摘要:Conditional Edge 是 LangGraph 里实现动态路由的核心机制,它不是简单的 if-else 分支,而是「由 State 驱动、由 condition 函数返回节点名的运行时路由决策」。

某天下午,你正在用 LangGraph 搭一个内容审核工作流:调研节点负责抓资料,撰写节点负责出草稿,校对节点负责挑毛病。线性流程跑通了,你开始加需求——校对通过就结束,没通过就回到撰写节点重新改。
你下意识写了个 if is_approved: return END else: return "write",然后发现这不是普通 add_edge 能描述的东西。
这才是 Conditional Edge 真正登场的时刻。不是教科书告诉你该学,而是你真的卡在业务逻辑里需要一个「由状态决定下一步往哪走」的机制。
为什么 LangGraph 需要 Conditional Edge
LangChain 的基础链(Chain)是线性的:输入进来,按顺序流过每一个处理步骤,输出走人。
Agent 的循环(ReAct Loop)也是相对单一的:思考→行动→观察→再思考,周而复始直到触发终止条件。
这两套模式对付「一步一步往下走」的场景够用,但真实工作流往往不是一条直线。
举一个你很可能遇到过的例子:「调研→撰写→校对」,校对通过则输出最终文章,没通过则回到撰写节点修改草稿,再次进入校对环节。
这个流程里有两条完全不同的后续路径,取决于校对节点的执行结果。普通 add_edge 只接受一个固定的目标节点描述,你没法写「如果 A 则去 B,否则去 C」。
更复杂一点的场景:内容审核 Agent 里,用户提交的内容可能同时触发「色情检测」「暴力检测」「广告检测」三个子检查,每个子检查返回通过或拒绝,三个结果之间是「任一拒绝则拒绝,全部通过才通过」的组合逻辑。
这种多路分支+组合判断,线性链和单一 Agent 循环都兜不住。
Anthropic 在 2026 年 4 月公开的多 Agent harness 设计里,把「条件跳转」列为长时运行 Agent 框架的核心挑战之一。
他们提出的 planner/generator/evaluator 三角色架构中,evaluator 对输出质量的判断直接决定下一步是继续生成、调整方向还是直接输出——这个决策点本质上就是一个 Conditional Edge1。
LangGraph 解决这个问题的方式是引入 Conditional Edge:边的目标节点不再由编译期决定,而是在运行时由一个函数根据当前 State 的值来返回。
Conditional Edge 的核心机制:函数返回节点名,路由就完成了
Conditional Edge 的核心 API 是 add_conditional_edges,接受三个参数:
graph.add_conditional_edges(start_node="review", # 条件判断的触发节点condition=review_condition, # 条件判断函数mapping={ # 可选:条件结果到目标节点的映射True: END,False: "write"}
)
这里的关键是 condition 函数。它的签名必须是 (state) -> str,即接收当前 State,返回一个节点名字符串或 END 表示结束。
def review_condition(state: WritingState) -> str:"""条件判断函数:根据 is_approved 决定下一个节点"""if state["is_approved"]:return END # 校对通过,流程结束else:return "write" # 校对不通过,返回撰写节点修改草稿
当这个函数返回 "write" 时,LangGraph 运行时就知道下一步该激活 write 节点;返回 END 时,工作流正常终止。
整个路由决策在运行时完成,编译期只知道「从 review 节点出发有一个条件边」,不知道具体会跳到哪。
这里有一个根本性差异需要记住:**普通 Edge 在 graph.compile() 时就确定了目标节点,是编译期决策;
Conditional Edge 的目标节点在 app.invoke() 运行时才由 State 决定,是运行时决策。
** 这个区别在面试里会被追问,也是判断候选人是否真正理解 Conditional Edge 本质的关键。
condition 函数与 mapping 语法糖
mapping 参数是一个可选的语法糖,简化了常见的「条件结果直接映射到节点」场景。上面的 review_condition 函数可以简化为一行:
graph.add_conditional_edges(start_node="review",condition=lambda state: state["is_approved"],mapping={True: END, False: "write"}
)
