作业一
核心代码与运行结果

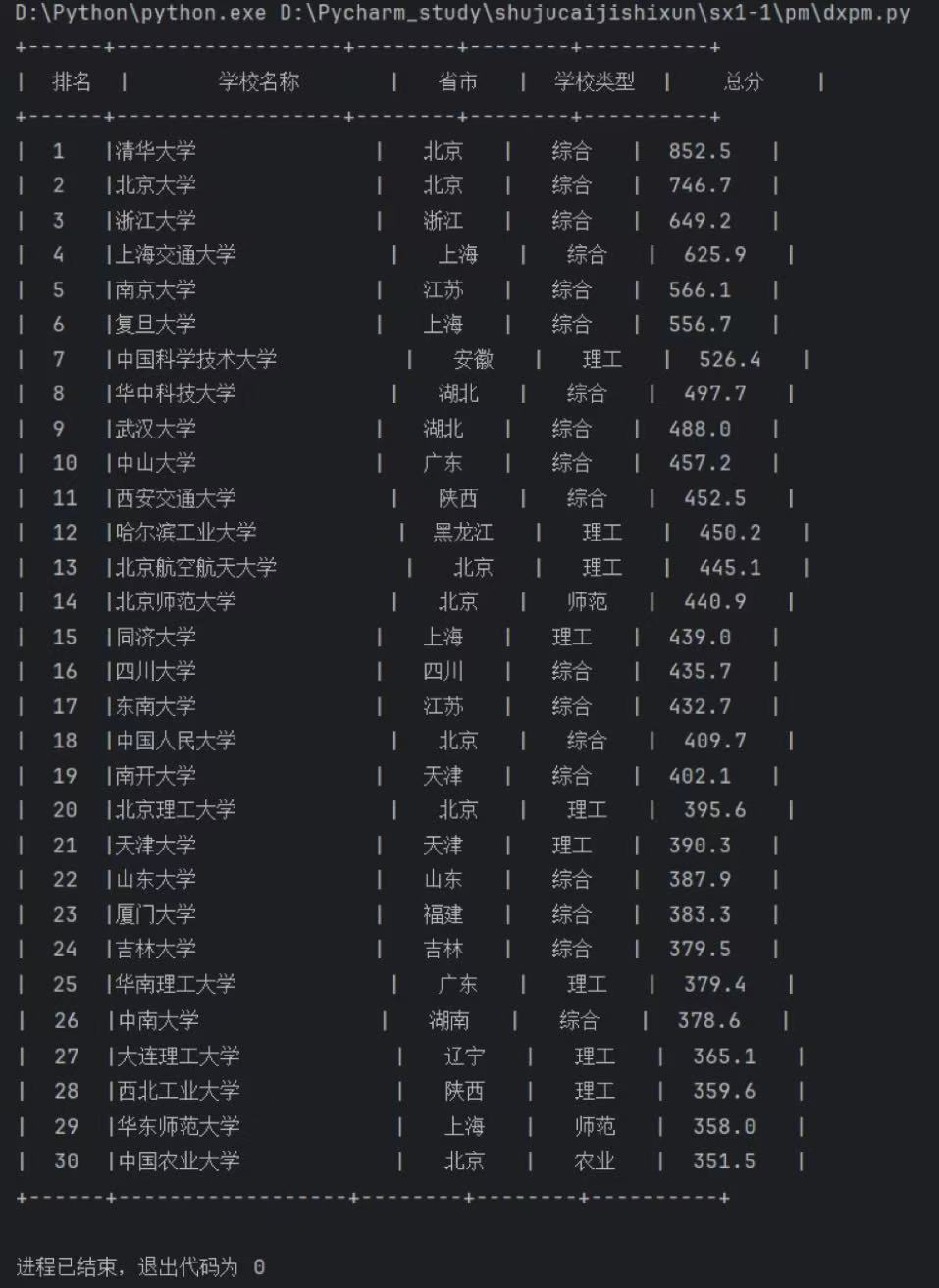
在写代码之前我先进入了该网页查看源代码的信息,了解了html的结构分布等,再进行代码的编写。代码首先用
requests发送 GET 请求,添加User-Agent模拟浏览器,避免反爬拦截;接着检查请求状态(raise_for_status()),设置utf-8编码解决中文乱码,用BeautifulSoup解析 HTML;然后通过class="rk-table"找到排名表格,筛选数据行(跳过表头);再遍历行数据,按单元格索引提取排名、学校名、省市、类型、总分,过滤字段不全的行;最后定义列宽,按表格样式打印数据,同时捕获网络和数据处理异常。实验过程中面临的核心难题,集中在网页标签的嵌套复杂程度与数据呈现的潜在差异上。提取学校名称时,发现部分院校信息同时包含专属中文标签(
div.name-cn)与英文名称,若直接获取单元格完整文本,会造成中英文信息混杂,无法得到纯净的学校中文名;此外,不同学校名称的字符长度差距明显,直接输出会导致表格排版混乱,且个别数据行存在单元格数量不足的情况,按固定索引提取 “省市”“总分” 等字段时,极易触发索引越界错误。通过优先定位并匹配中文标签、增加单元格数量校验步骤,再结合字符串格式化设定统一列宽,最终成功实现了排名数据的精准提取与规整展示。