【综合实践】基于 DrissionPage 的小红书高性能数据采集——“途知”项目实战
1. 项目背景与意义
在当今的数字时代,人们的旅行灵感高度依赖于社交媒体平台。用户在浏览小红书、抖音等平台时,收集了大量碎片化的“种草”信息,但从“灵感”到“可行”的行程规划之间存在巨大的鸿沟。
为了解决这一痛点,我们团队开发了 “途知:智能旅行路线规划助手”。这是一个能够打通从“内容种草”到“智能规划”最后一公里的 Web 应用 。作为团队中负责 数据采集的成员,我的核心任务是构建一个小红书的爬虫,将非结构化的社交媒体数据(如笔记标题、正文、评论、图片)转化为结构化数据,为后续的 AI 意图识别和路线规划提供基础。
2. 技术选型与挑战
2.1 遇到的挑战
在分析小红书网页端时,我们发现了以下技术难点:
1.数据混编与 SSR:笔记的正文内容并非通过简单的 XHR 请求获取,而是通过SSR(服务端渲染)直接写在 HTML 源码的 JavaScript 变量(noteDetailMap)中 。
2.动态加载的评论:与正文不同,评论区是通过 Ajax 动态加载的,只有滚动到特定位置才会触发请求。
3.风控机制:频繁的请求极易触发滑块验证码或 461 错误。
2.2 解决方案:DrissionPage
针对上述问题,如果使用传统的 Selenium,解析 DOM 树不仅慢而且容易因页面结构变动而失效;如果纯用 Requests,又难以处理复杂的 JS 加密参数(X-s)。
因此,我采用了 DrissionPage框架。其核心思路是:一边控制浏览器模拟真实用户行为(处理登录、滚动),一边在后端直接拦截数据包。
我的主要策略如下:
列表页采集:利用 dri.listen.start 开启监听器,模拟滚轮下滑,直接截获 search/notes 接口返回的 JSON 数据包。
详情页采集:采用混合提取策略。正文内容直接从网页源码的 noteDetailMap 变量中提取,而评论数据则通过监听动态加载的接口获取 。
反爬策略:引入自适应随机延迟(Adaptive Delay)模拟人类操作节奏。
3. 核心代码实现
本爬虫主要包含三大核心模块:登录与初始化、笔记搜索与监听、详情解析与存储。
3.1 初始化与登录检测
DrissionPage 的 WebPage对象是单例模式,可以直接接管用户已经打开的浏览器。我们要求用户先登录,确保持久化的 Cookie 有效。
点击查看代码
def _login_check(self):logger.warning("正在初始化浏览器...")logger.warning("请检查浏览器是否已登录小红书。")# ... (代码省略)logger.success("登录确认完成,爬虫服务就绪!")
3.2 列表页:监听数据流 (核心亮点)
这是最关键的一步。不同于传统的 find_element,我们直接“监听”浏览器收到的数据包。当页面滚动时,数据包一到达,我们就直接解析 JSON,效率极高 。
点击查看代码
def _search_notes(self, keyword, limit):# 核心:开启监听 search/notes 接口self.dri.listen.start('search/notes')self.dri.get(url)# ... 循环滚动页面 ...# 等待并获取数据包resp = self.dri.listen.wait(timeout=10)# 直接解析 Response Body,无需解析 HTML DOMitems = resp.response.body.get('data', {}).get('items', [])# 解析数据逻辑...
3.3 详情页:SSR 源码提取与动态监听结合
为了获取最完整的笔记内容,我同时使用了两种方法:
正文:使用字符串切片从 HTML 源码中提取 noteDetailMap,这是 SSR 渲染留下后,速度极快 。
评论:监听 sns/web/v2/comment/page 接口 。
点击查看代码
def _fill_details(self, note):# 1. 静态提取正文 (SSR 解析)html = self.dri.htmlsnippet = self._find_str(html, 'noteDetailMap":', ',"serverRequestInfo"')# ... JSON 解析 snippet ...# 2. 动态监听评论self.dri.scroll.to_bottom() # 触发加载res = self.dri.listen.wait(timeout=5)# ... 解析评论 ...
