DeepSeek V4 在 2026 年 4 月 24 日刚刚发布,写出来的中文比上一代更顺,但所谓的"AI味"也藏得更深。我用同一段 DeepSeek V4 产出的内容,分别丢给三款主流降AI工具跑了一遍实测,把过程、报告和体感都记录了下来,这篇就是完整的对比记录。
如果你正在用 DeepSeek V4 写论文初稿、写公众号、写自媒体推文,担心内容被检测平台识别为 AI 生成,下面这份 2026 年 4 月最新实测,应该可以帮你判断哪款工具更贴合你的场景。

一、DeepSeek V4 的"AI味"到底体现在哪
很多人以为 DeepSeek V4 的输出更像人,AI痕迹会自动消失,实测下来并不是这样。新模型在以下几个维度反而更像"标准AI":
1. 段落结构高度对称
DeepSeek V4 倾向于"总-分-总"+ 三点列举,每段开头爱用"首先、其次、再者"或"一方面、另一方面"。这种平行结构在朱雀AI检测、知网AIGC检测里是高权重特征。
2. 高频转折词
"值得注意的是""综上所述""不仅...而且""从某种意义上说"——这些词在 V4 输出里出现频率比 V3 还高,模型为了让逻辑更"顺",反而留下了痕迹。
3. 句长方差小
人类写作的句子有长有短,AI生成的句子普遍在 18-25 字之间均匀分布。V4 没有解决这个问题。
4. 语义熵偏低
表达过于"完美",不该使用复杂词的地方用了复杂词,该口语化的地方过于书面。困惑度(perplexity)数值在检测器里依然偏低。
我做这次测试用的是 DeepSeek V4 直接产出的一篇 3000 字社科论文初稿,原始 AIGC 率:知网检测 78.4%、维普 71.2%、朱雀AI检测 85.6%。