这次实验让我深刻体会到,网页数据爬取的稳定性与对页面结构的深度解析程度直接相关。只有充分掌握表格的列字段对应关系、标签的嵌套层级逻辑,才能高效、准确地抓取目标信息。同时还需预判页面可能出现的结构变动,比如标签 class 名称修改、列顺序调整等,提前设计灵活的处理方案来进行数据的爬取。 作业二
核心代码与运行结果(数据太多了只显示头和尾)
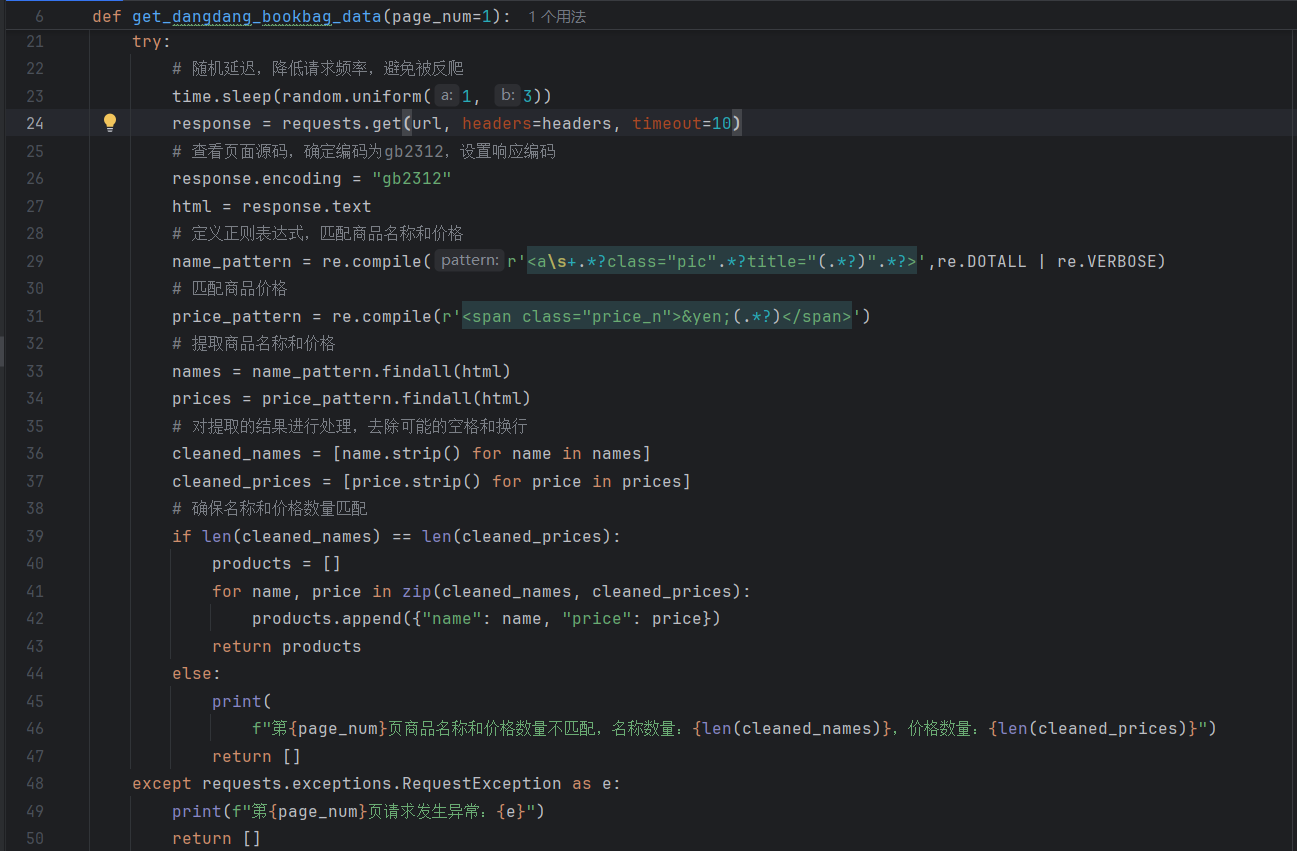
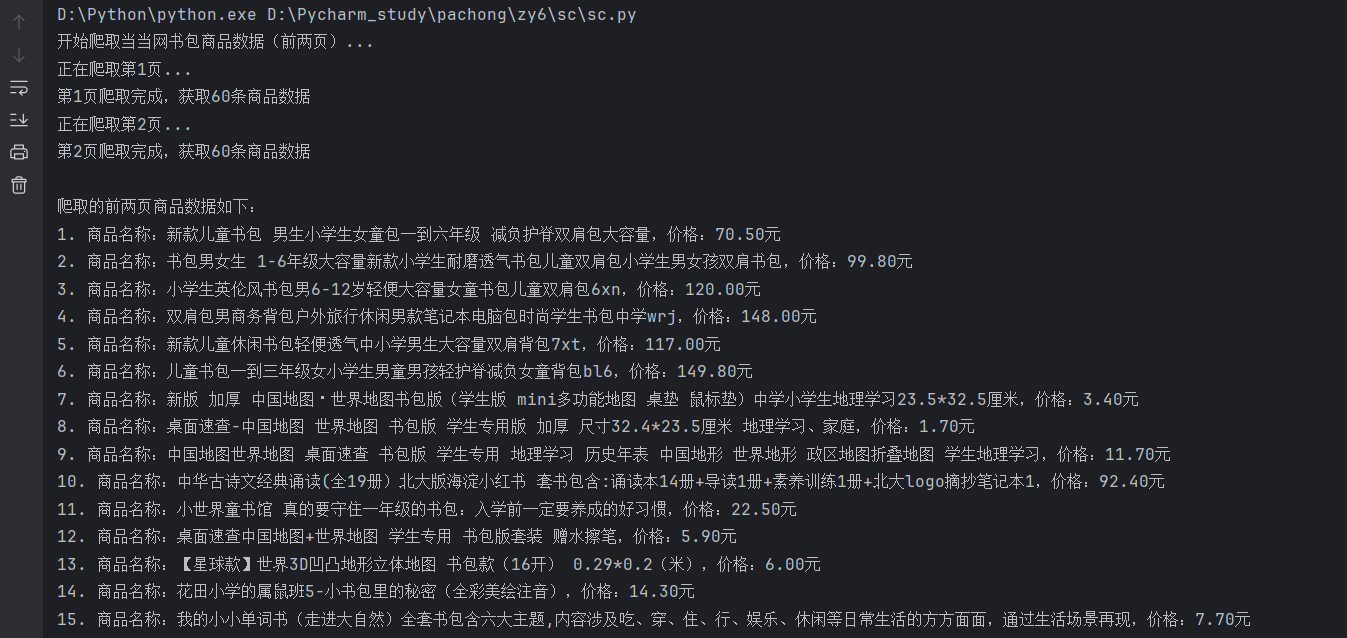

淘宝,京东等这些网页反爬能力强,所以选择了比较好爬的当当商场。首先我进入了当当商城的书包界面,进行了该页面源代码的了解,爬取的主要内容是商品的名称以及价格,着重看了html的结构,在代码中需要以正则表达式的形式提取出来。代码首先构建 URL,随机选 User-Agent 模拟浏览器,加 1-3 秒延迟防反爬;接着用正则匹配商品名(
class="pic"的 a 标签 title)和价格(class="price_n"的 span 标签),清洗空格 / 换行;然后确保名称与价格数量一致,结构化存为字典;最后循环爬取指定页数,汇总数据后打印并保存到 CSV。心得:
实验过程中遇到的主要挑战在于反爬限制与数据提取的问题。在发起请求时,未添加延迟会频繁触发网站反爬机制,导致请求失败;同时,当当网页面使用
gb2312编码,初期未设置编码时商品名称出现乱码,且价格字段需适配 “¥” 实体符号,正则表达式若未精准匹配,会提取不到有效价格,商品名与价格数量也可能因页面加载异常出现错位。通过添加 1-3 秒随机延迟、轮换 User-Agent,手动设置编码为gb2312,并反复调试正则模式与数据数量校验逻辑,最终实现了商品数据的稳定爬取与准确对应。
这次实验让我认识到,网页爬取并非仅关注数据提取逻辑,反爬策略适配与编码处理是基础前提,而数据校验能有效避免因页面异常导致的错误。只有深入了解目标网站的访问规则与页面结构特性,才能构建稳定、高效的爬取流程,减少后续调试成本。
作业三
核心代码与运行结果
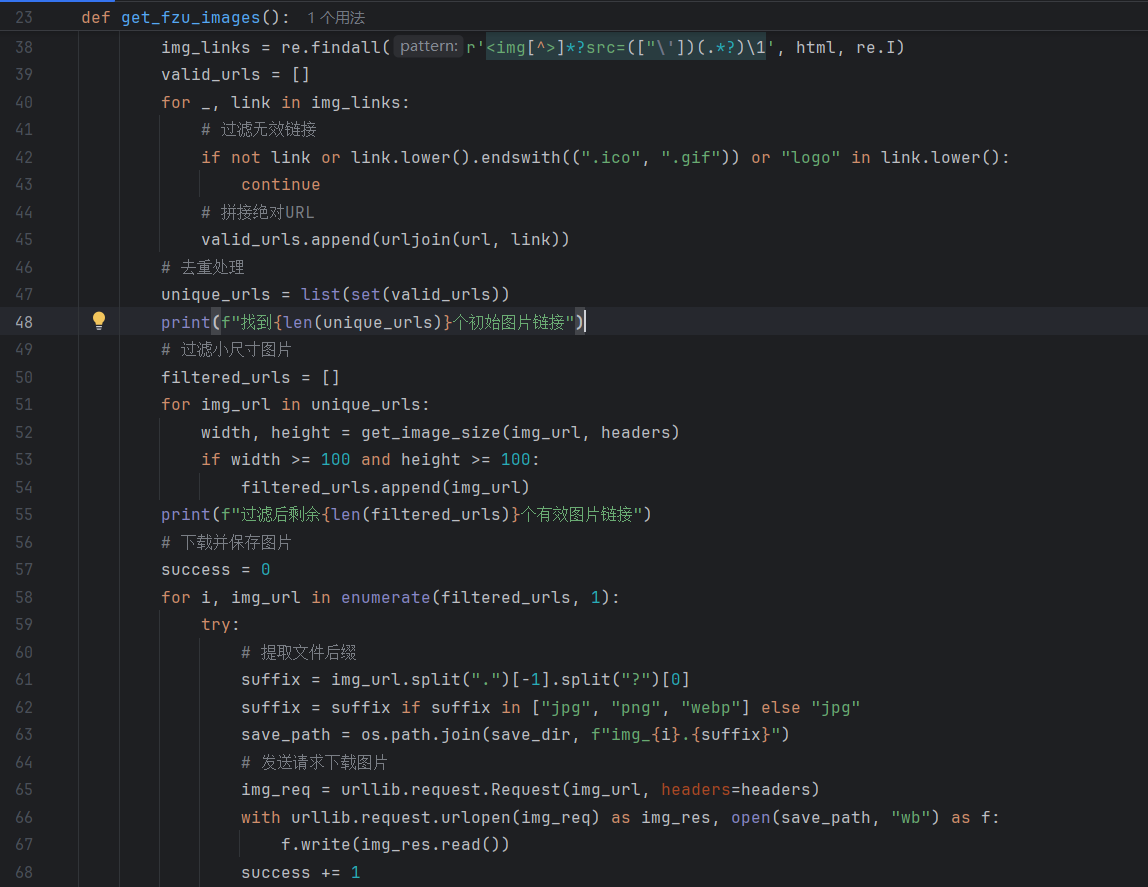
首先确定目标页面为福大新闻网 “影像福大” 栏目,核心需求是爬取页面中的有效图片并本地保存。先分析页面结构,明确图片链接存储在
img标签的src属性中,需通过正则表达式提取,同时需过滤图标、小图等无效资源。