当 condition 函数返回的值能直接作为 mapping 的 key 时,这行写法比手写 if-else 更简洁。
但要注意:mapping 只能处理「返回值是字符串或 END」的简单映射,如果你需要根据多个 State 字段做组合判断、或者需要更复杂的路由逻辑,还是得写完整的 condition 函数。

review_condition 写成 lambda 之后,三个月后自己都读不懂了
模板答案与展开版本
30 秒开口版
Conditional Edge 是 LangGraph 里实现动态路由的核心机制。普通 Edge 在编译期就确定目标节点,而 Conditional Edge 的目标节点由一个 condition 函数在运行时根据当前 State 的值返回。condition 函数签名是
(state) -> str,返回节点名字符串或 END,再配合可选的 mapping 参数做结果映射。这个机制让我可以在工作流里实现「校对通过则结束,不通过则返回重写」这类分支决策,而不需要把分支逻辑写死在节点内部。
这段答案在 30 秒内交代了三个核心点:什么是 Conditional Edge、它和普通 Edge 的本质区别、以及它解决什么问题。面试官听到这里通常会追问细节。
3 分钟展开版
LangGraph 基于状态机和 DAG 思想来编排复杂工作流。在 DAG 里,节点是执行步骤,边是步骤之间的流转关系。
普通
add_edge定义的是固定流转:比如graph.add_edge("research", "write"),这条边在编译时就确定了「从 research 节点出来,下一步一定是 write 节点」,没有例外。
但真实业务场景里,路由往往不是固定的。比如我做内容审核工作流,用户提交的内容可能走「色情检测」「暴力检测」「广告检测」三个子节点,每个子节点返回通过或拒绝,我需要根据这些结果组合来决定下一步是输出、通过、还是标记为人工复审。这种「由运行时状态决定下一步」的路由需求,就是 Conditional Edge 要解决的。
add_conditional_edges接受三个参数:start_node 指定从哪个节点出发,condition 是一个(state) -> str函数,mapping 是可选的结果映射表。当 condition 函数执行后,返回值会查 mapping 得到目标节点,或者直接就是节点名字符串。如果返回 END,就正常结束工作流。
这里有一个面试常考的细节:condition 函数必须返回字符串(节点名或 END),不能返回布尔值直接当作边的开关。很多人误以为
condition=lambda state: state["is_approved"]就能直接控制边的通断,但实际上这个返回值必须经过 mapping 才能映射成目标节点,除非 LangGraph 内部做了特殊处理。
展开版在核心机制上加了 DAG 背景和真实业务场景,让答案不只是背定义,而是有工程语境的支撑。
追问补答话术
面试官如果追问「condition 函数里能不能调用工具」,可以这样接:
理论上可以,但工程上不推荐。condition 函数的职责应该保持单一:读取 State、做判断、返回节点名。如果在里面引入工具调用(比如发起一个 API 请求),会增加这个函数的执行时间,而且一旦工具调用失败,整个路由决策都会受影响。我更倾向于把复杂的判断逻辑前置到节点里执行,结果写入 State,再由 condition 函数只做纯函数式的路由选择。
这个回答展现了工程判断力:不是回答「能不能」,而是回答「应该怎么做以及为什么」。
为什么问这个:面试官在筛什么
Conditional Edge 这个知识点在面试里的筛选逻辑分三个层次。
第一层是 API 记忆:候选人能不能准确说出 add_conditional_edges 的参数、condition 函数的签名、以及 mapping 的作用。
这一层筛掉的是连文档都没看完就来面试的人。
第二层是 State 驱动理解:候选人能不能说清楚普通 Edge 和 Conditional Edge 的根本差异——编译期定目标 vs 运行时由 State 决定。
能够清晰表述这个差异的人,说明他不只是背了 API,还理解了 LangGraph 的状态机设计思路。
第三层是 业务场景设计能力:候选人能不能把 Conditional Edge 和真实业务场景结合起来。
比如问「如果要实现一个多级审批工作流,每个审批节点通过后可能进入下一级审批、返回修改、或者直接拒绝,Conditional Edge 怎么设计」,能给出 State 建模和分支逻辑设计的人,通常具备独立设计复杂工作流的能力。
这道题通常落在二面或三面的系统设计轮,结合 LangGraph 工作流设计题一起考察。它不是一道孤立的 API 题,而是通过这个 API 考察候选人对「状态驱动的运行时决策」这个核心范式的理解深度。
常见追问与项目落地话术
追问 1:condition 函数里能不能调用工具?
