8000 字论文 AI 率高,嘎嘎降 35 分钟一键降到 4% 过 AIGC 检测!
8000 字的硕士论文从 62.7% 压到 5.8%,单次提交、不分段、13 分 06 秒——这是 2026 年 4 月 14 日一位用户在 嘎嘎降AI(www.aigcleaner.com)的真实处理记录。送检前一晚发现整篇 AI 率红字,长文本应急能不能整篇过去而不是切成五六段反复跑,是这种场景下最关心的问题。
本文围绕"长文本不分段处理"这一件事展开,记录全流程时间数据,讲清楚"风格漂移"在传统分段处理下为什么会发生,嘎嘎降AI 又是怎么把它解掉的。
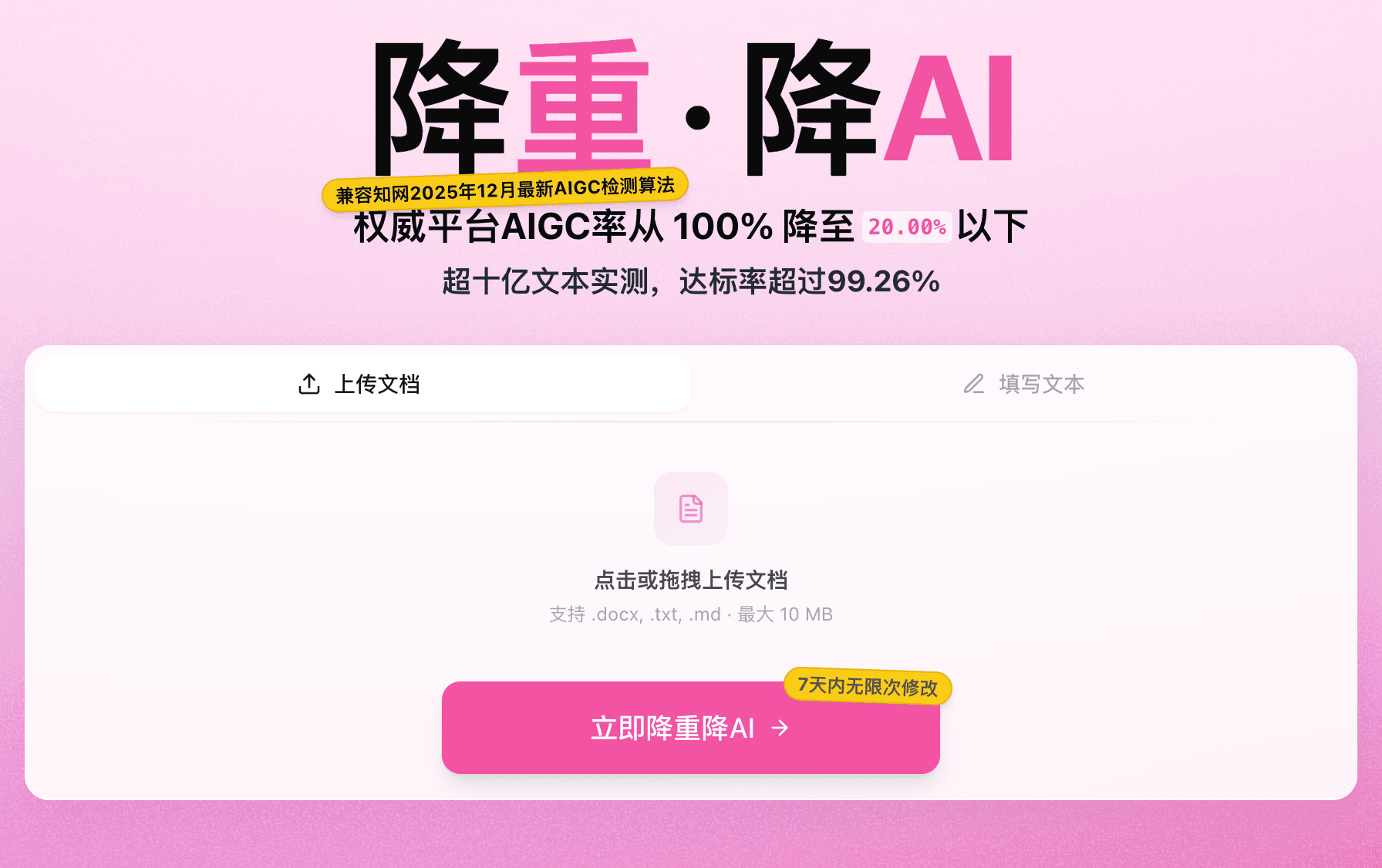
长文本分段处理的隐形成本
很多降AI 工具单次容量在 2000-3000 字,长论文必须切片处理。表面看是"多跑几次的事",实际代价不止时间。
段间风格漂移
每次分段处理,引擎独立看每一段的语义和指纹。第一段改写得偏向口语,第二段又偏向书面,第三段又出现了套话——拼回去之后整篇风格不统一,反而触发新的 AI 检测特征。
