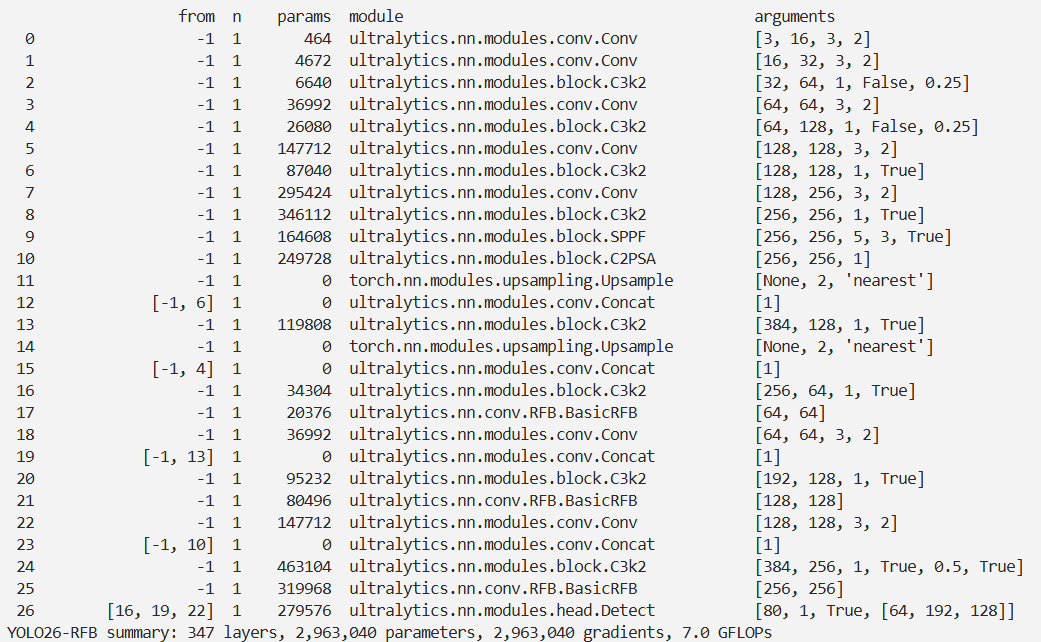
前言
本文介绍了感受野块(RFB)模块在YOLO26中的结合应用。RFB模块是一种多分支卷积块,由多分支卷积层和扩张池化或卷积层组成,通过模拟多尺度感受野和控制感受野偏心性,增强轻量级CNN模型学习到的深层特征,提高目标检测的准确性和速度。我们将RFB模块集成到YOLO26的检测头中,并进行相关注册和配置。实验结果显示,该方法能在保持实时速度的同时达到先进深度检测器的性能。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@
- 前言
- 介绍
- 摘要
- 文章链接
- 基本原理
- 核心代码
- 实验
- 脚本
- 结果
- 脚本
介绍

摘要
当前性能最优的目标检测器依赖于深度卷积神经网络(CNN)骨干,如ResNet - 101和Inception,尽管这些骨干网络凭借强大的特征表示能力展现出良好性能,但却存在计算成本高的问题。与之相反,部分轻量级模型的检测器虽能够实现实时处理,但其准确性往往受到诟病。在本文中,我们探索了一种替代方案,即通过运用手工设计的机制来增强轻量级特征,进而构建出一种兼具快速性与准确性的检测器。受人类视觉系统中感受野(RF)结构的启发,我们提出了一种新颖的感受野块(RFB)模块,该模块考虑了感受野大小与偏心率之间的关系,旨在增强特征的可辨别性和鲁棒性。我们进一步将RFB集成到单发多框检测器(SSD)之上,构建了RFB Net检测器。为评估其有效性,我们在两个主要基准上开展了实验,实验结果表明,RFB Net能够在维持实时处理速度的同时,达到先进深度检测器的性能水平。相关代码可在https://github.com/ruinmessi/RFBNet获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
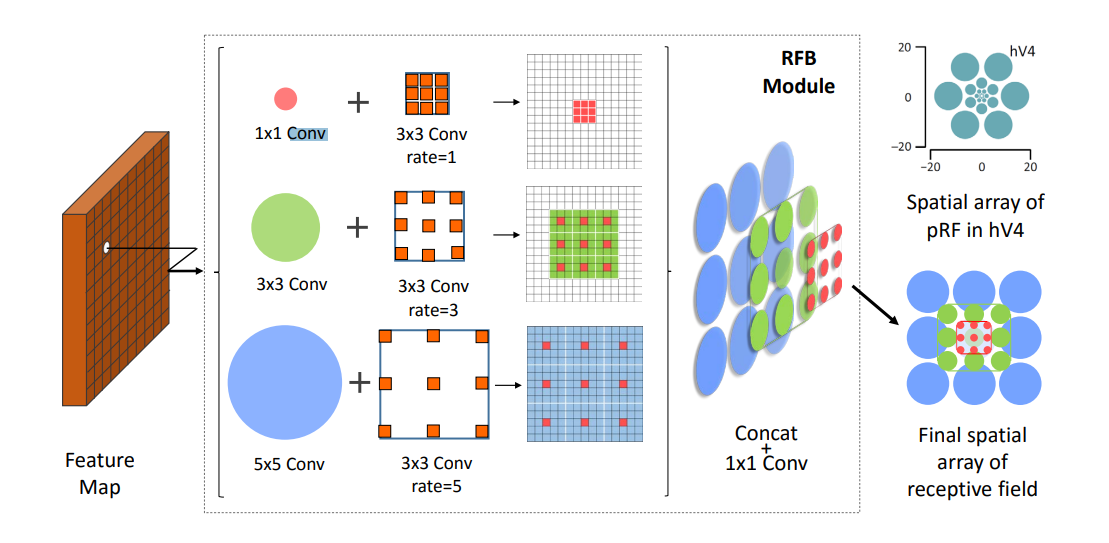
Receptive Field Block(RFB)模块是一种多分支卷积块,旨在增强轻量级CNN模型学习到的深层特征,以提高目标检测的准确性和速度。
-
结构组成:
-
RFB模块由两个主要组件组成:多分支卷积层和后续的扩张池化或卷积层。
-
多分支卷积层采用不同的核大小,类似于Inception结构,用于模拟多尺度的感受野。
-
扩张池化或卷积层用于控制感受野的偏心性,模拟人类视觉系统中感受野大小和偏心性之间的关系。
-
-
功能:
- RFB模块旨在提高特征的可区分性和鲁棒性,使得轻量级CNN模型也能够产生深层次的特征表示。
- 通过多分支卷积和扩张操作,模拟人类视觉系统中感受野的特性,从而更好地捕获目标检测任务中的多尺度信息。
-
模块设计:
- RFB模块采用多个分支,每个分支包含不同的卷积核大小和扩张率,以模拟不同尺度的感受野。
- 最终,所有分支的特征图被串联起来,形成一个空间池化或卷积数组,以生成最终的特征表示。
-
应用:
- RFB模块被嵌入到SSD等目标检测框架中,用于改善从轻量级骨干网络提取的特征,从而提高检测器的准确性和速度。
- 通过引入RFB模块,研究人员实现了在保持实时性能的同时,达到了先进深度检测器的性能水平。
核心代码
import torch
import torch.nn as nn
import numpy as np
import torch.nn.functional as F# 定义一个基本卷积模块类
class BasicConv(nn.Module):def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):super(BasicConv, self).__init__()self.out_channels = out_planes# 定义一个二维卷积层self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)# 如果启用批量归一化,则定义一个批量归一化层self.bn = nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True) if bn else None# 如果启用ReLU激活函数,则定义一个ReLU激活层self.relu = nn.ReLU(inplace=True) if relu else Nonedef forward(self, x):# 前向传播:依次通过卷积层、批量归一化层(如果有)、ReLU激活层(如果有)x = self.conv(x)if self.bn is not None:x = self.bn(x)if self.relu is not None:x = self.relu(x)return x# 定义一个基本的RFB(Receptive Field Block)模块类