参考上一节的补答话术。核心原则是保持 condition 函数职责单一,把复杂逻辑留给节点处理。
追问 2:多个条件分支怎么组织?
可以用链式 condition 函数或者 State 字段组合判断。比如内容审核场景,三个子检查节点的结果可以分别写入 State:
class ContentModerationState(TypedDict):porn_check: str # "pass" | "fail"violence_check: str # "pass" | "fail"ad_check: str # "pass" | "fail"final_decision: str # "auto_pass" | "manual_review" | "reject"def moderation_condition(state: ContentModerationState) -> str:# 任一检测失败则直接拒绝if (state["porn_check"] == "fail" orstate["violence_check"] == "fail"):return END # 严重违规,直接拒绝# 广告检测失败则人工复审if state["ad_check"] == "fail":return "manual_review_node"# 全部通过return "publish_node"
这个例子展示了如何用多个 if 判断组合成复杂的分支逻辑。
追问 3:如果没有节点满足条件会怎样?
这个问题考察候选人对运行时行为的理解。
如果 condition 函数返回了一个 mapping 里不存在的 key,或者返回了一个图中根本不存在的节点名,LangGraph 会在运行时抛出异常,工作流中断。
所以 condition 函数的返回值必须是图中真实存在的节点名或者 END,工程上建议在 condition 函数开头加断言保护:
def safe_review_condition(state: WritingState) -> str:result = "write" if not state["is_approved"] else ENDassert result in ["write", END], f"Invalid node: {result}"return result
上线后发现 condition 返回了不存在的节点名,整条链路崩了
项目话术示例:内容审核 Agent 三路分支设计
如果你在项目里做过类似的设计,可以这样描述:
我负责的内容审核模块,用户提交的文字/图片先经过三个子检测节点(色情、暴力、广告),每个子节点的结果写入 State。moderation_condition 函数读取三个字段,任一严重违规直接拒绝,广告违规进入人工复审队列,全部通过则自动发布。这套三路分支设计将人工复审量从日均 2000 条降到约 1200 条,节省约 40% 的人工审核成本,误拒率保持在 0.3% 以下。
这里用具体数字(40% 成本节省、0.3% 误拒率)支撑了项目价值,让面试官感受到你的贡献是能量化的。
高风险误答与易错点
误答 1:condition 函数返回非字符串类型
有些候选人会写 condition=lambda state: state["is_approved"],然后误以为返回布尔值就能控制边的通断。
实际上 is_approved=True 不会自动变成 END,必须经过 mapping 才能映射。正确做法是加 mapping 参数:
graph.add_conditional_edges(start_node="review",condition=lambda state: state["is_approved"],mapping={True: END, False: "write"}
)
或者让 condition 函数直接返回节点名字符串。
误答 2:忘记在循环路径上设置终止条件
「校对→撰写→校对」是一个典型的循环结构,面试官会问:如果 condition 函数逻辑有 bug,永远不返回 END 会怎样?