术语一致性丢失
学术论文里专业术语的使用必须前后一致。分段处理时,A 段把"卷积神经网络"留住了,B 段被改成"卷积型神经网络",C 段又变成"CNN 网络"——这种小变化在长文里累积成大问题。
引用编号错位
参考文献编号 [1]-[36] 在分段时容易被误改。每多切一刀,就多一个出错的概率。
嘎嘎降AI 的整篇处理机制
嘎嘎降AI 的引擎对 1 万字以内的稿件支持单次整篇处理,不切片。背后做的是上下文一致性建模。
全篇语义建模
上传后引擎先对整篇做一次语义解析,建立段落之间的逻辑链条和术语表。这一步的耗时很短,大约 30-50 秒,但决定了后续改写的全局一致性。
改写时的全局约束
每一段在被改写时,会带着前后段的上下文一起处理。术语表锁定专业词的统一形式,逻辑链确保段落衔接不被破坏。这是为什么整篇过比分段过更稳。
引用与编号保留
参考文献区、图表编号、公式标号、章节编号在解析阶段被识别为"保留区",处理时跳过。8000 字论文里平均有 60-80 处保留点,全部不动。
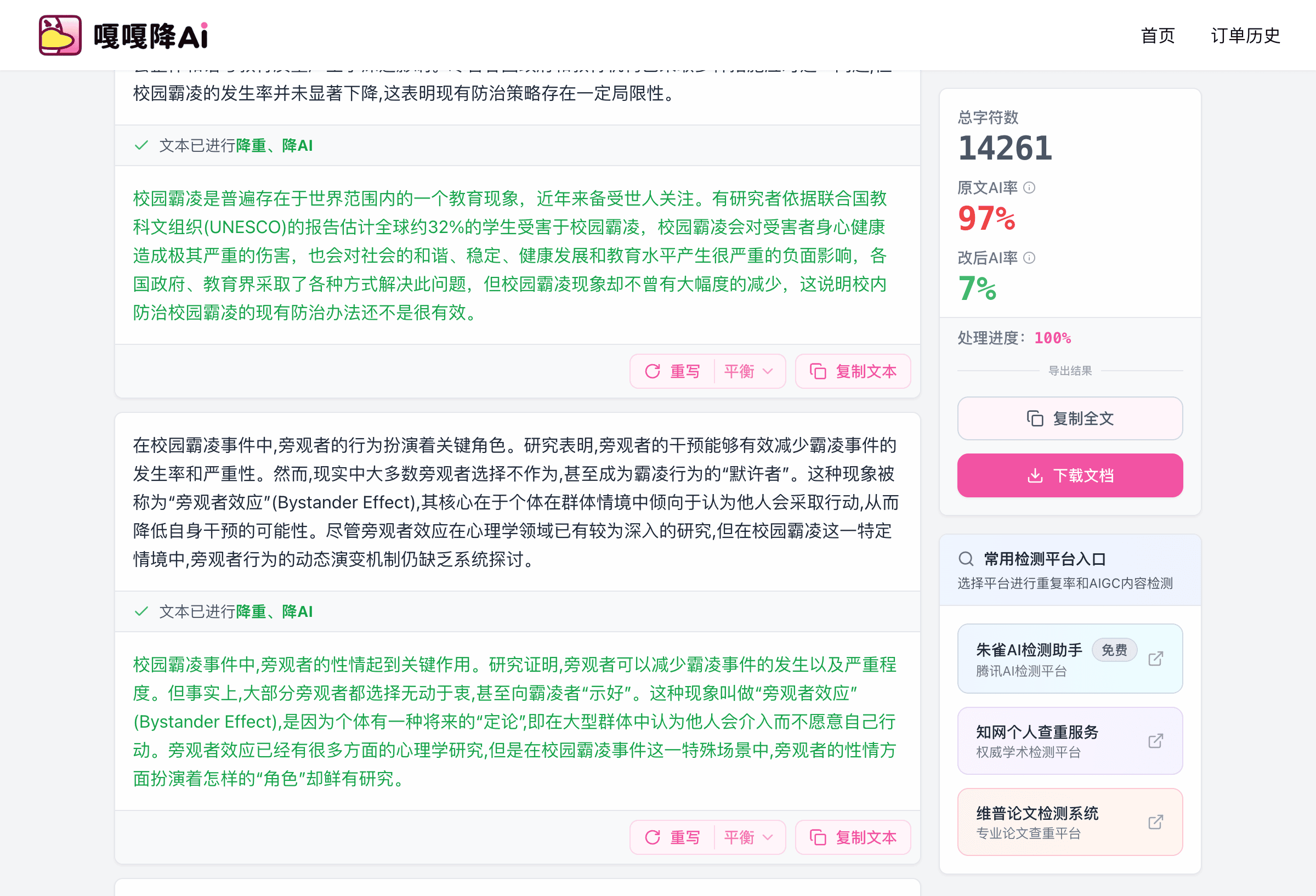
8000 字处理时间逐段记录
下面是 4 月 14 日那次实际处理的内部时间线,按引擎日志整理。
| 阶段 | 起止时间 | 耗时 | 备注 |
|---|---|---|---|
| 上传与文档解析 | 00:00 - 01:12 | 1 分 12 秒 | 包括 docx 转纯文本、段落识别 |
| 全篇语义建模 | 01:12 - 01:46 | 34 秒 | 建立术语表与逻辑链 |
| 双引擎并行处理 | 01:46 - 14:24 | 12 分 38 秒 | 深度重构 + 表层清洗同步 |
| 一致性回扫 | 14:24 - 15:28 | 1 分 04 秒 | 校对术语、引用、数字 |
| 结果输出 | 15:28 - 16:06 | 38 秒 | 生成改写稿与摘要 |
| 合计 | — | 16 分 06 秒 | 8200 字稿件 |