4. 运行效果与数据展示
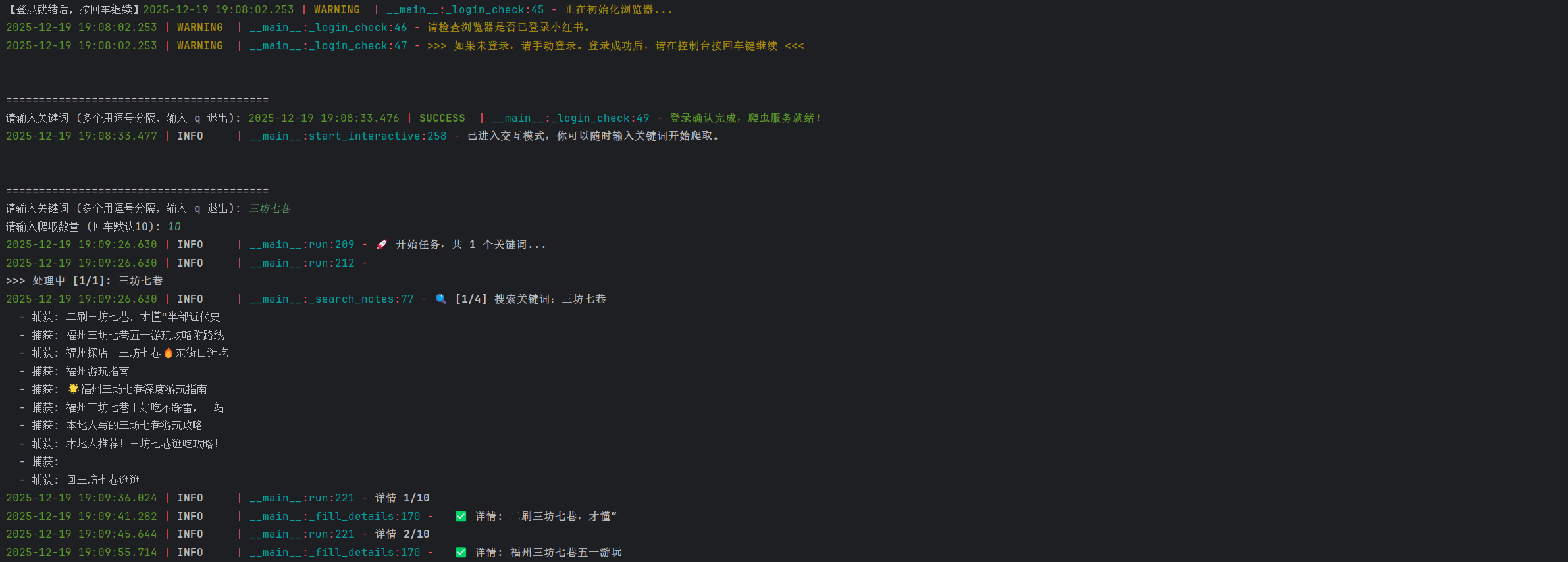
4.1 交互式采集
为了方便测试,我封装了一个交互式命令行界面(CLI)。运行程序后,输入关键词(如“福州三坊七巷”)和数量即可自动开始采集。
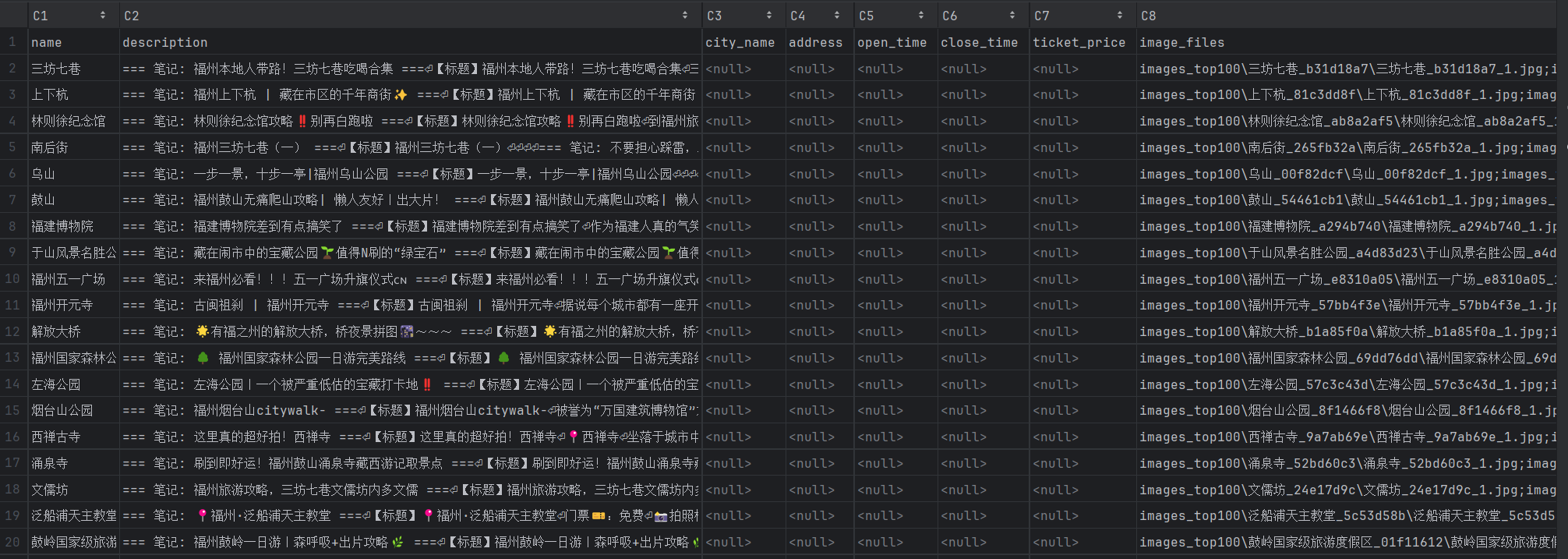
4.2 数据成果
采集的数据会自动保存为 CSV 格式,包含标题、正文(含描述和热评)、图片链接等字段。同时,脚本会自动下载相关的图片到本地 images 文件夹,为后续我们“途知”项目中的 OCR 识别 和 LLM 意图理解 提供素材。
5. 完整代码
点击查看代码
import json
import os
import random
import time
import urllib.parse
import hashlib
import requests
import pandas as pd
from DrissionPage import WebPage
from loguru import loggerclass XhsSpider:"""小红书采集服务类"""def __init__(self, output_csv="raw_xiaohongshu.csv", img_dir="images"):"""初始化爬虫服务"""self.output_csv = output_csvself.img_dir = img_dirself.request_count = 0# 初始化浏览器 (单例模式)self.dri = WebPage()self.dri.get('https://www.xiaohongshu.com/explore')# 初始化文件结构self._init_file()# 登录检查self._login_check()def _init_file(self):if not os.path.exists(self.output_csv):df = pd.DataFrame(columns=["name", "description", "city_name", "address", "open_time","close_time", "ticket_price", "image_files", "category"])df.to_csv(self.output_csv, index=False, encoding="utf-8-sig")def _login_check(self):logger.warning("正在初始化浏览器...")logger.warning("请检查浏览器是否已登录小红书。")logger.warning(">>> 如果未登录,请手动登录。登录成功后,请在控制台按回车键继续 <<<")input("【登录就绪后,按回车继续】")logger.success("登录确认完成,爬虫服务就绪!")# ================= 核心工具方法 =================def _random_delay(self, min_d=2, max_d=5):time.sleep(random.uniform(min_d, max_d))def _adaptive_delay(self):self.request_count += 1base = 5 if self.request_count > 50 else 2self._random_delay(base, base + 3)@staticmethoddef _find_str(text, left, right):l = text.find(left)if l == -1: return Noner = text.find(right, l + len(left))if r == -1: return Nonereturn text[l + len(left):r]@staticmethoddef _safe_filename(s):s = str(s).strip()short = "".join(ch for ch in s if ch.isalnum())[:30]h = hashlib.sha1(s.encode("utf-8")).hexdigest()[:8]return f"{short}_{h}"# ================= 业务逻辑 =================def _search_notes(self, keyword, limit):logger.info(f" [1/4] 搜索关键词:{keyword}")url = f"https://www.xiaohongshu.com/search_result?keyword={urllib.parse.quote(keyword)}&source=web_search_result_notes"collected = []existing_ids = set()try:self.dri.listen.start('search/notes')self.dri.get(url)self._random_delay(3, 5)page = 0while len(collected) < limit:page += 1if page == 1:resp = self.dri.listen.wait(timeout=10)else:self.dri.scroll.to_bottom()resp = self.dri.listen.wait(timeout=10)if not resp: breakitems = resp.response.body.get('data', {}).get('items', [])if not items: breakfor note in items:if len(collected) >= limit: breakif 'note' not in note.get('model_type', ''): continuenid = note.get('id')if nid in existing_ids: continueimg_list = []for img in note.get('note_card', {}).get('image_list', []):if img.get('info_list'):img_list.append(img['info_list'][0]['url'])elif img.get('url'):img_list.append(img['url'])data = {'id': nid,'title': note['note_card'].get('display_title', ''),'url': f"https://www.xiaohongshu.com/explore/{nid}?xsec_token={note.get('xsec_token')}&xsec_source=pc_feed",'imgs': img_list,'content': ''}collected.append(data)existing_ids.add(nid)print(f" - 捕获: {data['title'][:15]}")if not resp.response.body.get('data', {}).get('has_more'): breakself._random_delay(2, 4)self.dri.listen.stop()return collectedexcept Exception as e:logger.error(f"搜索异常: {e}")self.dri.listen.stop()return []def _fill_details(self, note):try:self.dri.listen.start('sns/web/v2/comment/page')self.dri.get(note['url'])time.sleep(random.uniform(2, 4))html = self.dri.htmlsnippet = self._find_str(html, 'noteDetailMap":', ',"serverRequestInfo"')desc = ""if snippet:try:js = json.loads(snippet)n = js.get(note['id'], {}) or list(js.values())[0]desc = n.get('note', {}).get('desc', '')if not note['imgs']:note['imgs'] = [i['infoList'][0]['url'] for i in n.get('note', {}).get('imageList', []) ifi.get('infoList')]except:passself.dri.scroll.to_bottom()time.sleep(1)self.dri.scroll.up(300)comments = ""res = self.dri.listen.wait(timeout=5)if res and res.response.body:cl = res.response.body.get('data', {}).get('comments', [])if cl:comments = "\n[热评]:\n" + "\n".join([f"- {c['user_info']['nickname']}: {c['content']}" for c in cl[:5]])note['content'] = f"【标题】{note['title']}\n{desc}\n{comments}"logger.info(f" 详情: {note['title'][:10]}")except Exception as e:logger.error(f"详情异常: {e}")finally:self.dri.listen.stop()return notedef _download_imgs(self, keyword, urls):if not urls: return ""unique = list(set(urls))selected = random.sample(unique, min(2, len(unique)))safe_kw = self._safe_filename(keyword)save_path = os.path.join(self.img_dir, safe_kw)os.makedirs(save_path, exist_ok=True)paths = []for