答案是 LangGraph 默认不设最大循环次数限制(max_steps 默认为 None),工作流会无限循环下去直到手动 kill 或者触发超时。
这个坑在生产环境里可能导致 Token 费用失控。正确的做法是:
-
在 condition 函数里确保终止条件一定能被触发
-
在
graph.compile(max_steps=10)里设置最大循环次数作为保护 -
捕获循环超限异常并做降级处理
try:final_state = app.invoke(initial_state)
except Exception as e:logger.error(f"Workflow exceeded max iterations: {e}")final_state = fallback_handler(initial_state)
误答 3:混淆 condition 函数职责与节点内部逻辑
面试里常见的一种误答是「我在 condition 函数里调用了 LLM 来判断下一步」。这实际上是把「判断逻辑」写错了位置。
condition 函数应该是纯函数式的:读取 State → 返回节点名。如果需要 LLM 做复杂判断,应该在节点里完成,condition 函数只负责路由选择。
误答 4:误以为 mapping 只支持布尔值
mapping 的 key 可以是任意可哈希类型,只要 condition 函数的返回值与之匹配即可:
graph.add_conditional_edges(start_node="classification",condition=lambda state: state["content_type"], # 返回 "news" | "blog" | "ad"mapping={"news": "news_processing_node","blog": "blog_processing_node","ad": "ad_filter_node"}
)
Conditional Edge 的进阶模式:多 Agent 协作中的动态角色分配
Anthropic three-agent harness 的条件跳转启示
Anthropic 2026 年 4 月公开的 three-agent harness 设计1,将 planner/generator/evaluator 三个角色组织成一个迭代式工作流:planner 生成任务步骤,generator 负责具体产出,evaluator 评估产出质量并决定下一步。
这个架构里的核心跳转逻辑本质上就是 Conditional Edge:
-
evaluator 判定质量达标 → 结束(END)
-
evaluator 判定需要小幅调整 → 返回 generator 微调
-
evaluator 判定方向需要修正 → 返回 planner 重新规划
这种「由评估结果决定路由」的模式,比简单的二路分支(通过/拒绝)更复杂,需要 condition 函数读取 evaluator 节点写入 State 的评估结果字段,再决定路由到 planner、generator 还是 END。
决策-执行双 Agent 架构
更工程化的实践是「决策 Agent + 执行 Agent」的分离架构:决策 Agent 负责任务分解和路由选择,执行 Agent 负责具体操作。
condition 函数在这里读取决策 Agent 写入 State 的任务类型字段,然后路由到不同的执行 Agent:
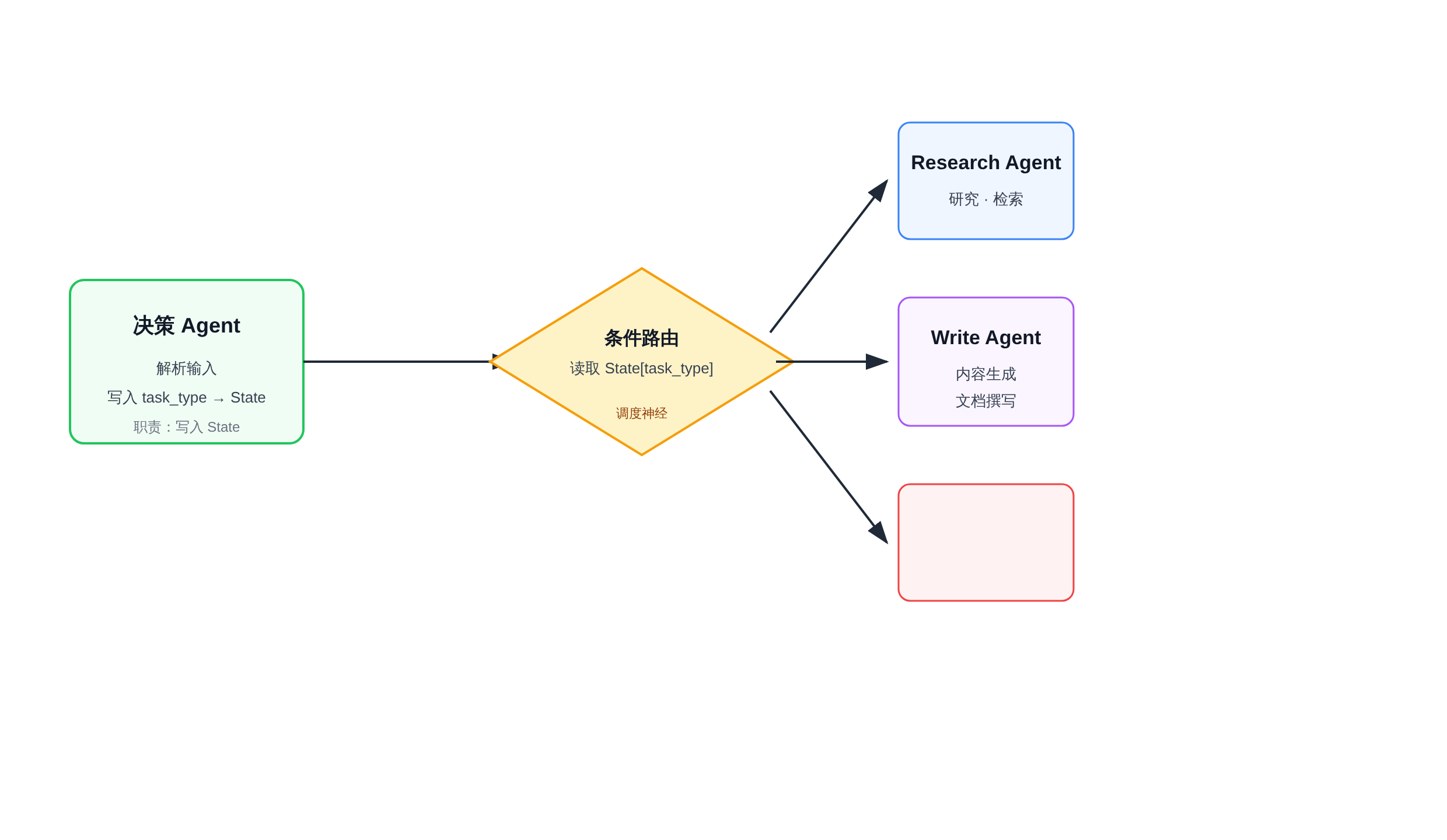
正文图解 1
结构化 Artifact 驱动的有状态路由 vs 简单 if-else
面试里可以进一步展开的点是:为什么用 Conditional Edge 而不是直接在节点里写 Python if-else 控制流?