class BasicRFB(nn.Module):def __init__(self, in_planes, out_planes, stride=1, scale=0.1, visual=1):super(BasicRFB, self).__init__()self.scale = scaleself.out_channels = out_planesinter_planes = in_planes // 8# 定义分支0,包含两个卷积层,第一个卷积层的卷积核大小为1,第二个卷积层的卷积核大小为3,步长为1,膨胀系数为visualself.branch0 = nn.Sequential(BasicConv(in_planes, 2*inter_planes, kernel_size=1, stride=stride),BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=visual, dilation=visual, relu=False))# 定义分支1,包含三个卷积层,第一个卷积层的卷积核大小为1,第二个卷积层的卷积核大小为3,步长为stride,第三个卷积层的卷积核大小为3,膨胀系数为visual+1self.branch1 = nn.Sequential(BasicConv(in_planes, inter_planes, kernel_size=1, stride=1),BasicConv(inter_planes, 2*inter_planes, kernel_size=(3, 3), stride=stride, padding=(1, 1)),BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=visual+1, dilation=visual+1, relu=False))# 定义分支2,包含四个卷积层,第一个卷积层的卷积核大小为1,第二个卷积层的卷积核大小为3,步长为1,第三个卷积层的卷积核大小为3,步长为stride,第四个卷积层的卷积核大小为3,膨胀系数为2*visual+1self.branch2 = nn.Sequential(BasicConv(in_planes, inter_planes, kernel_size=1, stride=1),BasicConv(inter_planes, (inter_planes//2)*3, kernel_size=3, stride=1, padding=1),BasicConv((inter_planes//2)*3, 2*inter_planes, kernel_size=3, stride=stride, padding=1),BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=2*visual+1, dilation=2*visual+1, relu=False))# 定义一个线性卷积层self.ConvLinear = BasicConv(6*inter_planes, out_planes, kernel_size=1, stride=1, relu=False)# 定义一个shortcut路径的卷积层self.shortcut = BasicConv(in_planes, out_planes, kernel_size=1, stride=stride, relu=False)# 定义一个ReLU激活层self.relu = nn.ReLU(inplace=False)def forward(self, x):# 前向传播:分别通过三个分支x0 = self.branch0(x)x1 = self.branch1(x)x2 = self.branch2(x)# 将三个分支的输出沿通道维度拼接out = torch.cat((x0, x1, x2), 1)# 通过线性卷积层out = self.ConvLinear(out)# 通过shortcut路径的卷积层short = self.shortcut(x)# 进行加权求和out = out * self.scale + short# 通过ReLU激活层out = self.relu(out)return out
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('./ultralytics/cfg/models/26/yolo26-RFB.yaml')
# 修改为自己的数据集地址model.train(data='./ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='MuSGD', # optimizer='SGD',amp=False,project='runs/train',name='yolo26-RFB',)结果