idx, url in enumerate(selected):try:ext = ".png" if ".png" in url else ".jpg"fname = os.path.join(save_path, f"{safe_kw}_{idx + 1}{ext}")resp = requests.get(url, timeout=15, headers={"User-Agent": "Mozilla/5.0"})if resp.status_code == 200:with open(fname, "wb") as f:f.write(resp.content)paths.append(fname)except:passreturn ";".join(paths)# ================= 核心:执行抓取 =================def run(self, keywords, limit=10):"""执行抓取任务"""if isinstance(keywords, str):kw_list = [k.strip() for k in keywords.replace(';', ',').replace(',', ',').split(',') if k.strip()]else:kw_list = keywordslogger.info(f" 开始任务,共 {len(kw_list)} 个关键词...")for i, kw in enumerate(kw_list):logger.info(f"\n>>> 处理中 [{i + 1}/{len(kw_list)}]: {kw}")notes = self._search_notes(kw, limit)if not notes:logger.warning(f"未找到 {kw} 笔记")continuefull_notes = []for n_idx, note in enumerate(notes):logger.info(f"详情 {n_idx + 1}/{len(notes)}")full_notes.append(self._fill_details(note))self._adaptive_delay()all_imgs = []merged_desc = ""for n in full_notes:all_imgs.extend(n['imgs'])merged_desc += f"=== 笔记: {n['title']} ===\n{n['content']}\n\n"logger.info(" 下载图片...")img_paths = self._download_imgs(kw, all_imgs)row = {"name": kw,"description": merged_desc,"city_name": "", "address": "", "open_time": "","close_time": "", "ticket_price": "","image_files": img_paths, "category": ""}try:pd.DataFrame([row]).to_csv(self.output_csv, mode='a', header=False, index=False, encoding="utf-8-sig")logger.success(f" [{kw}] 保存成功!")except Exception as e:logger.error(f"保存失败: {e}")if i < len(kw_list) - 1:logger.info(" 休息 5 秒...")time.sleep(5)logger.success(" 任务完成!")# ================= 新增:交互模式封装 =================def start_interactive(self):"""启动交互式命令行模式,循环询问用户输入"""logger.info("已进入交互模式,你可以随时输入关键词开始爬取。")while True:print("\n" + "=" * 40)user_input = input("请输入关键词 (多个用逗号分隔,输入 q 退出): ").strip()if user_input.lower() in ['q', 'exit', 'quit']:logger.info(" 退出交互模式")breakif not user_input:continuelimit_str = input("请输入爬取数量 (回车默认10): ").strip()# 容错处理try:limit = int(limit_str) if limit_str else 10except ValueError:logger.warning("输入无效,使用默认值 10")limit = 10# 调用自身的 run 方法self.run(user_input, limit)# ================= 使用示例 =================
if __name__ == "__main__":# 1. 实例化 (只需这一次登录)spider = XhsSpider(output_csv="my_data.csv")spider.start_interactive()