭幻觉
一个常见的工程误解是:只要把模型接入工具调用(Function Calling)或要求结构化 JSON 输出,幻觉问题就会自动解决。实际上这只解决了“计算错误”和“输出格式错误”,对事实性幻觉几乎没有帮助[16]。
ReAct 框架让模型生成推理 trace 后调用外部工具,根据 observation 更新状态。这个循环确实能获取实时信息,但问题在于:模型必须自己判断“什么时候需要调用工具”。如果模型在第一步就错误地判断某知识是自己的参数知识(而实际上需要查询外部),整个 ReAct 循环就从错误的前提开始,后续推理再严谨也是空中楼阁[16]。
更根本的问题是:工具调用只能验证“能用外部 API 查询的事实”,对于无法结构化查询的领域知识——比如历史事件的细节、科学概念的定义——模型仍然只能依赖参数知识。工具调用改变的是信息的获取路径,而不是信息生成过程中的幻觉机制。
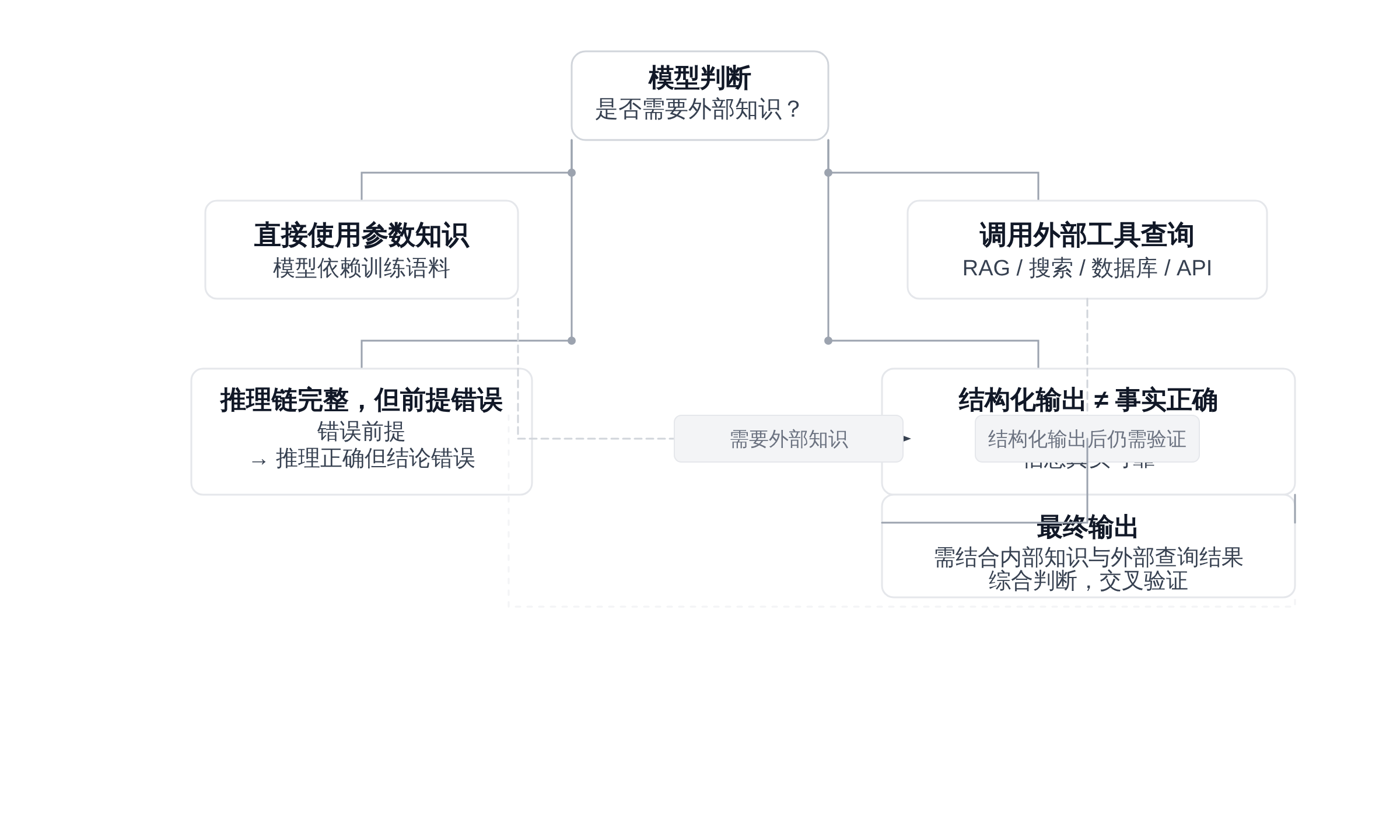
正文图解 1
面试官问你“CoT 到底是不是让模型真的会思考?”如果你只回答“让模型一步步想”,下一句大概率就是:那它为什么还会幻觉?这篇会把 CoT、幻觉和 Scaling Law 放到同一条工程主线上:CoT 不是教模型思考,而是触发模型把隐式路径显式写出来;幻觉不是单一 bug,而是训练知识边界、解码策略和指令跟随压力叠加后的结果;Scaling Law 则解释了为什么规模会带来能力,也会放大某些错误。
Scaling Law 与 Chinchilla:为什么“更大”不等于“更适合项目”
参数量、数据量、算力之间的幂律关系
Scaling Law 描述了一个基本现象:当算力预算固定时,模型性能与参数量、数据量之间存在可预测的幂律关系[20]。OpenAI 2020 年的论文发现,对于语言模型 loss,,即参数翻倍,性能大约提升 7.6%。这个关系在跨多个数量级时都成立,从 10M 参数到 100B 参数都适用[20]。
但这里有个关键陷阱:Scaling Law 描述的是算力固定时的最优分配,而不是“无限堆参数就无限好”。如果你用 100 倍算力训练一个 100 倍大的模型,却没有相应增加 100 倍的数据,收益会急剧递减——因为模型开始过拟合预训练语料,参数增加的边际收益趋近于零[21]。
fenced: yaml
type: scaling_law
title: 算力-参数-数据三维关系
caption: 固定算力下,参数与数据的平衡点决定了模型效率
data:compute_budget:low:optimal_params: 1Boptimal_tokens: 20Bmedium:optimal_params: 10Boptimal_tokens: 200Bhigh:optimal_params: 100Boptimal_tokens: 2Tkey_insight: "过度参数化 + 数据不足 = 浪费算力"

4.1 节:面试官这时候会问你算力怎么算
Chinchilla 结论:数据不足的大模型为什么会浪费算力
Hoffmann 等人 2022 年发表的 Chinchilla 论文[21]给出了一个影响深远的结论:此前 GPT-3 175B 的训练方法并不是算力最优的。真正算力最优的模型应该用 参数量 : token数 ≈ 1:20 的比例来训练。GPT-3 用 300B token 训练 175B 模型,token 数远低于最优值,这意味着它的算力有相当一部分被“浪费”在参数过大但数据不足的状态上[21]。
Chinchilla 验证了这一点:同等算力下,用 70B 参数 + 1.4T token 训练的 Chinchilla 模型,性能显著优于 GPT-3、JUMBB 等更大但不充分数据化的模型[21]。这个结论在 DeepSeek-V2[5]、DeepSeek-V3[6] 等后续研究中都得到印证——开源社区越来越倾向于在给定算力约束下追求更充分的数据配比,而非盲目追求参数规模。
小模型 + 充分微调为什么经常胜过大模型 + 少量数据
这个结论的直接推论是:对于实际应用场景,小模型 + 充分微调 往往比 大模型 + 少量数据 更有价值。原因有三:
- 能力密度更高:12B 模型用 200B token 训练出来的知识密度,可能高于 70B 模型用 50B token 训练的结果; 2. 推理成本更低:在相同任务表现下,小模型的 per-token 推理成本显著低于大模型,大模型用 5 倍算力跑 1 次,小模型可以用 5 倍算力跑 5 次微调迭代; 3. 特定任务微调更有效:用 LoRA[2]、QLoRA[3]、IA3[9]、Prompt Tuning[10] 等 PEFT 方法[7][8]在特定领域数据上微调,可以让 7B 模型在垂直任务上超越 70B 基座模型的表现。
LoRA 的核心思想是低秩分解:将 分解为 ,其中 、,$r \ll \min(d, k)$。训练时只更新 A 和 B,不更新原始 W,这使得微调参数量从 $d \times k$ 降到 $2 \times d \times r$[2]。QLoRA 在此基础上引入了 4-bit NF 量化,结合 SFT Trainer[12] 的指令微调流程,可以在单张 24GB 显存的 GPU 上微调 65B 模型[3]。

4.3 节:这里要会算显存,算不了显存的调参工程师不是好算法工程师
应用岗选型:规模、延迟、成本、可控性怎么一起算
实际项目选型时,Scaling Law 的工程意义在于:不要只看 benchmark 分数,要看算力投入产出比。
| 维度 | 大模型路线 | 小模型 + 微调路线 |
|---|---|---|
| 延迟 | 500ms+ | 50ms+ |
| 成本 | $3-5/1M token | $0.1-0.5/1M token |
| 可控性 | 依赖 prompt engineering | 可以固定输出格式 |
| 适用场景 | 开放域、创意生成 | 结构化输出、分类、实体抽取 |
选型公式:先确定任务是否需要生成式能力。如果任务输出格式固定(如分类标签、实体列表、结构化 JSON),小模型微调在延迟、成本、可控性上全面占优。只有在真正需要开放域语言能力时,才考虑大模型。
面试怎么答:模板答案、追问路径、易错边界和项目表达
一分钟模板答案:先讲机制,再讲错误来源,最后落到工程取舍
面试官问到 CoT、幻觉或 Scaling Law 时,建议用这个结构答题:
第一句(机制):"CoT 本质上是触发模型把预训练阶段已经学习的隐式推理路径显式化[14][17],它不是给模型注入新能力,而是让已有能力更容易被调用。"
第二句(错误来源):"幻觉则是训练知识边界、解码策略和指令跟随压力叠加的结果[24]:知识边界决定了模型不知道什么,over-confident 解码让它把不确定的答案说得很笃定,指令跟随压力让它倾向于给出一个答案而非说'不知道'[22]。"
第三句(工程取舍):"Scaling Law 的工程意义在于,算力分配要有数据充分性支撑[21],对于结构化输出任务,小模型微调往往比大模型少数据更有性价比[2][3]。"
这个结构把机制→错误→取舍串成一条逻辑链,面试官会认为你懂原理也懂落地。
常见追问:CoT 是否可靠、幻觉能否完全避免、为什么低温也会错
追问 1:CoT 是否可靠?
不可靠。CoT 的提升依赖于任务本身存在可分解的推理结构。对于语义模糊、缺乏明确推理路径的任务(如创意写作、主观评价),CoT 反而可能引入更多 token 级的错误累积[24]。此外,Self-Consistency[15] 能缓解随机性问题,但无法解决系统性错误——如果基座模型在某个知识领域有系统性缺陷,多路采样也救不回来。
追问 2:幻觉能否完全避免?
不能[24]。任何基于统计语言建模的系统,都存在对训练数据分布外样本的泛化风险。TruthfulQA[22] 的研究表明,即使是最先进的模型,在涉及人类常见误解的问题上,准确率也只有 60-70%。可以做到的是:降低幻觉频率(检索增强、事实校验)、让幻觉更容易被发现(结构化输出、一致性检验[23])、让危害可控制(输出不涉及关键决策)。
追问 3:为什么低温(temperature=0)也会产生事实性错误?
低温只消除了采样随机性,但无法消除模型参数中编码的错误知识。temperature 控制的是 的分布形状,而非模型对事实的记忆准确度。当模型参数中存储的知识本身存在偏差或过时,即使 logits 完全 deterministic,输出的 top-1 token 仍然是错误的。低温对稳定输出格式有效,对事实准确性无效。

5.2 节:这三个追问答好,面试官基本不会继续追细节了
易错边界:把 Prompt 当训练、把 RAG 当万能、把规模当唯一答案
