
摘要:为什么你让 AI 再想 10 个点子,它还是绕着同一个脑回路转?arXiv 2601.11227 研究揭示了一个反直觉的答案:模型输出的多样性不只取决于 temperature,还取决于它用什么语言「思考」。
你大概见过这个场景:给AI发了三个问题,它用同一个解决框架回答了三次。
temperature调到0.9,换了几个prompt说法,让它「再想想」「多想几个角度」,出来的答案还是那几条熟悉分支,像一台只会走固定舞步的老式点唱机。
这不是个例。
这是工程现场里真实存在的结构性困境——不是prompt写得不够好,而是模型在给定语言下探索的向量空间是相对固定的,切换temperature只是在这个空间里打转的幅度不同,并不是在改变它探索的方向。

等等,我调了半天temperature你告诉我方向就不对?
Language of Thought:论文里意外告诉我的事
TechWalker最近发了一篇文章,提到了一个反直觉的研究方向:不改模型、不重训,只是切换模型的「思考语言」,输出多样性就会发生变化。TechWalker解读 对应的论文编号是arXiv:2601.11227,标题是《Language of Thought Shapes Output Diversity in Large Language Models》,提交于2026年1月,2026年4月修订。arXiv:2601.11227
核心发现一句话就说完了:模型输出的多样性不只取决于采样参数,还取决于它用什么语言「思考」 。
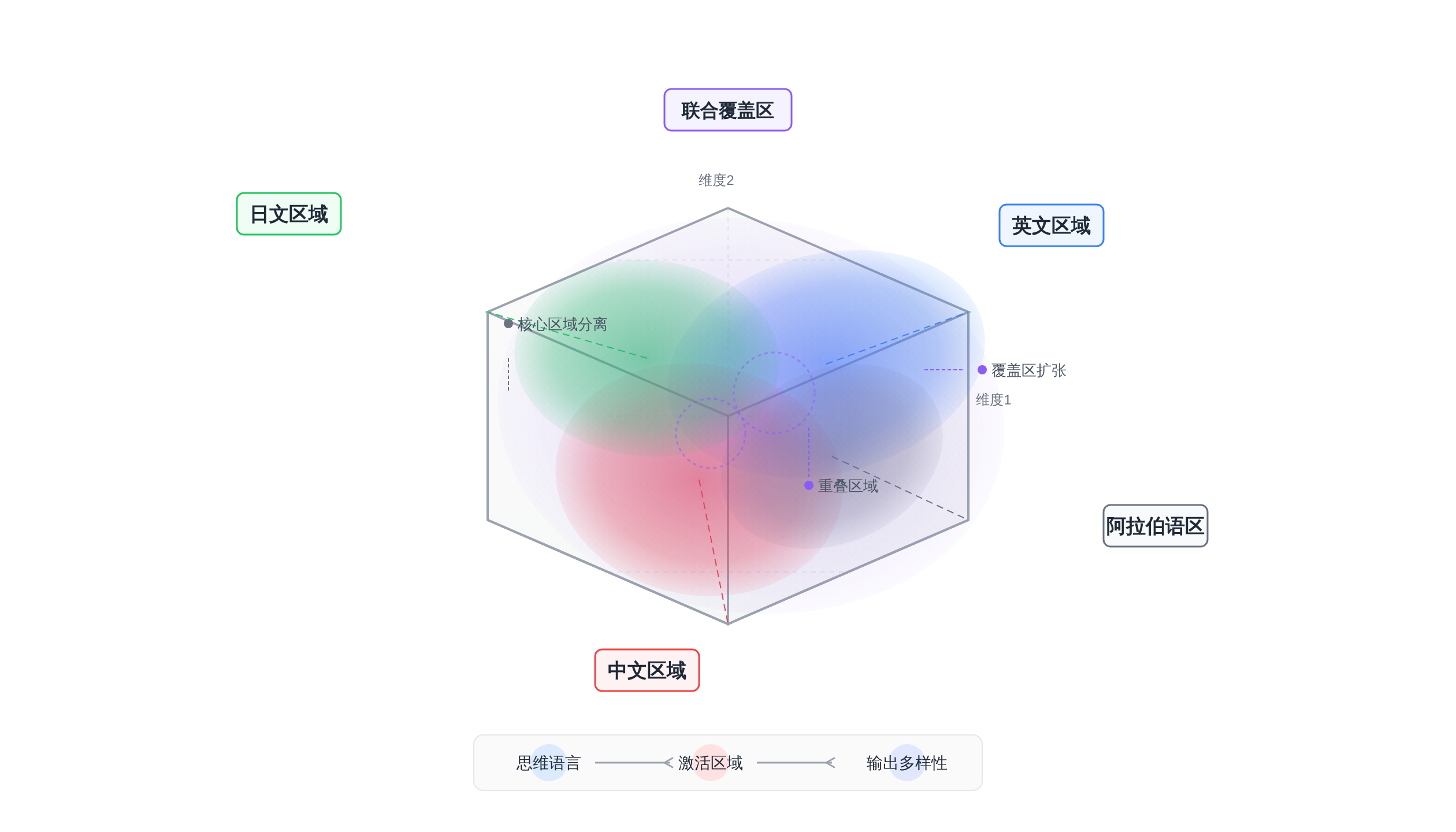
这个假说来自认知科学里的「思维语言」假说:人类思考依赖某种内部的、跨语言的「思维语言」,而语言模型在预训练过程中,不同语言的知识和推理模式被编码进了模型参数的不同区域。
论文做了两组关键实验:单一语言采样(Single-Language Sampling) 和混合语言采样(Mixed-Language Sampling) 。
前者是在固定语言下反复采样;后者是在不同思维语言之间切换,然后将采样结果聚合。
实验结果很有意思。将思维语言从英语切换到非英语语言后,输出多样性一致性地提高 ——而且距离英语越远的语言,多样性增益越大。arXiv:2601.11227
论文没有把这写成一句结论就收掉,而是做了更细粒度的消融分析:当日语、中文、阿拉伯语分别作为思维语言时,它们各自激活的向量空间区域与英语区域的重叠程度不同,重叠越少的语言带来越大的多样性提升 。
更有价值的是 compositional effect :当把多个思维语言的采样结果聚合起来之后,整体的多样性上限比单一语言单次饱和后再采样要高得多。论文原文
这说明不同思维语言探索的空间是部分重叠但不完全相同的,聚合后形成了一个更大的联合覆盖区。

这个发现有点东西,但怎么落地成可用的Skill?
正文图解 1
这个Skill的定位:不是翻译层,是创意扩展层
所以问题来了:能不能把这个机制做成一个可复用的Skill,让它变成Agent系统里的一个可控组件?
答案是:可以,但它的定位必须说清楚。
这不是翻译工具。 翻译工具改变的是输出语言本身,而多语言思维采样的本质是:** 只改思维语言,不改输出语言** 。
用户看到的最终答案仍然是同一语言,但产生这个答案的推理路径经过了不同语言视角的探索与校验。
