前言
本文介绍了EfficientViT模型中的Cascaded Group Attention(CGA)模块及其在YOLOv11中的应用。CGA受组卷积启发,通过为不同注意力头提供完整特征的分割,解决了传统自注意力机制计算冗余的问题,节省计算量并提高效率。该模块还具有改进注意力多样性、计算效率高和增加模型容量等优势。我们将CGA模块引入YOLOv11,在检测头部分的不同尺度特征图上应用该模块。通过实验训练改进后的模型,有望提升YOLOv11在目标检测任务中的性能。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
@
- 前言
- 介绍
- 摘要
- 文章链接
- 基本原理
- 核心代码
- 实验
- 脚本
- 结果
介绍

摘要
视觉Transformer凭借其卓越的模型能力已在计算机视觉领域取得了显著成就,然而其优异的性能往往伴随着高昂的计算开销,限制了在实时应用场景中的部署。本文提出了一种新型高速视觉Transformer系列模型,命名为EfficientViT。研究发现,现有Transformer模型的推理速度主要受限于内存效率低下的操作,特别是多头自注意力机制(MHSA)中的张量重塑和元素级运算。为此,我们设计了一种采用三明治架构的新型构建模块,即在高效前馈网络(FFN)层之间部署单个内存绑定的MHSA模块,从而在提升内存效率的同时强化通道间通信。此外,研究观察到不同注意力头之间的注意力图存在高度相似性,导致计算冗余。为解决此问题,我们提出了级联分组注意力模块,为各注意力头提供完整特征的不同划分方式,不仅有效降低了计算成本,还增强了注意力机制的多样性。综合实验结果表明,EfficientViT在速度与准确性之间实现了优异的平衡,性能超越现有高效模型。具体而言,EfficientViT-M5在准确率上较MobileNetV3-Large提升1.9%,同时在Nvidia V100 GPU和Intel Xeon CPU上的吞吐量分别提高40.4%和45.2%。与近期高效模型MobileViT-XXS相比,EfficientViT-M2准确率高出1.8%,在GPU/CPU上的运行速度分别提升5.8倍和3.7倍,且在转换为ONNX格式时速度提升7.4倍。相关代码与模型可通过https://github.com/microsoft/Cream/tree/main/EfficientViT获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
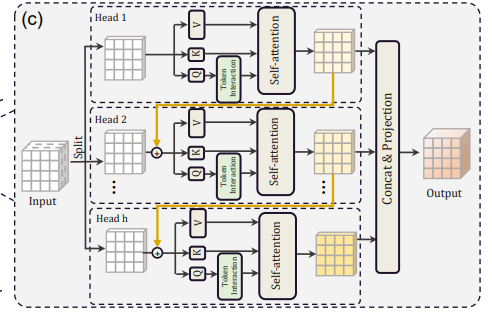
Cascaded Group Attention(CGA)是EfficientViT模型中引入的一种新型注意力模块,其灵感来自高效 CNN 中的组卷积。 在这种方法中,模型向各个头部提供完整特征的分割,因此将注意力计算明确地分解到各个头部。 分割特征而不是向每个头提供完整特征可以节省计算量,并使过程更加高效,并且模型通过鼓励各层学习具有更丰富信息的特征的投影,继续致力于提高准确性和容量。
-
CGA的动机:
- 传统的自注意力机制在Transformer中使用相同的特征集合供所有注意力头使用,导致计算冗余。
- CGA通过为每个注意力头提供不同的输入拆分来解决这个问题,从而增加注意力的多样性并减少计算冗余 。
-
CGA的设计:
- CGA通过在不同的注意力头之间级联输出特征来运行,从而更有效地利用参数并增强模型容量 。
- CGA中每个头中的注意力图计算使用较小的QK通道维度,仅产生轻微的延迟开销,同时增加网络深度 。
-
CGA的优势:
- 改进的注意力多样性:通过为每个头提供不同的特征拆分,CGA增强了注意力图的多样性,有助于更好地学习表示 ]。
- 计算效率:类似于组卷积,CGA通过减少QKV层中的输入和输出通道来节省计算资源和参数 。
- 增加模型容量:CGA的级联设计允许增加网络深度而不引入额外参数,从而提高模型的容量 。
核心代码
import itertools
import torch
import torch.nn as nn
import torch.nn.functional as Fclass CascadedGroupAttention(torch.nn.Module):r""" Cascaded Group Attention.Args:dim (int): 输入通道数。key_dim (int): 查询和键的维度。num_heads (int): 注意力头的数量。attn_ratio (int): 值维度相对于查询维度的倍数。resolution (int): 输入分辨率,对应窗口大小。kernels (List[int]): 查询上深度卷积的内核大小。"""def __init__(self, dim, key_dim, num_heads=8,attn_ratio=4,resolution=14,kernels=[5, 5, 5, 5],):super().