Day3 Scrum冲刺博客
1. 团队会议
todo补充会议照片
1)昨天已完成的工作
- 前端
- 实现个人设置弹窗以及问答模式静态页面,实现问答模式缓存
- "关于我们"细节修正
- 后端
- 完成爬虫数据的数据清洗
- 增加爬虫程序适配的信息网站
- 测试
- 检查各代码文件格式清晰性
2)今天计划完成的工作
- 前端
- 实现了数据过滤与分页核心逻辑与分页控制功能
- 完成了表单中的通知公告初稿
- 后端
- 实现了大模型api的意图整理和栏目分类
- 实现了关键词划分算法
- 实现了数据清洗正则化的加强
- 测试
- 检查新加入各代码文件格式清晰性
3)工作中遇到的困难
- 前端
- 在实现分页与过滤同时生效时,需要保证筛选结果数量与分页组件状态保持同步,部分逻辑需要梳理。
- 后端
- 大模型意图分类在部分表达方式下不稳定,需要增加额外后处理。
- 测试
- 代码结构更新频繁,文件格式难以一次性统一检查。
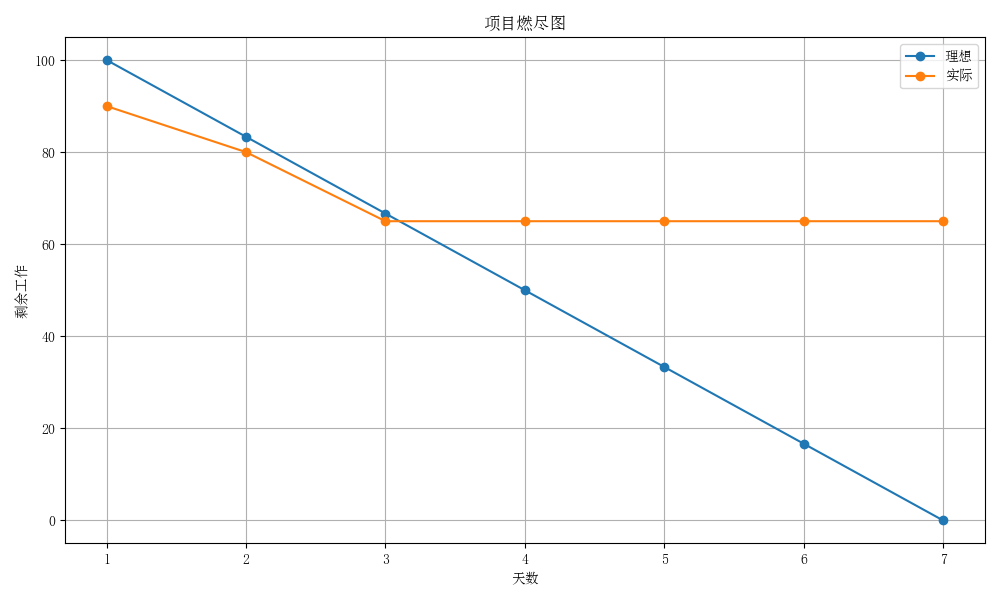
2. 项目燃尽图
今日为第三天,已快于理想进度,但需加快进度。
3.代码/文档签入记录
-
今日签入记录
![]()
-
签入记录链接:https://github.com/sevanthea7/GdutInfoHub/commits/main/
-
相关联issue见commit记录中
#后链接内容 -
接口文档与返回格式文档见
docs/api_doc.md与docs/return_doc.md

4. 运行截图
-
前端
-
完成了数据过滤与分页核心逻辑与分页控制功能
-
相关功能代码
// 1.数据过滤与分页核心逻辑(<script setup> 部分): // 筛选当前分类的通知数据 const filteredNotices = computed(() => {const currentType = tabList.value[activeTab.value].type;return allNoticeData.value.filter((notice) => notice.type === currentType); });// 计算总页数 const totalPages = computed(() =>Math.ceil(totalItems.value / PAGE_SIZE.value) );// 获取当前页数据 const currentPageData = computed(() => {const startIndex = (currentPage.value - 1) * PAGE_SIZE.value;const endIndex = startIndex + PAGE_SIZE.value;return filteredNotices.value.slice(startIndex, endIndex); });// 生成可见页码(处理省略号逻辑) const visiblePages = computed(() => {// 页码生成逻辑... });// 2.分页控制功能: // 切换选项卡时重置页码 const switchTab = (index) => {activeTab.value = index;currentPage.value = 1; };// 上一页/下一页控制 const prevPage = () => { /* 实现 */ }; const nextPage = () => { /* 实现 */ };// 跳转指定页码 const goToPage = (page) => { /* 实现 */ };// 监听总页数变化,自动调整当前页 watch(totalPages, () => { /* 实现 */ });
![]()
-
-
-
后端
-
实现了大模型api的调用,可以对测试数据进行意图解析
-
src\crawler\LLM_api\intention_agent.py
import json from src.crawler.LLM_api.create_api_client import clientPROMPT = '帮我解析这个用户的意图,把他的问题拆分为点,返回结果为JSON格式,形如{"1":"q1", "2": "q2",...}: ' def get_user_intension(user_text):input_text = PROMPT + user_textresp = client.chat.completions.create(model="doubao-1-5-lite-32k-250115",messages=[{"content":f"{input_text}.","role":"system"}],stream=False,)json_return = resp.choices[0].message.contentprint(json_return)json_obj = json.loads(json_return)obj_lst = list(json_obj.values())print(obj_lst)test_text = "我想知道图书馆明天会举办的活动,以及最近宿舍的热水供应时间" get_user_intension(test_text)
