前言
本文介绍了无锚实例分割方法CenterMask及改进骨干网络VoVNetV2,重点阐述了EffectiveSE(eSE)模块及其在YOLOv11中的结合应用。eSE是改进的通道注意力模块,基于SE模块,通过去除维度压缩和简化结构,减少计算复杂性与信息丢失。该模块先对输入特征图全局平均池化,再经全连接层和sigmoid激活函数生成注意力权重,最后应用到特征图。我们将eSE模块集成进YOLOv11,替代部分原有模块。实验表明,eSE模块也提升模型效率和准确率。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
@
- 前言
- 介绍
- 摘要
- 文章链接
- 基本原理
- 背景
- EffectiveSE 的技术原理
- 具体实现
- 优势
- 实验结果
- 核心代码
- 实验
- 脚本
- 结果
介绍

摘要
我们提出了一种简单而高效的无锚实例分割方法,称为CenterMask,它在无锚单阶段目标检测器(FCOS [33])中添加了一个新颖的空间注意力引导掩码(SAG-Mask)分支,类似于Mask R-CNN [9]。在FCOS目标检测器中插入SAG-Mask分支,该分支使用空间注意力图在每个检测框上预测分割掩码,从而有助于关注有用的像素并抑制噪声。我们还提出了改进的骨干网络VoVNetV2,并采用了两种有效策略:(1)残差连接以缓解较大VoVNet [19]的优化问题;(2)有效的挤压-激励(eSE)处理原始SE的通道信息丢失问题。结合SAG-Mask和VoVNetV2,我们设计了针对大模型和小模型的CenterMask和CenterMask-Lite。使用相同的ResNet-101-FPN骨干网络,CenterMask达到了38.3%的AP,超过了所有以前的最先进方法,同时速度更快。CenterMask-Lite在Titan Xp上以超过35fps的速度也大幅超越了最先进的方法。我们希望CenterMask和VoVNetV2可以分别作为实时实例分割和各种视觉任务的骨干网络的坚实基准。代码可在https://github.com/youngwanLEE/CenterMask获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
EffectiveSE (Effective Squeeze-Excitation) 是一种改进的通道注意力模块,其目的是在保持模型性能的同时减少计算复杂性和信息丢失。它基于原始的 Squeeze-Excitation (SE) 模块,但通过一些关键的改进来提高效率。以下是对 EffectiveSE 及其技术原理的详细介绍:
背景
Squeeze-Excitation 网络(SE-Net)是一种通道注意力机制,通过建模特征图通道之间的相互依赖性来增强模型的表现。SE 模块的主要步骤包括:
- Squeeze 操作:对每个通道进行全局平均池化,生成通道描述符。
- Excitation 操作:通过两个全连接层和 ReLU 激活函数来重新计算每个通道的权重。
- Scale 操作:将计算得到的权重应用到原始特征图的每个通道上。
虽然 SE-Net 提高了网络性能,但其两个全连接层的设计带来了额外的计算开销,并且在通道维度上进行了压缩和扩展,可能导致信息丢失。
EffectiveSE 的技术原理
EffectiveSE (eSE) 模块通过简化 SE 模块的结构来提高效率,同时避免信息丢失。具体改进包括:
- 去除维度压缩:原始 SE 模块使用两个全连接层来压缩和扩展通道维度,这可能导致信息丢失。eSE 模块使用单个全连接层,保持通道维度不变,从而避免了这种信息丢失。
- 更高效的计算:通过简化网络结构,减少计算量,提升模型的整体效率。
具体实现
eSE 的具体实现步骤如下:
- 全局平均池化 (Global Average Pooling):对输入特征图 $ X$ 进行全局平均池化,生成一个通道描述符 $F_{gap}(X)$。
- 全连接层 (Fully Connected Layer):通过一个全连接层 $W_C$ 对通道描述符进行线性变换,并应用 sigmoid 激活函数,生成通道注意力权重 $A_{eSE}$:
$$
A_{eSE}(X) = \sigma(W_C(F_{gap}(X)))
$$ - 通道重标定 (Channel Recalibration):将通道注意力权重 $ A_{eSE}$ 应用于输入特征图 $ X的每个通道上,生成加权后的特征图 $X_{refine}$:
$$
X_{refine} = A_{eSE}(X) \otimes X
$$
其中,$\otimes$ 表示元素级别的乘法。
优势
- 减少信息丢失:通过保持通道维度不变,避免了由于维度压缩带来的信息丢失。
- 计算效率高:简化了网络结构,减少了计算量,提高了模型的整体效率。
- 性能提升:在保持或提高模型准确率的同时,显著减少了计算开销。
实验结果
实验表明,应用 eSE 模块的网络(如 VoVNetV2)在各种视觉任务中均表现出色。例如,使用 eSE 模块的 VoVNetV2 相较于原始的 SE 模块和其他骨干网络在速度和准确率上都表现更好。
总体而言,EffectiveSE 通过简化结构和避免信息丢失,提供了一种高效的通道注意力机制,显著提升了模型的性能和计算效率。
核心代码
import torch
from torch import nn as nn
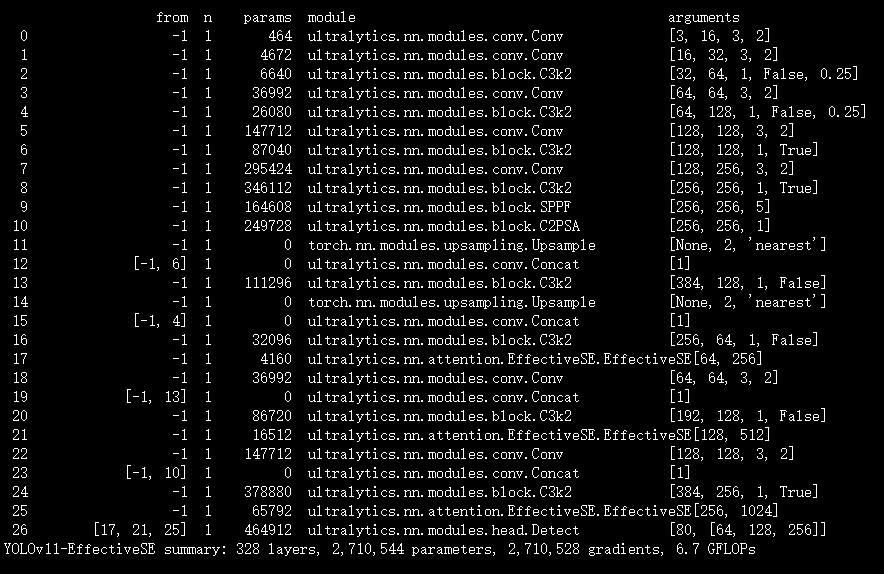
from timm.models.layers.create_act import create_act_layerclass EffectiveSEModule(nn.Module):def __init__(self, channels, add_maxpool=False, gate_layer='hard_sigmoid'):super(EffectiveSEModule, self).__init__()self.add_maxpool = add_maxpoolself.fc = nn.Conv2d(channels, channels, kernel_size=1, padding=0)self.gate = create_act_layer(gate_layer)def forward(self, x):x_se = x.mean((2, 3), keepdim=True)if self.add_maxpool:# experimental codepath, may remove or changex_se = 0.5 * x_se + 0.5 * x.amax((2, 3), keepdim=True)x_se = self.fc(x_se)return x * self.gate(x_se)if __name__ == '__main__':input=torch.randn(50,512,7,7)Ese = EffectiveSEModule(512)output=Ese(input)print(output.shape)实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-EffectiveSE.yaml')
# 修改为自己的数据集地址model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='SGD',amp=True,project='runs/train',name='EffectiveSE',)结果