前言
本文介绍了可编程梯度信息(PGI)和通用高效层聚合网络(GELAN),以及SPPELAN模块在YOLO26中的结合应用。针对深度网络数据传输中的信息丢失问题,提出PGI概念以提供完整输入信息计算目标函数,获得可靠梯度更新网络权重;并基于梯度路径规划设计了GELAN架构。我们将SPPELAN模块集成进YOLO26,在MS COCO目标检测任务中,GELAN展现出更好的参数利用率,PGI使模型表现优于预训练的最新模型,改进后的YOLO26也取得了良好实验结果。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@
- 前言
- 介绍
- 摘要
- 文章链接
- 核心代码
- 实验
- 脚本
- 结果
介绍

摘要
当前深度学习研究主要聚焦于优化目标函数设计,旨在使模型预测结果最大程度逼近真实标注值(ground truth),同时需要构建合适的网络架构以确保预测过程中获取充分的信息支持。然而,现有研究方法普遍忽视了一个关键现象:输入数据在经历逐层特征提取与空间变换过程中会产生显著的信息丢失。本文系统性地探讨了深度网络中数据传递过程中出现的信息损失问题,特别是信息瓶颈与可逆函数相关的理论机制。为此,我们提出了可编程梯度信息(Programmable Gradient Information, PGI)的创新概念,该概念能够有效应对深度网络为实现多样化目标任务所需的各种变换需求。PGI机制可为特定目标任务提供完整的输入信息用于目标函数计算,从而获得可靠的梯度信息以优化网络权重更新过程。基于梯度路径规划策略,我们进一步设计了一种新型轻量级网络架构——通用高效层聚合网络(Generalized Efficient Layer Aggregation Network, GELAN),该架构的实验结果验证了PGI在轻量级模型中取得的卓越性能。在MS COCO数据集的目标检测任务中,我们对提出的GELAN与PGI进行了全面验证。实验结果表明,GELAN仅采用常规卷积算子即可实现比基于深度卷积(depth-wise convolution)的先进方法更优的参数利用效率。PGI技术展现出良好的通用性,适用于从轻量级到大规模的各种模型架构,能够有效获取完整信息,使得从零开始训练的模型性能超越基于大规模数据集预训练的先进模型,具体性能对比详见实验结果图示。相关源代码已公开于:https://github.com/WongKinYiu/yolov9。
文章链接
论文地址:论文地址
代码地址:代码地址
核心代码
class SPPELAN(nn.Module):# spp-elandef __init__(self, c1, c2, c3): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()self.c = c3self.cv1 = Conv(c1, c3, 1, 1)self.cv2 = SP(5)self.cv3 = SP(5)self.cv4 = SP(5)self.cv5 = Conv(4*c3, c2, 1, 1)def forward(self, x):y = [self.cv1(x)]y.extend(m(y[-1]) for m in [self.cv2, self.cv3, self.cv4])return self.cv5(torch.cat(y, 1))
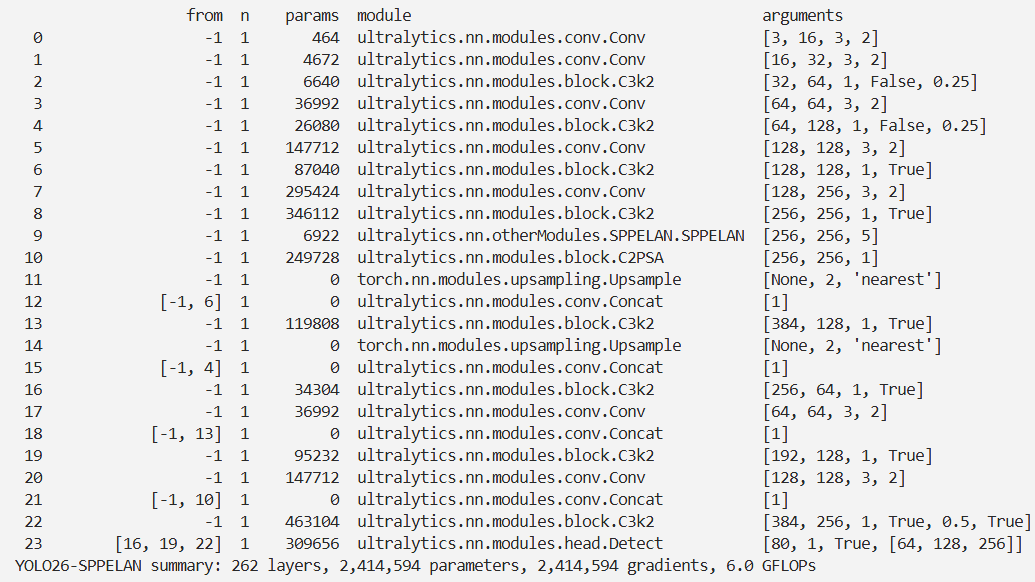
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('./ultralytics/cfg/models/26/yolo26-SPPELAN.yaml')
# 修改为自己的数据集地址model.train(data='./ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='MuSGD', # optimizer='SGD',amp=False,project='runs/train',name='yolo26-SPPELAN',)结果