![]()
-
-
加强数据清洗正则化,增加关键词提取算法
-
src\crawler\data_clean\reprocess.py
# 用于保存所有整理后的内容 all_contents = []# 遍历文件夹里的所有 JSON 文件 for filename in os.listdir(folder_path):if filename.endswith('_raw.json'):file_path = os.path.join(folder_path, filename)with open(file_path, 'r', encoding='utf-8') as f:try:data = json.load(f) # 读取文件except json.JSONDecodeError:print(f"文件 {filename} 不是有效 JSON,跳过")continue# 处理 json 文件中的每个字典for item in data:# 正则化处理:# 1. 去掉开头结尾空白# 2. 将连续换行或空白替换为一个空格# 3. 去掉多余空格if 'content' in item:# TEXT = item['content']TEXT = advanced_clean(item['content'])TEXT = re.sub(r'[\s\u2028\u2029]+', ' ', TEXT).strip()# 从处理后的文本中应用 TF-IDF 算法提取关键词keywords = jieba.analyse.extract_tags(sentence=TEXT,topK=6, # 提取的关键词数量allowPOS=['n', 'nz', 'ns'], # 允许的关键词的词性withWeight=False, # 是否附带词语权重withFlag=False, # 是否附带词语词性)# 为data添加关键词字段item['keywords'] = keywordsif 'title' in data:data['title'] = advanced_clean(data['title'])# 新文件名,把 "_raw" 换成 "_cleaned",如果没有 "_raw" 就直接加 "_cleaned"new_filename = filename.replace('_raw', '_reprocessed')new_file_path = os.path.join(folder_path, new_filename)# 写入新文件with open(new_file_path, 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=2) # 保存为格式化的 JSONprint(f"已生成 {new_filename}")
![]()
-
-


5. 每人每日总结
-
前端
- 吴佳童:今天重点配合完成了前端的数据过滤与分页功能开发,包括过滤条件的处理逻辑、分页参数响应及页面渲染优化。在调试过程中解决了页面状态同步的问题,使数据展示更加稳定。同时对现有组件代码进行了结构调整,提高了整体模块的可维护性。
- 张洁:今天主要完成了数据过滤与分页的核心逻辑实现,搭建了可复用的分页控制组件,使前端在展示大规模通知数据时能够保持流畅的交互体验。同时完成了表单模块中“通知公告”页面的初稿设计与实现,初步确定了字段布局、信息层级与交互样式,为后续的联调与视觉优化奠定了基础。
- 李恺凝:今天主要协助前端对接页面交互细节,对分页模块、通知公告初稿页面的排版与交互方式进行了统一规范。根据前端实现出的组件效果,对字体层级、间距、信息密度以及颜色对比度进行了微调建议,确保界面在实际数据量下仍保持清晰可读。同时更新了对应的设计稿与交互说明文档,使前端在后续开发中有更明确的视觉与交互参考。
-
后端
- 王韵清:今天主要完成了大模型 API 返回内容的意图整理与栏目分类模块,实现了将大模型输出归纳为结构化类别的功能。通过构建意图映射规则,使模型回答能够与前端所需的页面栏目标识对齐,为后续问答流程的自动路由与知识库填充提供关键支撑。
- 徐伊彤:今天对数据清洗过程进行了进一步加强,补充了更严格的正则规则,并针对异常格式文本添加了额外的处理分支。通过多组样例验证,清洗后的数据在字段一致性、冗余去除与结构稳定性方面有明显提升,为后续知识库构建与模型调用提供了更高质量的数据源。
- 曾钰仪:今天实现了关键词划分算法设计与初步落地,主要包括文本关键词提取、词语分组逻辑与去噪处理。通过对多类实际数据进行测试,初步验证了算法在常见校园通知文本中的有效性,为知识库分类索引与问答召回提供了基础能力。
-
测试
- 戴军霞:今天重点对新加入的代码文件进行了格式与结构的规范性检查,包括命名一致性、注释清晰度、文件分层合理性等。对发现的问题进行了记录并提出了修改建议,确保代码质量符合团队规范,为下一阶段的系统级功能测试做好准备。