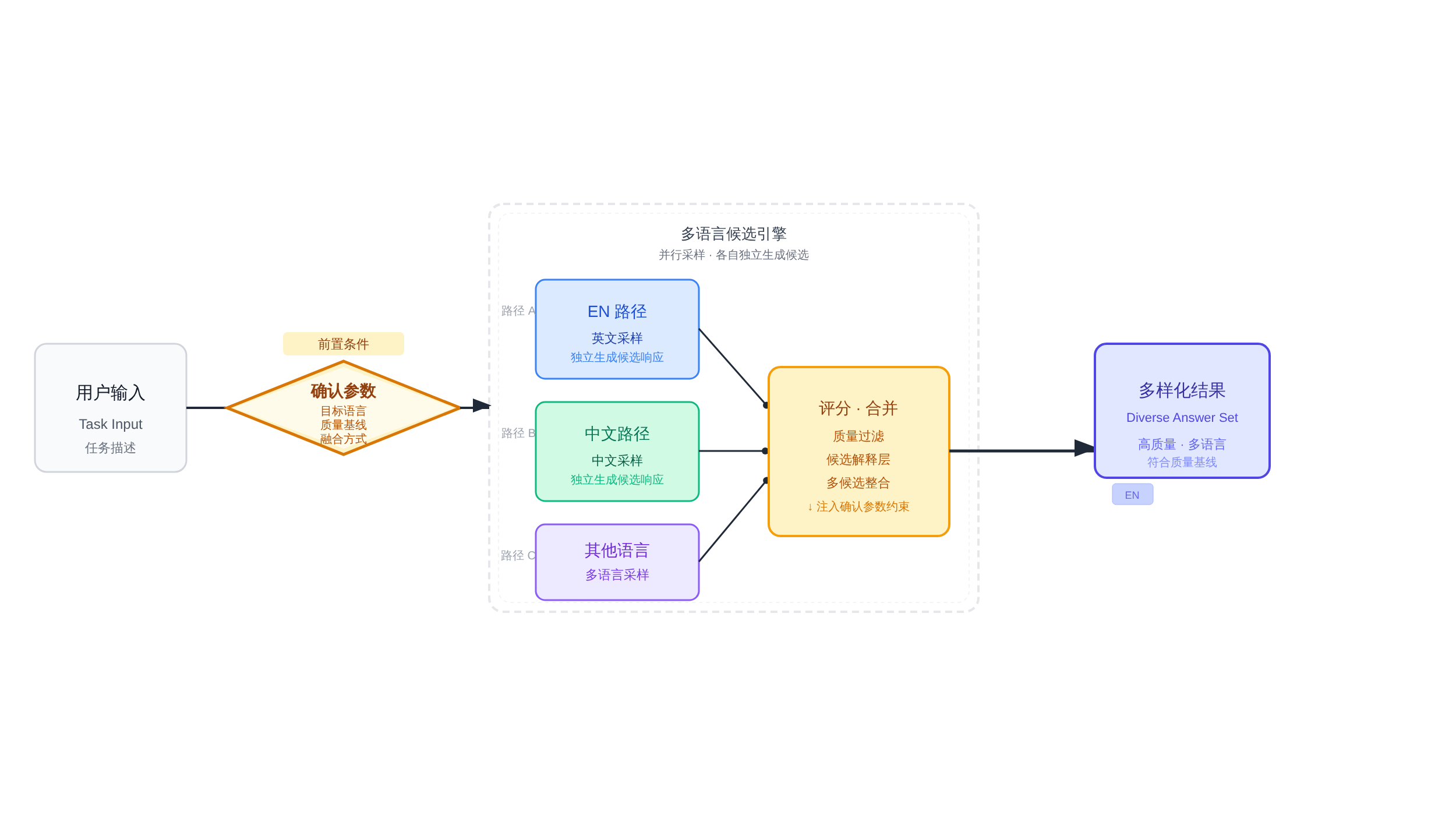
核心价值主张是可控的多语言候选合成 :给定一个任务,先通过一个discuss gate确认几个关键参数——任务目标是什么、输出语言是什么、质量基线在哪里、预算上限是多少、准备激活哪些思维语言、最终用哪种方式融合候选结果——然后才开始执行多语言候选生成,而不是上来就直接批量跑prompt。
这个设计是为了避免一个常见陷阱:语言池不是越大越好,也不是随便选几种语言塞进去就能提升多样性 。
不同任务类型对语言池的要求不同,开放性创意任务和结构化分析任务需要不同的语言组合和采样权重。discuss gate强制在执行前先想清楚这些参数,而不是用暴力枚举去撞运气。

所以预设语言池本身也是个调参活儿
在Agent系统架构里,这个Skill的角色是 controllable creative expansion layer :它不是替换模型本身,也不是替代Agent的主决策链路,而是在主链路旁边加一个可控的多样性扩展节点,让原本「一条路径出答案」的推理过程变成「多路径探索→候选评估→合并输出」的结构化流程。
正文图解 2
执行流程全览:从baseline到合并输出的六步设计
光有定位不够,可执行性是关键。这个Skill的完整执行链路分为六步:
第一步:baseline建立。 用默认语言(通常是英语或用户母语)跑一次标准推理,建立答案质量基线和解决框架基准。
这一步是为了给后续的多样性评估提供参照点——不是所有偏离baseline的答案都是「更好」的,有些是跑偏,有些是真正的视角扩展。
第二步:multilingual candidates生成。 基于discuss gate确认的语言池,并行触发多语言思维采样。
每个语言路径独立跑推理,保留各自的中间步骤和候选答案。这一步的并行性很重要 ——串行语言切换会带来时间成本叠加,而并行化是多语言采样的工程可行性前提。第三步:mixed sampling聚合。 将所有语言路径的候选结果收集到同一个候选池,进行去重和初步质量过滤。
compositional effect在这一步体现:原本在单一语言下已经饱和的采样点,通过语言切换引入了新的探索方向,候选池的上限被抬高了。
第四步:scoring & filtering。 对候选池里的每个答案打分,分数维度包括:与baseline的差异度、答案质量、与原任务目标的相关性、潜在风险标记。
过滤掉低于质量基线的候选,保留top candidates进入最终决策。
第五步:merge或side-by-side输出。 两种输出模式:merge模式将top candidates合并成一个综合答案,同时附带各语言视角的贡献说明;
side-by-side模式保留多候选并行展示,由用户或上层Agent自行选择。两种模式对应不同的使用场景,没有绝对的优劣。第六步:why_not_selected说明。 对于最终未入选的候选,给出简要的未入选原因说明。
这不是可选项,而是Skill设计的一部分——它让整个采样过程可审计、可解释,避免了「黑箱跑了一批答案然后随机挑一个」这种不可控状态。
下面是一个简化的核心逻辑代码示例,展示disucss gate和并行采样的控制流:
class MultilingualThinkingSampler:def __init__(self, model, language_pool: list[str], quality_baseline: float):self.model = modelself.language_pool = language_pool # e.g., ['en', 'zh', 'ja', 'ar']self.quality_baseline = quality_baselinedef discuss_gate(self, task: dict) -> dict:"""确认任务参数,返回采样配置"""return {'task_objective': task['objective'],'output_language': task['output_lang'],'budget': task.get('max_candidates', 5),'active_languages': self._select_languages(task),'merge_mode': task.get('merge_mode', 'merge')}def _select_languages(self, task: dict) -> list[str]:"""按任务类型预设语言池,不是动态随机"""domain = task.get('domain', 'general')if domain == 'creative':return self.language_pool # 创意任务用全语言池elif domain == 'analysis':return ['en', 'zh'] # 分析任务精简语言池return ['en'] # 默认保守def sample(self, task: dict) -> dict:config = self.discuss_gate(task)# Step 1: baselinebaseline = self.model.generate(task['prompt'], lang='en')# Step 2-3: parallel multilingual samplingcandidates = []for lang in config['active_languages']:result = self.model.generate(task['prompt'], lang=lang)candidates.append({'language': lang,'content': result,'embedding': self._get_embedding(result)})# Step 4: scoring & filteringscored = self._score_and_filter(candidates, baseline)# Step 5: merge or side-by-sidefinal = self._merge_or_present(scored, config['merge_mode'])return finaldef _merge_or_present(self, scored: list, mode: str) -> dict:if mode == 'merge':return self._merge(scored)return {'type': 'side_by_side', 'candidates': scored}
代码结构清楚了,但实际跑起来效果怎么样?