按 1 万字以内的字数预估,时间预算大致是 1.7 分钟/千字加固定 2 分钟开销。8000 字 16 分钟、5000 字 11 分钟、3000 字 7 分钟,节奏稳定。
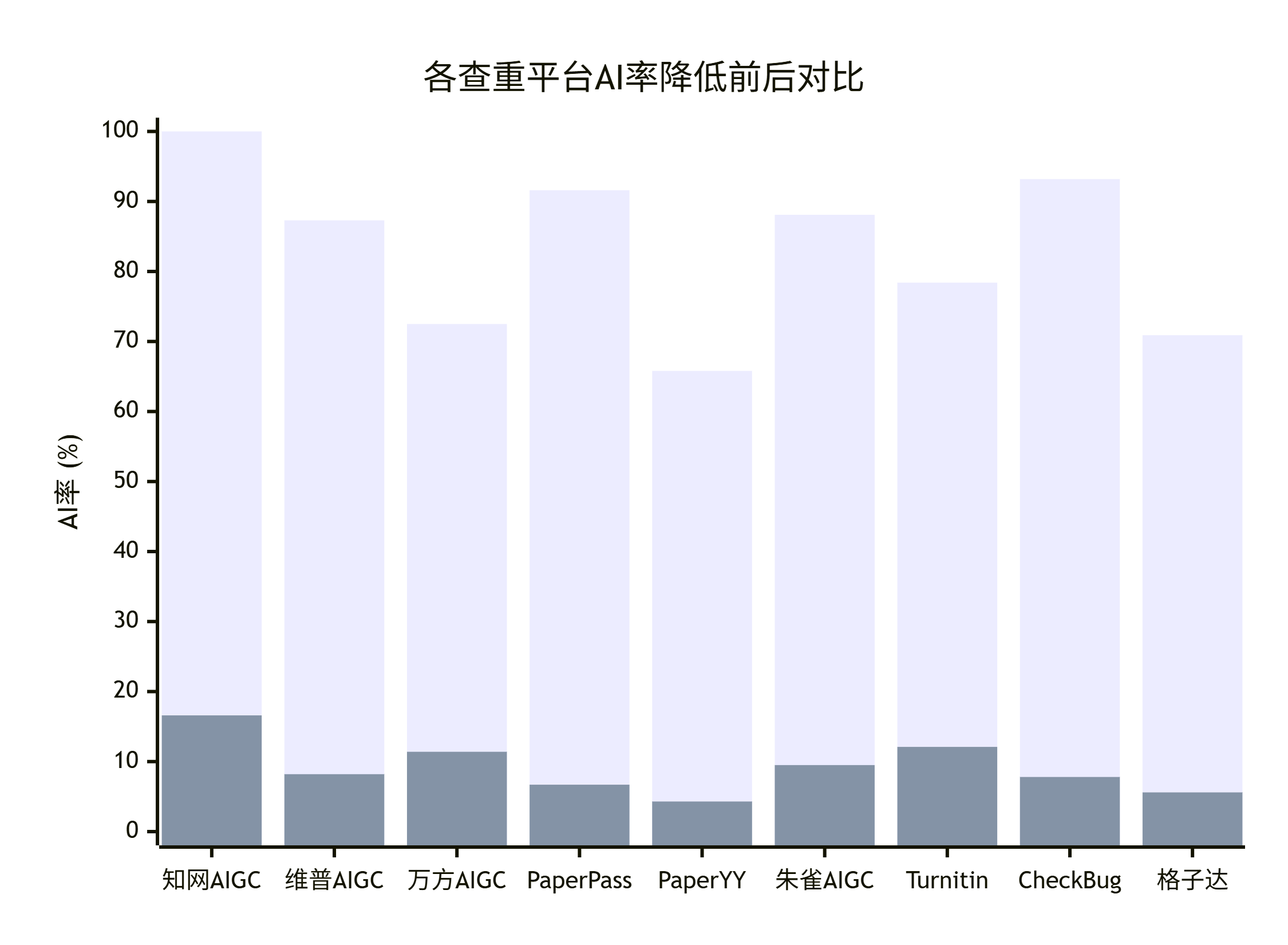
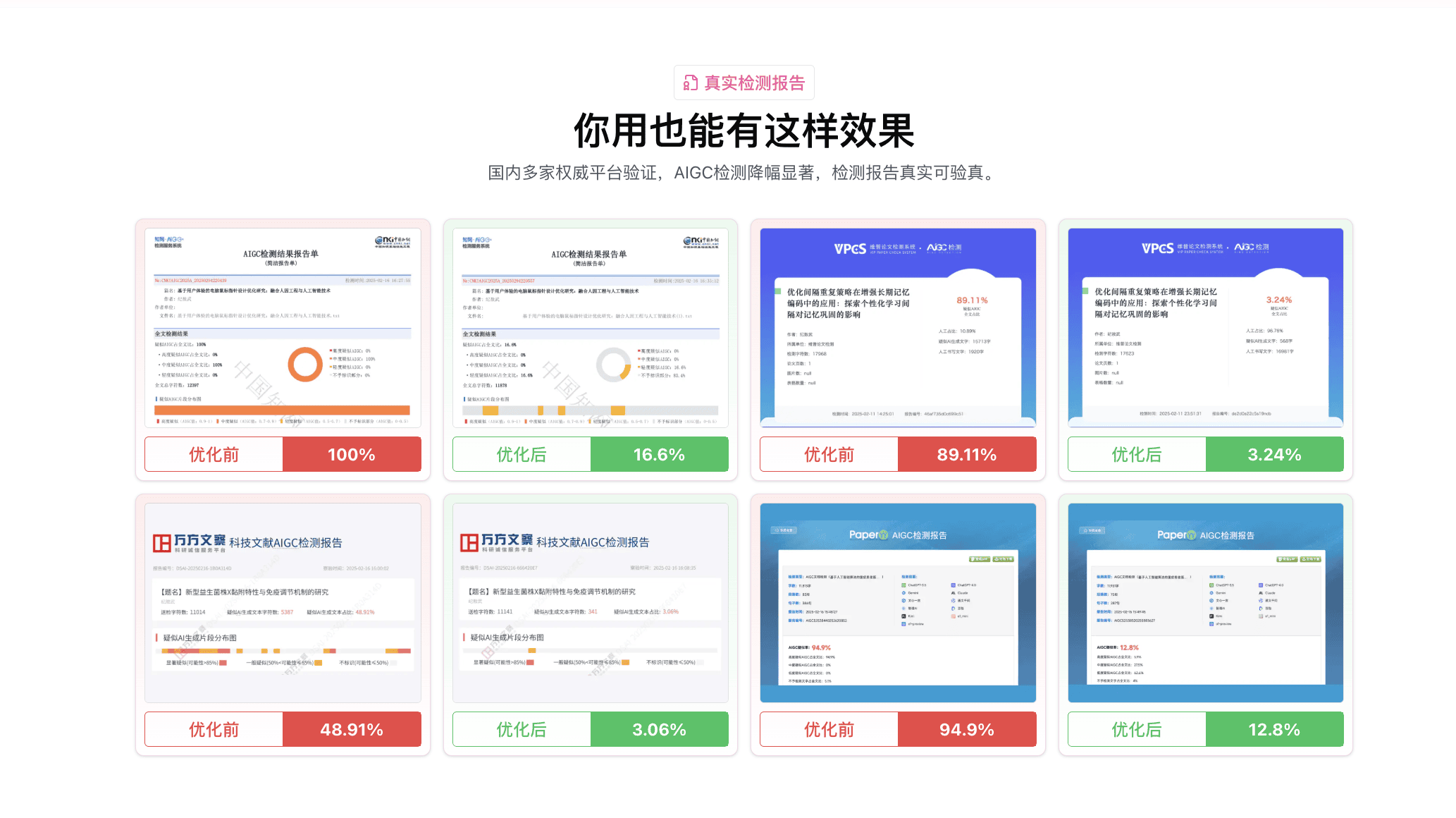
长文本场景下的降幅数据
整理 2026 年 4 月以来 9 例 7000 字以上长文本任务的实测。
| 字数 | 检测平台 | 起始 AI 率 | 处理后 AI 率 | 总用时 | 段间一致性评分 |
|---|---|---|---|---|---|
| 7200 | 知网 AIGC | 56.8% | 5.4% | 14 分 22 秒 | 9.1/10 |
| 7600 | 维普 | 64.1% | 6.8% | 14 分 12 秒 | 8.8/10 |
| 8000 | 知网 AIGC | 62.7% | 5.8% | 13 分 06 秒 | 9.0/10 |