核心差异在于「状态可观测性」和「工作流可视化」。
当 condition 函数控制路由时,整个路由决策被 LangGraph 的执行追踪系统记录,你可以在 LangSmith 里看到每一次路由的入参(State)和返回值(目标节点)。
但如果把分支逻辑写死在节点里,路由决策就变成了节点的内部实现,对外不可见,调试时只能靠 print 日志猜。
对于需要接受审计或需要向业务方解释工作流决策逻辑的场景,Conditional Edge 的可追溯性是硬需求。

PM 说要把路由规则可视化给客户看,我看了眼节点里的 if-else……
其他注意事项与工程实践
调试技巧:LangSmith tracing
condition 函数是工作流里的「调度神经」,一旦路由不符合预期,排查成本很高。
LangSmith 提供了完整的 tracing 功能,可以可视化每一次 condition 函数的执行:输入的 State、函数返回值、实际跳转的节点。
在 graph.compile() 之前配置环境变量即可开启:
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="your-langsmith-key"
export LANGCHAIN_PROJECT="conditional-edge-debug"
执行工作流后,登录 LangSmith 面板,找到对应 run,在 trace 树里展开 review::conditional_edge 节点,就能看到 condition 函数的完整执行上下文。
API 边界:调用时机
add_conditional_edges 必须在 graph.compile() 之前调用。编译后的图是只读的,无法动态添加或修改边。
这个约束在大多数场景下不是问题,但如果你的业务逻辑需要动态注册新的条件分支(比如根据运行时配置决定是否启用某个分支),LangGraph 本身不支持这种动态图修改,需要在 condition 函数里通过返回不同节点名来间接实现「条件启用/禁用」的效果。
版本注意:LangGraph 0.2.x 签名差异
LangGraph 在 0.2.x 版本对 condition 函数签名做了一次调整。
如果你看到旧代码里 condition 函数签名是 (state, config) 而不是你预期的 (state),这是正常的,两个版本在大多数场景下可以兼容,但如果你在升级过程中遇到签名不匹配的问题,优先检查代码里是否显式依赖了 config 参数。
可观测性建议:结构化日志记录路由快照
对于高频调用的生产系统,建议在 condition 函数里加结构化日志,记录每次路由决策的快照:
import structlog
logger = structlog.get_logger()def review_condition(state: WritingState) -> str:decision = END if state["is_approved"] else "write"logger.info("routing_decision",node="review",target=decision,is_approved=state["is_approved"],topic=state.get("topic", ""))return decision
这些日志对于排查生产环境的路由异常、统计各分支的流量分布、以及做 A/B 测试不同路由策略的效果都很有价值。
参考文献
- Anthropic Designs Three-Agent Harness Supports Long-Running Full-Stack AI Development
延伸入口
- 原文归档:https://tobemagic.github.io/ai-magician-blog/posts/2026/04/19/ai面试八股文-vol11-专题4conditional-edgeconditional-edge动态路由分支逻辑实现/
- 公众号:计算机魔术师