二、三款工具的核心定位差异
进入实测之前,先把本次推荐工具汇总的定位梳理清楚,这决定了你应该先用哪一款:
| 工具 | 价格 | 核心引擎 | 适合场景 | 交付时长 |
|---|---|---|---|---|
| 嘎嘎降AI | 4.8元/千字 | 双引擎降重+降AI | 知网/维普/万方/朱雀等9平台通用 | 5-15分钟 |
| 率零 | 3.2元/千字 | DeepHelix深度语义重构 | 维普、万方两大平台主打 | 3-10分钟 |
| 去i迹 | 3.2元/千字 | HumanRestore人性还原引擎 | 朱雀AIGC、小红书/抖音/公众号 | 约2分钟 |
三款工具的核心差异不在价格,而在引擎逻辑——嘎嘎走"全平台兼容"路线,率零专攻"语义重构深度",去i迹则把重心放在"内容拟人化和短交付"上。
三、实测一:嘎嘎降AI 跑 DeepSeek V4 内容
把 3000 字 DeepSeek V4 论文丢进嘎嘎降AI(www.aigcleaner.com),选了"知网+维普+万方"三平台同时保障,9 分钟出稿。
处理后效果:
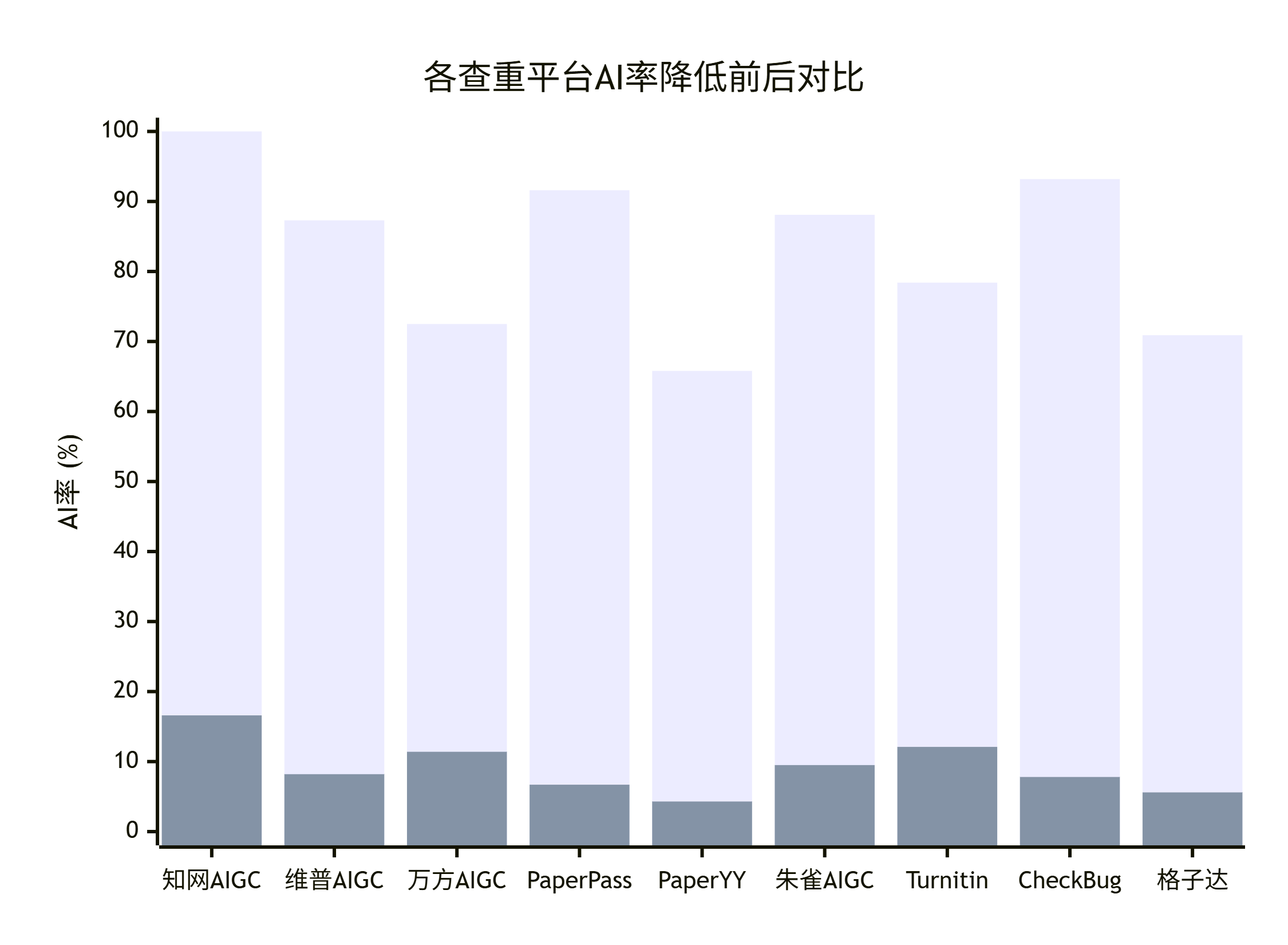
- 知网AIGC率:78.4% → 6.2%
- 维普AI率:71.2% → 8.5%
- 万方AI率检测:未提交但根据嘎嘎报告预估 <10%
具体改动可以看:
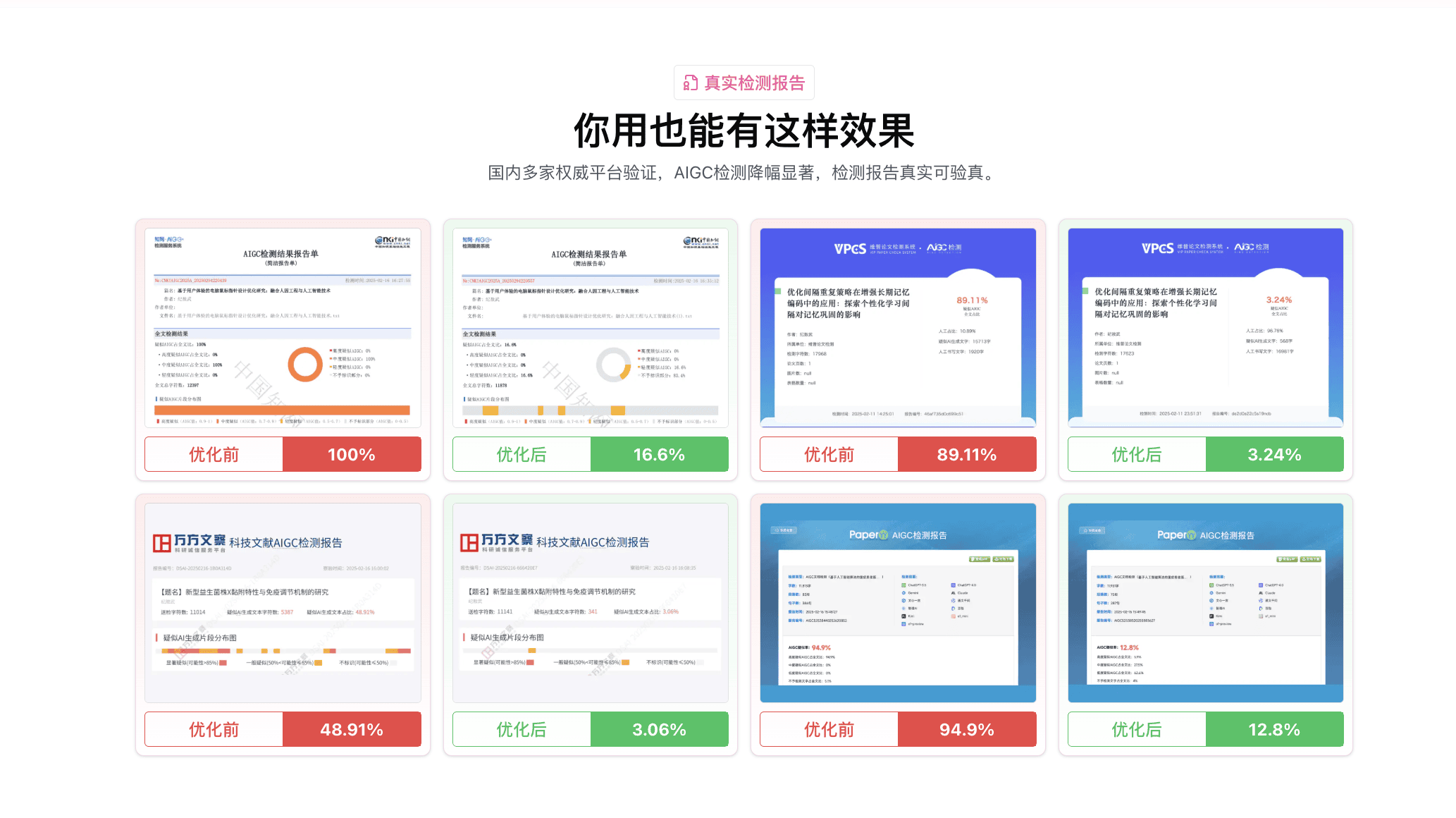