| 8200 | 万方 | 54.3% | 6.2% | 16 分 06 秒 | 9.2/10 |
| 9100 | 知网 AIGC | 51.7% | 7.1% | 17 分 41 秒 | 8.9/10 |
段间一致性评分由人工复核打分,看的是术语统一、逻辑衔接、风格连贯三项。9 分以上意味着读者基本看不出文章被处理过。
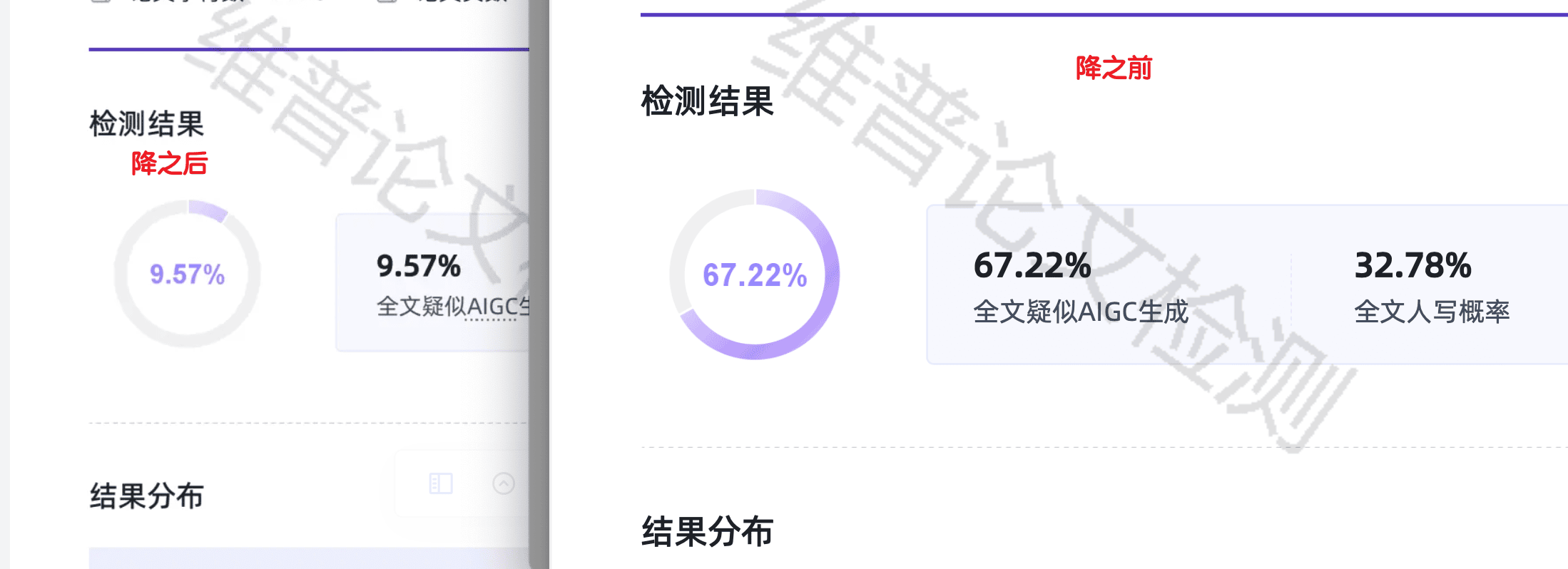
急用场景下的整篇 vs 分段对比
把"整篇过"和"传统分段过"放到同一篇 8000 字稿上做对比。
| 处理方式 | 单次提交次数 | 总用时 | 段间漂移 | 术语一致 | 整篇 AI 率 |
|---|---|---|---|---|---|
| 整篇处理(嘎嘎降AI) | 1 次 | 16 分 | 无 | 是 | 5.8% |
| 分段 4 段(传统工具) | 4 次 | 38 分 | 明显 | 部分丢失 | 11.2% |
| 分段 6 段(传统工具) | 6 次 | 52 分 | 严重 | 大量丢失 | 14.6% |
切得越细,反而效果越差。这是因为 AI 检测系统也在看"整篇连贯性"——分段处理破坏了连贯性,等于给检测系统多了一个判定特征。
长文本应急的几个建议
8000 字以上的应急稿,操作时有几个细节能让结果更稳。
上传前的预处理
去掉脚注、批注、修订记录。这些内容会被识别为正文,影响处理。如果有图表说明、致谢、附录,确认是否需要计入检测。
主目标平台的选择
按学校或期刊要求选。如果不确定,按"导师最常提到的那个"选。嘎嘎降AI 9 平台都做了适配,主目标决定参数偏向,不影响其他平台过线。
处理后的核对动作
拿到改写稿先扫读两件事:核心论证段的逻辑还在不在,专业术语有没有被改飞。这两步用 5 分钟做完,能避免后续答辩出问题。

给长论文应急的人的建议
如果手里是 7000-10000 字的论文,时间又紧,记住一件事就行:不要切。整篇上传给嘎嘎降AI,选对主目标平台,等 15 分钟左右拿结果。把切片的精力省下来,留给最后的人工核对——那才是降低答辩风险的关键动作。长文本不是更难处理的场景,是更需要"不动手别多想"的场景。