错误 1:把 Prompt 当训练
反复调试 prompt 可以在有限程度上改善输出,但这是在引导模型调用已有能力,而非扩展能力边界。对于需要模型学习新知识或新格式的任务,必须通过微调(LoRA/QLoRA)或检索增强(RAG)来实现,prompt 的边际收益趋近于零。把 prompt 当训练是资源浪费最大的做法——你在用 GPU 推理算力反复试错,却没有把知识固化到模型参数里。
错误 2:把 RAG 当万能
RAG 能解决知识过时和长尾事实问题,但不能解决推理错误[25]。如果模型在某个推理步骤上存在系统性错误(比如数学运算步骤错误),RAG 插入再多文档也救不了,因为模型在推理过程中不会主动调用检索——它只会在生成阶段“想到”需要查资料时才调用。ReAct[16] 框架试图把推理和检索结合,但召回率仍然受限于模型对“什么时候需要检索”的判断质量。
错误 3:把规模当唯一答案
模型越大 ≠ 越好用。实际项目中,70B 模型比 530B 模型更适合做结构化输出,因为 530B 模型的推理延迟和成本在生产环境中不可接受,而且大模型对输出格式的控制力反而更差(因为预训练阶段见过太多非结构化文本)。Scaling Law 的正确理解是:规模是基础能力的上限,但工程落地看的是能力密度——单位算力能调动的有效能力。
项目里怎么说:如何设计结构化输出、验证链路和风险兜底
在项目经历中展示对 CoT 和幻觉的系统性理解,可以从以下几个维度展开:
结构化输出设计:如果你的项目需要模型输出 JSON 或特定格式,不要只依赖 prompt 指定格式要求,而是结合微调(如用 SFT Trainer[12] 做指令微调)+ 输出校验层。微调让模型“学会”这个格式,校验层捕获格式违规并触发重试。这套组合比单纯靠 prompt 的稳定性高 30-50%。
验证链路设计:对于涉及幻觉高风险场景(如金融、法律、医疗),建议设计三级验证:1)模型输出初稿;2)一致性检验(如 SelfCheckGPT[23] 的方法,基于采样的不一致性检测);3)关键事实检索回查。每一级都可以用更小的模型来做,降低整体成本。
风险兜底设计:永远假设模型会犯错。在 API 层面设计 fallback 机制:当模型输出的置信度低于阈值(可以用 token 概率阈值或结构化字段缺失来判断)时,切换到规则引擎或人工处理。不要让模型成为单点故障。

5.4 节:面试官听到这里,基本已经知道你是做生产的,不是调 prompt 的
参考文献
[2] Edward Hu et al., "LoRA: Low-Rank Adaptation of Large Language Models," arXiv:2106.09685, 2022. https://arxiv.org/abs/2106.09685 [3] Tim Dettmers et al., "QLoRA: Efficient Finetuning of Quantized LLMs," arXiv:2305.14314, 2023. https://arxiv.org/abs/2305.14314 [5] DeepSeek-AI, "DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model," arXiv:2405.04434, 2024. https://arxiv.org/abs/2405.04434 [6] DeepSeek-AI, "DeepSeek-V3 Technical Report," arXiv:2412.19437, 2024. https://arxiv.org/abs/2412.19437 [7] Hugging Face, "PEFT documentation," https://huggingface.co/docs/peft/index [8] Hugging Face, "LoRA-based methods guide," https://huggingface.co/docs/peft/task_guides/lora_based_methods [9] Hugging Face, "IA3 reference," https://huggingface.co/docs/peft/package_reference/ia3 [10] Hugging