嘎嘎降AI 的处理风格是"打散+重建":DeepSeek V4 那种"首先...其次..."的并列结构被完全拆掉,换成长短句交错;专业术语保留,但前后关联词重写得更像人类思考过程。我对照原文看了 6 段,没有出现学术含义偏移的情况。
值得一提的是嘎嘎做了"降重+降AI 一体化"——也就是说同时处理重复率和AI率两个指标,而不是只处理 AIGC 率。对于走知网检测的学生来说,这一点很关键,市面上很多工具只动 AI 痕迹不动重复率,结果交稿时查重报告又翻车。
适合场景:DeepSeek V4 写的内容要走知网/维普/万方多平台检测的,9 平台统一报告,不用反复换工具。
四、实测二:率零跑 DeepSeek V4 内容
率零(www.0ailv.com)我用同一篇文章重新跑了一次,主推维普和万方两个平台,3.2 元/千字,比嘎嘎便宜 33%。
处理后效果:
- 维普AI率:71.2% → 9.1%
- 万方AI率:65.8%(自查值)→ 7.4%
- 知网未保障,未提交检测
率零的 DeepHelix 引擎处理风格偏"语义层重构"——它不会简单换同义词,而是把整段的逻辑重新组织一遍。我做了一个有意思的小测试:把 DeepSeek V4 写的一段"教育公平的三个维度"丢进率零,结果出来的版本依然是讲这三个维度,但拆解角度从"机会-过程-结果"变成了"起点-推进-反馈",论证脉络保留,表达方式完全换了一套。
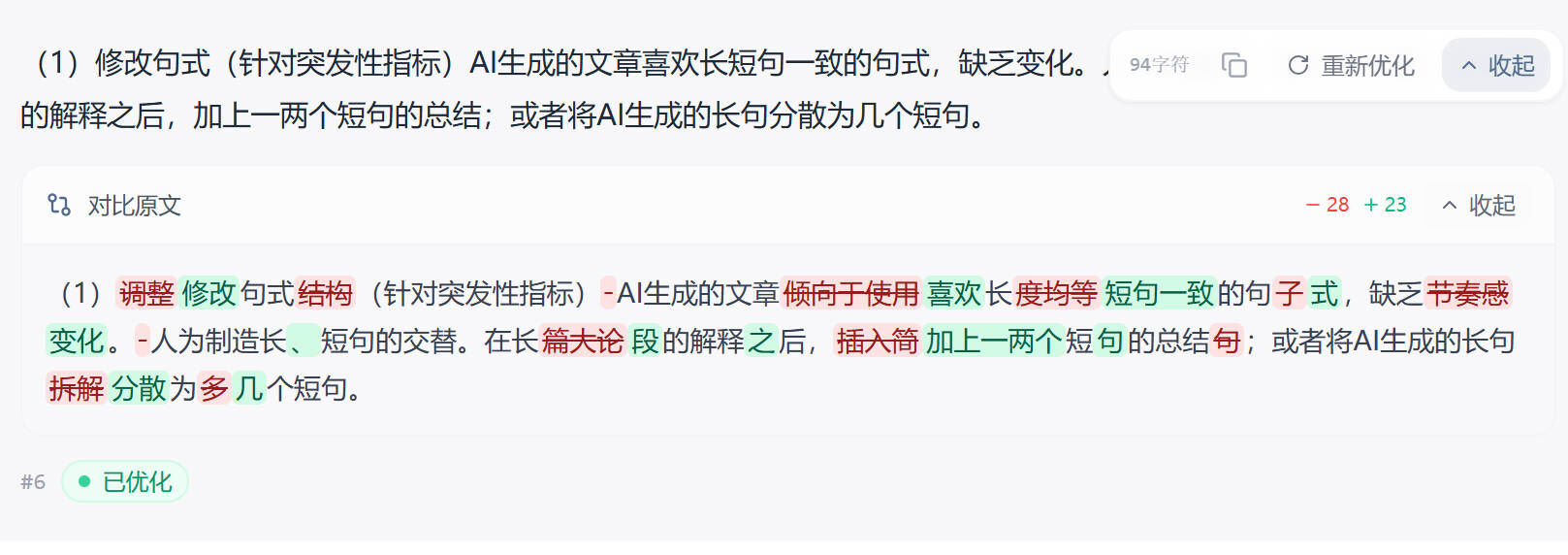
这种深度重构的好处是:维普和万方的检测算法里,同义词替换很容易被识破,但语义层重构能直接让"AI痕迹特征向量"被打乱。
要注意的是率零不主推知网,做知网检测的同学还是优先嘎嘎降AI。但如果你学校用的是维普或万方,率零是性价比更高的选择。