__init__()self.num_heads = num_heads # 初始化注意力头数量self.scale = key_dim ** -0.5 # 初始化缩放因子self.key_dim = key_dim # 初始化键的维度self.d = int(attn_ratio * key_dim) # 计算值维度self.attn_ratio = attn_ratio # 初始化注意力比率qkvs = []dws = []for i in range(num_heads):qkvs.append(Conv2d_BN(dim // (num_heads), self.key_dim * 2 + self.d, resolution=resolution)) # 初始化QKV卷积层dws.append(Conv2d_BN(self.key_dim, self.key_dim, kernels[i], 1, kernels[i]//2, groups=self.key_dim, resolution=resolution)) # 初始化深度卷积层self.qkvs = torch.nn.ModuleList(qkvs) # 将QKV卷积层添加到模块列表中self.dws = torch.nn.ModuleList(dws) # 将深度卷积层添加到模块列表中self.proj = torch.nn.Sequential(torch.nn.ReLU(), Conv2d_BN(self.d * num_heads, dim, bn_weight_init=0, resolution=resolution)) # 初始化投影层points = list(itertools.product(range(resolution), range(resolution))) # 生成所有点的坐标N = len(points) # 计算点的数量attention_offsets = {} # 初始化注意力偏移字典idxs = [] # 初始化索引列表for p1 in points:for p2 in points:offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1])) # 计算偏移if offset not in attention_offsets:attention_offsets[offset] = len(attention_offsets) # 添加新的偏移到字典中idxs.append(attention_offsets[offset]) # 添加偏移索引到列表中self.attention_biases = torch.nn.Parameter(torch.zeros(num_heads, len(attention_offsets))) # 初始化注意力偏置参数self.register_buffer('attention_bias_idxs',torch.LongTensor(idxs).view(N, N)) # 注册偏置索引缓冲区@torch.no_grad()def train(self, mode=True):super().train(mode) # 调用父类的train方法if mode and hasattr(self, 'ab'):del self.ab # 如果存在ab属性则删除else:self.ab = self.attention_biases[:, self.attention_bias_idxs] # 初始化ab属性def forward(self, x): # x (B,C,H,W)B, C, H, W = x.shape # 获取输入的形状trainingab = self.attention_biases[:, self.attention_bias_idxs] # 获取训练时的注意力偏置feats_in = x.chunk(len(self.qkvs), dim=1) # 将输入特征按头数量分块feats_out = [] # 初始化输出特征列表feat = feats_in[0] # 获取第一块特征for i, qkv in enumerate(self.qkvs):if i > 0: # 如果不是第一个头feat = feat + feats_in[i] # 将前一个输出添加到输入中feat = qkv(feat) # 通过QKV卷积层q, k, v = feat.view(B, -1, H, W).split([self.key_dim, self.key_dim, self.d], dim=1) # 拆分QKVq = self.dws[i](q) # 通过深度卷积层q, k, v = q.flatten(2), k.flatten(2), v.flatten(2) # 展平QKVattn = ((q.transpose(-2, -1) @ k) * self.scale # 计算注意力+(trainingab[i] if self.training else self.ab[i]) # 添加注意力偏置)attn = attn.softmax(dim=-1) # 对注意力进行softmaxfeat = (v @ attn.transpose(-2, -1)).view(B, self.d, H, W) # 计算输出特征feats_out.append(feat) # 将输出特征添加到列表中x = self.proj(torch.cat(feats_out, 1)) # 将所有输出特征拼接并通过投影层return x # 返回最终输出
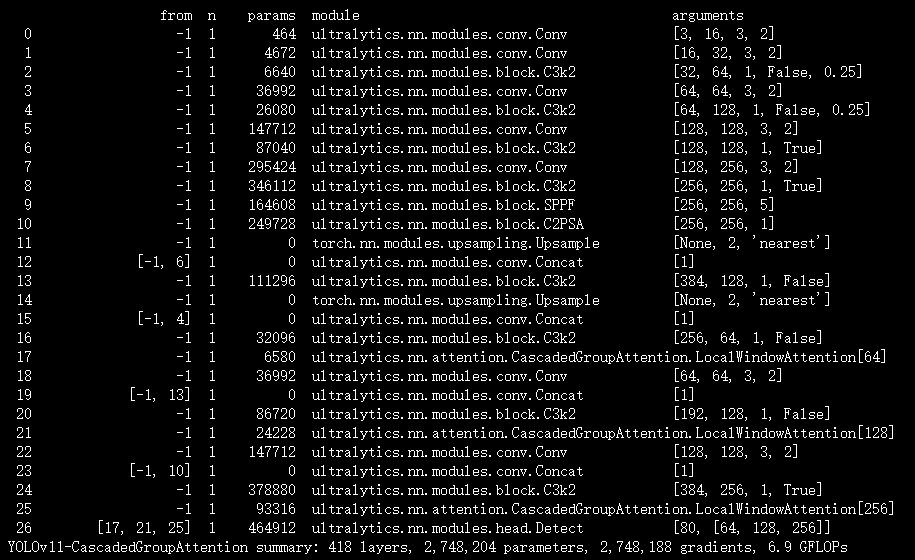
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-CascadedGroupAttention.yaml')
# 修改为自己的数据集地址model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='SGD',amp=True,project='runs/train',name='CascadedGroupAttention',)结果