前言
本文介绍了Coordinate Attention(坐标注意力)机制及其在YOLOv11中的结合应用。坐标注意力机制将位置信息嵌入通道注意力,通过坐标信息嵌入和坐标注意力生成两个步骤,实现通道关系和长距离关系的编码,解决了传统通道注意力忽略位置信息的问题。该机制通过两个1D特征编码过程聚合特征,捕获长距离依赖并保留精确位置信息,生成方向感知和位置敏感的注意力图,增强感兴趣对象的表示。我们将CoordAtt模块集成进YOLOv11,替代部分原有模块。实验表明,该机制在ImageNet分类及目标检测、语义分割等下游任务中表现出色。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
@
- 前言
- 介绍
- 摘要
- 创新点
- 文章链接
- 基本原理
- Coordinate Attention 机制
- Coordinate Attention 模块
- 实现
- Coordinate Attention 机制
- 核心代码
- 实验
- 脚本
介绍

摘要
近期移动网络架构研究表明,通道注意力机制(如压缩-激励注意力)在提升模型性能方面展现出显著成效,然而此类方法普遍忽视了位置信息的重要性,而空间选择性注意力图的生成恰恰需要精确的位置感知能力。针对这一局限性,本文提出了一种创新性的坐标注意力机制,通过将位置信息有效嵌入到通道注意力框架中,为移动网络设计提供了新的解决方案。与传统的通过二维全局池化将特征张量转换为单一特征向量的通道注意力方法不同,坐标注意力机制将通道注意力分解为沿两个正交空间方向分别进行特征聚合的一维特征编码过程。这种设计策略使得模型能够沿一个空间方向捕获长距离依赖关系,同时在另一个空间方向上保持精确的位置信息。随后,生成的特征图被分别编码为一对具有方向感知和位置敏感特性的注意力图,这两种互补的注意力图可协同作用于输入特征图,从而显著增强目标对象的表征能力。所提出的坐标注意力机制具有结构简洁、易于实现的优势,能够灵活集成到经典移动网络架构(如MobileNetV2、MobileNeXt和EfficientNet)中,且几乎不引入额外计算开销。大量实验验证表明,该注意力机制不仅在ImageNet图像分类任务中表现优异,更值得注意的是,在下游任务包括目标检测和语义分割中展现出更为突出的性能提升。
创新点
- 将位置信息嵌入到通道注意力中,提升了移动网络设计的性能。
- 通过两个1D特征编码过程聚合沿着两个空间方向的特征,捕获长距离依赖性,并保留精确的位置信息。
- 生成方向感知和位置敏感的注意力图,可以应用于输入特征图,增强感兴趣对象的表示。
- 简单易用,几乎不增加计算开销,并且可以灵活地插入经典的移动网络结构。
- 在ImageNet分类以及目标检测和语义分割等下游任务中表现出更好的性能。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
Coordinate Attention 机制
Coordinate Attention机制可视为一种增强移动网络特征表达能力的计算单元,它接收中间层特征作为输入,并输出增强后大小不变的特征。

Coordinate Attention 模块
Coordinate Attention通过两个关键步骤实现通道关系和长距离关系的编码:坐标信息嵌入(Coordinate Information Embedding)和坐标注意力生成(Coordinate Attention Generation)。
- 坐标信息嵌入
传统的通道注意力通过全局池化来编码全局空间信息,这种方法将全局信息压缩成标量,容易丢失重要的空间细节。为了解决这个问题,本文将全局池化转换为两个一维向量的编码操作。具体而言,通过池化核分别对输入的水平方向和垂直方向特征进行编码,从而得到一对方向感知的特征图。与全局池化相比,这种方法可以在保留一个方向上的空间信息的同时,捕捉另一个方向上的长距离关系,帮助网络更精确地定位目标。
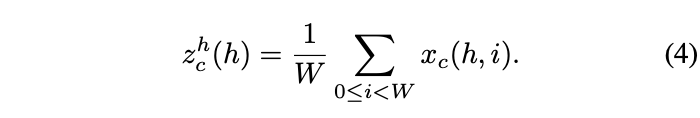
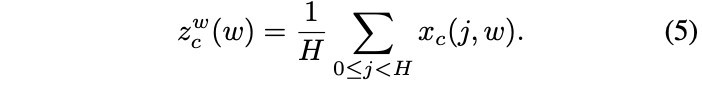
- 坐标注意力生成
