前言
本文提出了卷积模拟自注意力网络(ESC),并将其与YOLOv11相结合。ESC是针对图像超分辨率任务设计的轻量化网络,核心为ConvAttn模块,通过共享大核与动态核模拟自注意力的长程建模和实例依赖加权。同时,首次将Flash Attention集成到轻量化超分辨率领域,扩大自注意力窗口尺寸,降低延迟和内存占用。我们将C3k2_ESC模块集成进YOLOv11,在相关数据集上进行实验,结果表明,该结合方式在保持Transformer优势的同时,提升了PSNR,降低了计算延迟和内存占用。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
介绍

摘要
本文针对Transformer架构在高效图像超分辨率任务中面临的高计算复杂度挑战展开研究。基于对自注意力机制中层间特征重复性的深入观察,我们提出了一种卷积化的自注意力替代模块——卷积注意力模块(ConvAttn)。该创新模块通过采用单个共享大核卷积与动态核卷积相结合的策略,有效模拟了自注意力机制的长程依赖建模能力和实例特异性加权特性。借助ConvAttn模块,我们在保持Transformer强大表征能力的前提下,显著降低了对传统自注意力机制及其伴随的内存密集型运算的依赖程度。此外,本研究成功攻克了将Flash注意力机制集成到轻量化超分辨率领域的核心技术难题,有效缓解了自注意力机制固有的内存瓶颈问题。我们摒弃了复杂自注意力模块的设计思路,转而通过Flash注意力机制将处理窗口尺寸扩展至32×32,在Urban100×2数据集上实现了峰值信噪比(PSNR)0.31分贝的显著提升,同时将计算延迟和内存占用分别降低16倍和12.2倍。基于上述技术突破,我们构建了名为"卷积模拟自注意力网络(ESC)"的新型模型架构。与HiT-SRF基准模型相比,ESC在Urban100×4数据集上实现了PSNR提升0.27分贝的优异性能,同时计算延迟和内存占用分别降低3.7倍和6.2倍。大量实验验证结果表明,尽管模型中大部分自注意力层被ConvAttn模块替代,ESC网络仍完整保留了Transformer架构的长程建模能力、数据扩展性以及强大的特征表征能力。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
ESC(Emulating Self-attention with Convolution) 是一款针对图像超分辨率(SR)任务设计的轻量化网络,核心为ConvAttn模块(通过共享13×13大核与动态核模拟自注意力的长程建模和实例依赖加权),并首次将Flash Attention集成到轻量化SR中,将自注意力窗口扩大至32×32,同时降低16×延迟和12.2×内存占用。该网络在替换大部分自注意力层的前提下,保留了Transformer的优势,在经典SR任务中,Urban100×4上PSNR达32.68dB(比HiT-SRF提升0.27dB),延迟降低3.7×、内存降低6.2×,且在任意尺度SR、真实世界SR任务中表现优异,支持资源受限设备部署。
(1)ConvAttn模块(核心创新)
- 设计目标:用卷积模拟自注意力的两大核心能力(长程依赖建模、实例依赖加权)
- 关键结构:
- 通道分割:将输入特征按通道拆分为
F_att(16通道,用于长程建模)和F_idt(剩余通道,保留局部特征) - 双卷积机制:
- 共享大核(13×13):全网络共享,负责长程交互,仅作用于
F_att,降低参数冗余 - 动态核(3×3):每层独立生成(通过GAP+1×1卷积+GELU),实现实例依赖加权
- 共享大核(13×13):全网络共享,负责长程交互,仅作用于
- 特征融合:卷积结果与
F_idt拼接后经1×1卷积融合,输出最终特征
- 通道分割:将输入特征按通道拆分为
(2)Flash Attention集成
- 创新应用:首次将Flash Attention引入轻量化SR任务,解决大窗口自注意力的内存问题
- 关键效果:窗口尺寸从16×16扩大至32×32,延迟降低16×、内存降低12.2×(输入288×288×64时)
- 技术细节:通过Flex Attention支持相对位置偏置(RelPos),避免训练不稳定
(3)ESC网络整体架构
| 模块 | 功能描述 |
|---|---|
| 浅层特征提取 | 3×3卷积将LR图像(H×W×3)转换为特征图(H×W×C) |
| 深度特征提取 | N个ESC Block(每个Block含1个自注意力层+M个ConvAttn层)+3×3卷积 |
| 图像级跳跃连接 | 直接处理LR图像,生成跳跃特征F_s,补充细节信息 |
| 上采样器 | 经典SR用亚像素卷积(SPConv),任意尺度SR用LTE,真实世界SR用RealESRGAN上采样器 |
核心代码
class Block(nn.Module):def __init__(self, dim: int, pdim: int, conv_blocks: int, kernel_size: int, window_size: int, num_heads: int, exp_ratio: int, attn_func=None, attn_type: ATTN_TYPE = 'Flex', use_ln: bool = False):super().__init__()self.ln_proj = LayerNorm(dim)self.proj = ConvFFN(dim, 3, 2)self.ln_attn = LayerNorm(dim) self.attn = WindowAttention(dim, window_size, num_heads, attn_func, attn_type)self.lns = nn.ModuleList([LayerNorm(dim) if use_ln else nn.Identity() for _ in range(conv_blocks)])self.pconvs = nn.ModuleList([ConvAttnWrapper(dim, pdim, kernel_size) for _ in range(conv_blocks)])self.convffns = nn.ModuleList([ConvFFN(dim, 3, exp_ratio) for _ in range(conv_blocks)])self.ln_out = LayerNorm(dim)self.conv_out = nn.Conv2d(dim, dim, 3, 1, 1)def forward(self, x: torch.Tensor, plk_filter: torch.Tensor) -> torch.Tensor:skip = xx = self.ln_proj(x)x = self.proj(x)x = x + self.attn(self.ln_attn(x))for ln, pconv, convffn in zip(self.lns, self.pconvs, self.convffns):x = x + pconv(convffn(ln(x)), plk_filter)x = self.conv_out(self.ln_out(x))return x + skip
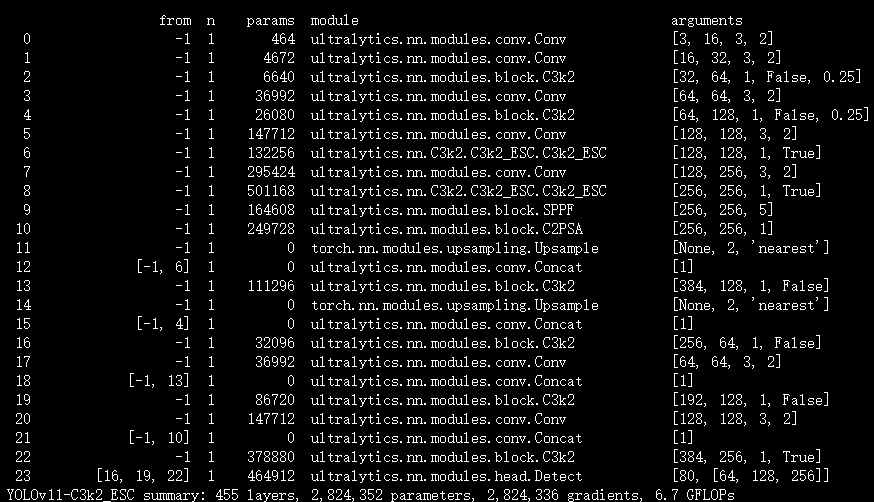
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-C3k2_ESC.yaml')
# 修改为自己的数据集地址model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='SGD',amp=True,project='runs/train',name='C3k2_ESC',)结果