代码实现分五步:第一步准备工作,配置请求头(含 User-Agent、Referer)模拟浏览器,创建 “fzu_images” 本地目录用于保存图片;第二步获取网页内容,发送请求访问目标 URL,读取并以utf-8编码解码 HTML 源码;第三步提取与清洗链接,用正则匹配所有img标签的src属性,过滤 ico/gif 图标、含 “logo” 的无效链接,将相对 URL 拼接为绝对 URL 后去重;第四步筛选有效图片,调用get_image_size函数获取图片尺寸,保留宽高均≥100 的图片链接;第五步下载与保存,遍历有效链接,处理文件后缀(限定 jpg/png/webp 格式,默认 jpg),发送请求下载图片并写入本地,统计下载成功率。心得:
实验过程中遇到的主要挑战集中在无效资源过滤与图片下载稳定性上。链接提取阶段,初期未过滤 ico、gif 图标及 logo 链接,导致爬取大量无用小图,后续通过后缀匹配与关键词筛选才精准定位有效图片;图片筛选阶段,若未校验尺寸,会下载低分辨率图片,影响使用价值,
get_image_size函数通过读取图片数据获取尺寸,有效解决了这一问题。此外,网络波动或图片 URL 失效会导致下载失败,需通过异常捕获避免程序崩溃;同时,请求头中添加Referer字段是必要的,可降低被网站识别为爬虫的概率。这些问题让我意识到,图片爬取不仅要精准提取链接,更需通过多轮筛选保证资源质量,同时兼顾反爬策略与异常处理,才能实现稳定高效的爬取。