为了更有效地利用上述坐标信息,本文设计了配套的坐标注意力生成操作,主要基于三个设计准则:
- 结构简单轻量。
- 充分利用提取的位置信息。
- 高效处理通道间的关系。
首先,将坐标信息嵌入的输出进行拼接,并通过卷积、批量标准化(BN)和非线性激活进行特征转换。接着,将得到的特征分为两部分,分别通过卷积和sigmoid函数进行进一步特征转换,以使其维度与输入一致。最后,将两部分的输出合并成一个权重矩阵,用于计算Coordinate Attention模块的输出。不同于SE模块,Coordinate Attention模块的每个权重都融合了通道间信息、横向空间信息和纵向空间信息,从而帮助网络更准确地定位并识别目标。
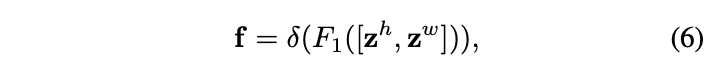
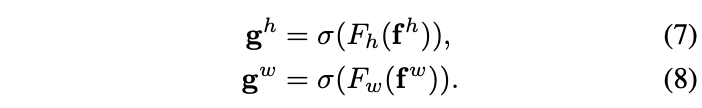
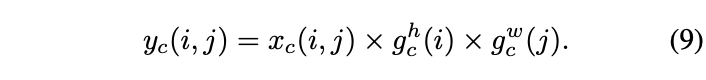
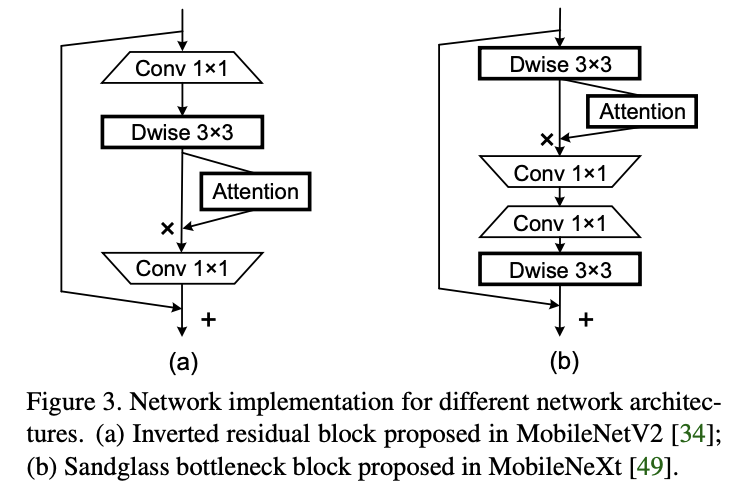
实现
将Coordinate Attention模块应用于MobileNetV2和MobileNeXt上,如图所示的模块结构。
核心代码
import torch
import torch.nn as nn
import math
import torch.nn.functional as Fclass h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def forward(self, x):return self.relu(x + 3) / 6class h_swish(nn.Module):def __init__(self, inplace=True):super(h_swish, self).__init__()self.sigmoid = h_sigmoid(inplace=inplace)def forward(self, x):return x * self.sigmoid(x)class CoordAtt(nn.Module):def __init__(self, inp, oup, reduction=32):super(CoordAtt, self).__init__()self.pool_h = nn.AdaptiveAvgPool2d((None, 1))self.pool_w = nn.AdaptiveAvgPool2d((1, None))mip = max(8, inp // reduction)self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(mip)self.act = h_swish()self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)def forward(self, x):identity = xn,c,h,w = x.size()x_h = self.pool_h(x)x_w = self.pool_w(x).permute(0, 1, 3, 2)y = torch.cat([x_h, x_w], dim=2)y = self.conv1(y)y = self.bn1(y)y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)a_h = self.conv_h(x_h).sigmoid()a_w = self.conv_w(x_w).sigmoid()out = identity * a_w * a_hreturn out
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-CoordAttention.yaml')
# 修改为自己的数据集地址model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='SGD',amp=True,project='runs/train',name='CoordAttention',)