⚠️ 踩坑提醒:语言池需要按任务类型预设。 不是所有语言组合对所有任务都有效。研究表明,距离英语越远的语言多样性增益越大,但这不意味着应该无脑选「最远」的语言。
更重要的是语言背后的知识覆盖差异:一个涉及日本商业文化的任务,日语思维路径大概率比阿拉伯语路径提供更高的相关多样性增益。
所以语言池应该按任务领域和目标受众进行人工预设,而不是动态随机。
最终输出结构不是一条答案,而是一组结构化信息:
baseline → 基准答案与框架
candidate_set → 全量候选池(含各语言路径原始输出)
top_candidates → 通过质量过滤的top N候选
final_output → merge或side-by-side最终结果
why_not_selected → 未入选原因说明
这个结构是刻意设计的:它把「多样性」和「质量控制」解耦了——多样性由语言路径负责,质量控制由评分和过滤机制负责,两者各司其职,而不是混在一起最后靠一个主观判断收尾。
适用边界:它能扩展角度,但不能扩展事实
这个Skill的有效范围需要诚实划定。
适用场景: 方案策划、创意生成、策略分析、内容创作、多角度头脑风暴——这类任务的核心需求是「覆盖更多的可能性空间」,而不是「找到唯一的正确答案」。
多语言思维采样在这些场景下提供的增量价值最明显:同一道战略问题,英语思维路径、中文思维路径和日语思维路径很可能给出不同的风险偏好、时间视野和假设前提,而这些差异本身就是有价值的决策参考。
不适用或需谨慎的场景: 医疗、法律、金融和其他高风险事实性领域。在这些领域,多语言思维采样** 可以扩展分析角度** ,但不能替代事实核查 。
切换思维语言不会改变模型对事实性知识的边界——一个在英语下对医学数据的错误判断,切换到日语思维路径后仍然是错误判断,只是可能换了一种表述方式包装起来。
这种包装在高风险领域反而是危险的,因为它可能让错误答案看起来更像「来自不同视角的合理意见」。
Benchmark现状需要诚实说明: 目前workflow能力已经实现可用状态,但尚无系统的量化benchmark数据——不同任务类型下语言池的最优配置、compositional effect在实际工作流中的衰减曲线、scoring机制的参数调优,这些都需要跑更多的对照实验才能给出可靠的工程建议。
现在谈「最佳实践」还早,读者应该把这个Skill理解为一个有理论基础、有工程实现、值得按需试用的工作流组件,而不是一个已经调优完毕的开箱即用产品。
如果你也遇到过「让AI多想几个点子,结果还是同一个脑回路」的问题,可以关注『计算机魔术师』,在文末留言区留言。我会把这个多语言思维采样Skill整理出来,发给需要的小伙伴。
参考文献
-
TechWalker,《语言会影响大模型的创造力?最新研究揭示多语言思维采样如何提升AI输出多样性》,2026-01-20。https://www.techwalker.com/2026/0120/3177307.shtml
-
arXiv:2601.11227,《Language of Thought Shapes Output Diversity in Large Language Models》。https://arxiv.org/abs/2601.11227

这个Skill怎么拿到?评论区见
延伸入口
- 原文归档:https://tobemagic.github.io/ai-magician-blog/posts/2026/05/08/技术趣闻-ai-agent-skill为什么-ai-总绕着同一个脑回路转多语言思维采样让-agent-从给一个答案变成给一组方案/
- 公众号:计算机魔术师