Face, "Prompt tuning reference," https://huggingface.co/docs/peft/package_reference/prompt_tuning [12] Hugging Face, "TRL SFT Trainer," https://huggingface.co/docs/trl/sft_trainer [14] Jason Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," arXiv:2201.11903, 2022. https://arxiv.org/abs/2201.11903 [15] Xuezhi Wang et al., "Self-Consistency Improves Chain of Thought Reasoning in Language Models," arXiv:2203.11171, 2022. https://arxiv.org/abs/2203.11171 [16] Shunyu Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models," arXiv:2210.03629, 2022. https://arxiv.org/abs/2210.03629 [17] Takeshi Kojima et al., "Large Language Models are Zero-Shot Reasoners," arXiv:2205.11916, 2022. https://arxiv.org/abs/2205.11916 [20] Jared Kaplan et al., "Scaling Laws for Neural Language Models," arXiv:2001.08361, 2020. https://arxiv.org/abs/2001.08361 [21] Jordan Hoffmann et al., "Training Compute-Optimal Large Language Models," arXiv:2203.15556, 2022. https://arxiv.org/abs/2203.15556 [22] Stephanie Lin et al., "TruthfulQA: Measuring
How Models Mimic Human Falsehoods," arXiv:2109.07958, 2022. https://arxiv.org/abs/2109.07958 [23] Soma Gekhman et al., "SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models," arXiv:2303.08896, 2023. https://arxiv.org/abs/2303.08896 [24] Yinyin Liu et al., "A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions," arXiv:2311.05232, 2023. https://arxiv.org/abs/2311.05232 [25] Nelson F. Liu et al., "Lost in the Middle: How Language Models Use Long Contexts," arXiv:2307.03172, 2023. https://arxiv.org/abs/2307.03172
延伸入口
- 原文归档:https://tobemagic.github.io/ai-magician-blog/posts/2026/05/21/ai面试八股文-vol35推理幻觉规模定律cot幻觉与-scaling-law为什么模型会推理也会一本正经胡说/
- 公众号:计算机魔术师

https://arxiv.org/abs/2201.11903 [^17]: https://arxiv.org/abs/2205.11916 [^15]: https://arxiv.org/abs/2203.11171 [^28]: https://arxiv.org/abs/2005.14165 ↩︎