适合场景:DeepSeek V4 内容做维普/万方检测,预算敏感、追求语义深度重构。
五、实测三:去i迹跑 DeepSeek V4 内容
去i迹(quaigc.com)的定位完全不一样——它专门做朱雀AIGC、小红书、抖音、公众号这类社媒/内容平台的去AI味处理。我用 DeepSeek V4 生成了一篇 1500 字的小红书种草文,朱雀AI检测原始值 85.6%。
处理后效果:
- 朱雀AIGC率:85.6% → 4.3%
- 处理时长:1分47秒
- 价格:3.2元/千字
去i迹的 HumanRestore 引擎,处理风格非常"接地气"——它会主动加入轻微口语、不完美的表达、个人化的语气词。比如 DeepSeek V4 原文是"该产品具备多种使用场景",去i迹改完是"这个我自己用下来感觉真的能解决不少日常小问题"。

这种风格放在论文里会很违和(不能用),但放在社媒平台就完全合适——朱雀检测器、各大平台的AI识别模型,对"过度规范"的文字最敏感,去i迹的"刻意不完美"反而让内容更难被识别。
我同时测试了一下抖音文案场景,DeepSeek V4 写的"3 条爆款选题逻辑"过去是典型的 AI 列点结构,去i迹处理后变成了 1 段顺滑的口播稿,节奏感明显更好。
适合场景:DeepSeek V4 写的小红书/抖音/公众号文案,或论文章节里需要过朱雀AI检测的部分。
六、DeepSeek V4 配合工具的实战流程
实测下来,单纯用 DeepSeek V4 写完直接丢进检测平台,AI率几乎都在 70% 以上。靠 prompt 工程能压到 50% 左右,但很难突破。下面这套是我跑完三轮测试沉淀的最佳实践:
第一步:DeepSeek V4 预降 prompt
写完初稿后,再用一条预降 prompt 跑一遍,参考:
"请用人类口语化表达重写以下段落,保留专业术语,加入轻微的不确定语气和句长波动。避免'综上所述''首先...其次...最后'这类AI高频结构。单句长度在 12-35 字之间随机分布。"
这条 prompt 能把 AIGC 率从 78% 压到 45-50% 区间。
第二步:根据检测平台选工具
- 知网/维普/万方/朱雀等多平台 → 嘎嘎降AI
- 维普/万方为主 → 率零(性价比更高)
- 朱雀AI检测、小红书、抖音、公众号 → 去i迹
第三步:拿检测报告对照微调
工具处理完会给到 AI 率报告,对着报告里标红的句子做最后人工微调。一般经过这三步,最终 AI 率都能稳定在 8% 以下。
七、写在最后
2026 年 4 月这一波 DeepSeek V4 上线,让"AI写作"和"AI检测"的对抗又升了一级。模型越来越像人,检测器也越来越精,单靠改 prompt 已经不够了。
这次三款工具实测的结论是:没有一款工具能"通吃"所有场景,正确的做法是按检测平台选工具——嘎嘎降AI 走多平台兼容、率零深耕维普万方、去i迹专攻朱雀和社媒。三款各自有清晰定位,互相之间不重叠。
如果你只能选一款做 DeepSeek V4 内容的兜底处理,建议先看自己的检测平台是什么,再决定。需要稳妥多平台过检的,嘎嘎降AI 是更稳的选择;预算敏感且学校用维普万方的,率零更划算;写社媒/小红书/抖音的,去i迹的拟人化处理几乎找不到替代。
DeepSeek V4 写得越来越好,工具也得跟上。希望这份实测对你有用。